 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeValue of Information-based Deceptive Path Planning Under Adversarial Interventions
Mar 31, 2025Existing methods for deceptive path planning (DPP) address the problem of designing paths that conceal their true goal from a passive, external observer. Such methods do not apply to problems where the observer has the ability to perform adversarial interventions to impede the path planning agent. In this paper, we propose a novel Markov decision process (MDP)-based model for the DPP problem under adversarial interventions and develop new value of information (VoI) objectives to guide the design of DPP policies. Using the VoI objectives we propose, path planning agents deceive the adversarial observer into choosing suboptimal interventions by selecting trajectories that are of low informational value to the observer. Leveraging connections to the linear programming theory for MDPs, we derive computationally efficient solution methods for synthesizing policies for performing DPP under adversarial interventions. In our experiments, we illustrate the effectiveness of the proposed solution method in achieving deceptiveness under adversarial interventions and demonstrate the superior performance of our approach to both existing DPP methods and conservative path planning approaches on illustrative gridworld problems.
Do LLMs Strategically Reveal, Conceal, and Infer Information? A Theoretical and Empirical Analysis in The Chameleon Game
Jan 31, 2025Large language model-based (LLM-based) agents have become common in settings that include non-cooperative parties. In such settings, agents' decision-making needs to conceal information from their adversaries, reveal information to their cooperators, and infer information to identify the other agents' characteristics. To investigate whether LLMs have these information control and decision-making capabilities, we make LLM agents play the language-based hidden-identity game, The Chameleon. In the game, a group of non-chameleon agents who do not know each other aim to identify the chameleon agent without revealing a secret. The game requires the aforementioned information control capabilities both as a chameleon and a non-chameleon. The empirical results show that while non-chameleon LLM agents identify the chameleon, they fail to conceal the secret from the chameleon, and their winning probability is far from the levels of even trivial strategies. To formally explain this behavior, we give a theoretical analysis for a spectrum of strategies, from concealing to revealing, and provide bounds on the non-chameleons' winning probability. Based on the empirical results and theoretical analysis of different strategies, we deduce that LLM-based non-chameleon agents reveal excessive information to agents of unknown identities. Our results point to a weakness of contemporary LLMs, including GPT-4, GPT-4o, Gemini 1.5, and Claude 3.5 Sonnet, in strategic interactions.
Policies with Sparse Inter-Agent Dependencies in Dynamic Games: A Dynamic Programming Approach
Oct 21, 2024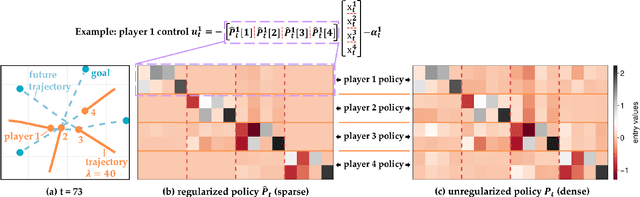
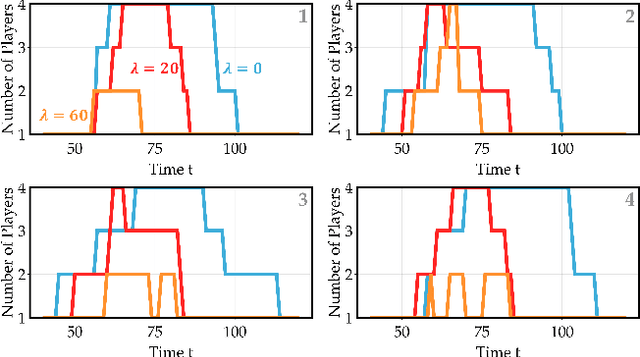
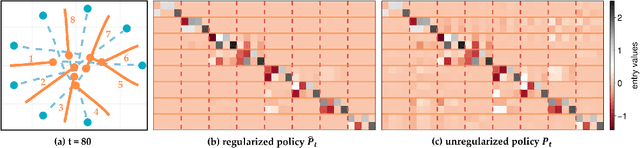
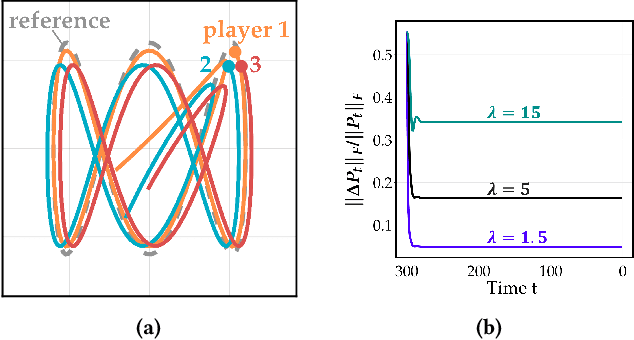
Common feedback strategies in multi-agent dynamic games require all players' state information to compute control strategies. However, in real-world scenarios, sensing and communication limitations between agents make full state feedback expensive or impractical, and such strategies can become fragile when state information from other agents is inaccurate. To this end, we propose a regularized dynamic programming approach for finding sparse feedback policies that selectively depend on the states of a subset of agents in dynamic games. The proposed approach solves convex adaptive group Lasso problems to compute sparse policies approximating Nash equilibrium solutions. We prove the regularized solutions' asymptotic convergence to a neighborhood of Nash equilibrium policies in linear-quadratic (LQ) games. We extend the proposed approach to general non-LQ games via an iterative algorithm. Empirical results in multi-robot interaction scenarios show that the proposed approach effectively computes feedback policies with varying sparsity levels. When agents have noisy observations of other agents' states, simulation results indicate that the proposed regularized policies consistently achieve lower costs than standard Nash equilibrium policies by up to 77% for all interacting agents whose costs are coupled with other agents' states.
Autonomous Negotiation Using Comparison-Based Gradient Estimation
Aug 20, 2024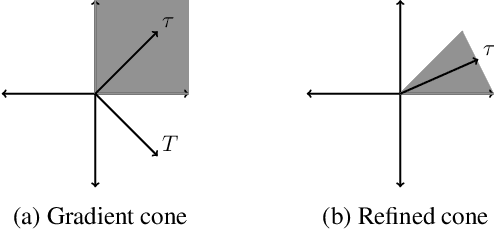

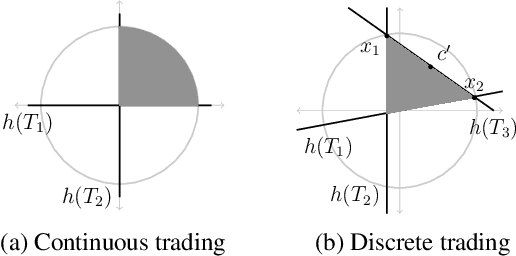

Negotiation is useful for resolving conflicts in multi-agent systems. We explore autonomous negotiation in a setting where two self-interested rational agents sequentially trade items from a finite set of categories. Each agent has a utility function that depends on the amount of items it possesses in each category. The offering agent makes trade offers to improve its utility without knowing the responding agent's utility function, and the responding agent accepts offers that improve its utility. We present a comparison-based algorithm for the offering agent that generates offers through previous acceptance or rejection responses without extensive information sharing. The algorithm estimates the responding agent's gradient by leveraging the rationality assumption and rejected offers to prune the space of potential gradients. After the algorithm makes a finite number of consecutively rejected offers, the responding agent is at a near-optimal state, or the agents' preferences are closely aligned. Additionally, we facilitate negotiations with humans by representing natural language feedback as comparisons that can be integrated into the proposed algorithm. We compare the proposed algorithm against random search baselines in integer and fractional trading scenarios and show that it improves the societal benefit with fewer offers.
Formal Methods for Autonomous Systems
Nov 02, 2023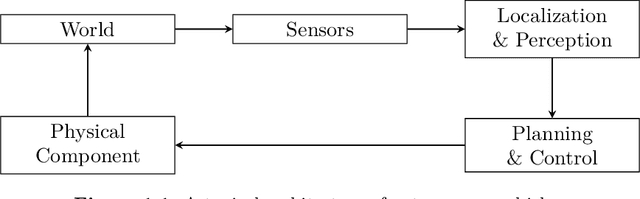
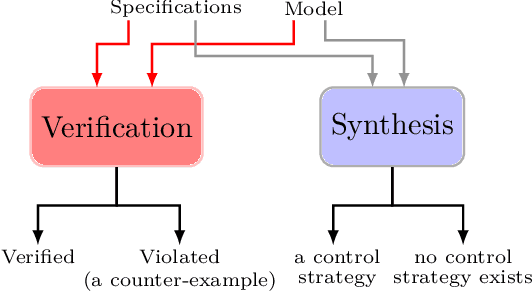
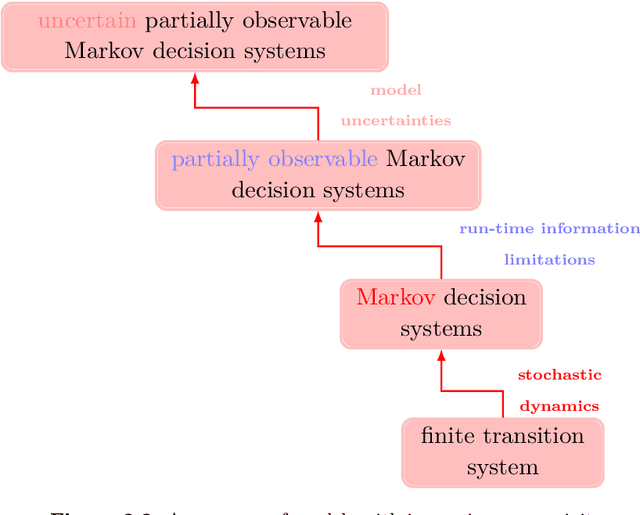
Formal methods refer to rigorous, mathematical approaches to system development and have played a key role in establishing the correctness of safety-critical systems. The main building blocks of formal methods are models and specifications, which are analogous to behaviors and requirements in system design and give us the means to verify and synthesize system behaviors with formal guarantees. This monograph provides a survey of the current state of the art on applications of formal methods in the autonomous systems domain. We consider correct-by-construction synthesis under various formulations, including closed systems, reactive, and probabilistic settings. Beyond synthesizing systems in known environments, we address the concept of uncertainty and bound the behavior of systems that employ learning using formal methods. Further, we examine the synthesis of systems with monitoring, a mitigation technique for ensuring that once a system deviates from expected behavior, it knows a way of returning to normalcy. We also show how to overcome some limitations of formal methods themselves with learning. We conclude with future directions for formal methods in reinforcement learning, uncertainty, privacy, explainability of formal methods, and regulation and certification.
Encouraging Inferable Behavior for Autonomy: Repeated Bimatrix Stackelberg Games with Observations
Sep 30, 2023When interacting with other non-competitive decision-making agents, it is critical for an autonomous agent to have inferable behavior: Their actions must convey their intention and strategy. For example, an autonomous car's strategy must be inferable by the pedestrians interacting with the car. We model the inferability problem using a repeated bimatrix Stackelberg game with observations where a leader and a follower repeatedly interact. During the interactions, the leader uses a fixed, potentially mixed strategy. The follower, on the other hand, does not know the leader's strategy and dynamically reacts based on observations that are the leader's previous actions. In the setting with observations, the leader may suffer from an inferability loss, i.e., the performance compared to the setting where the follower has perfect information of the leader's strategy. We show that the inferability loss is upper-bounded by a function of the number of interactions and the stochasticity level of the leader's strategy, encouraging the use of inferable strategies with lower stochasticity levels. As a converse result, we also provide a game where the required number of interactions is lower bounded by a function of the desired inferability loss.
On the Sample Complexity of Vanilla Model-Based Offline Reinforcement Learning with Dependent Samples
Mar 07, 2023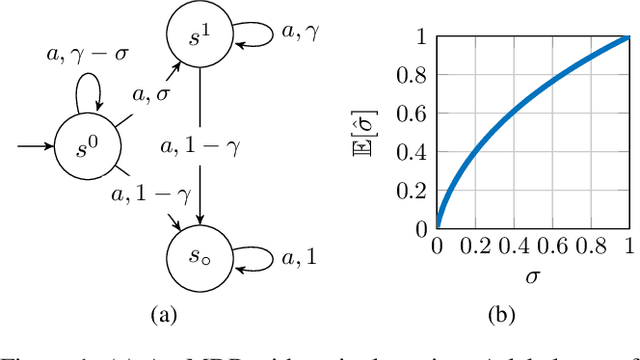
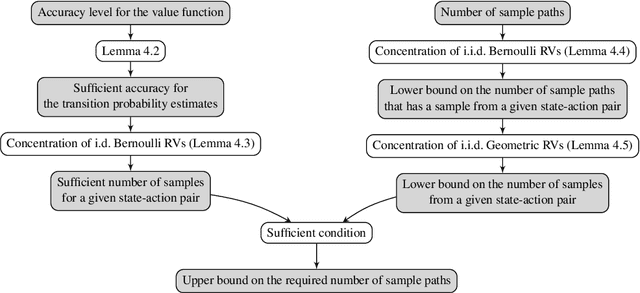
Offline reinforcement learning (offline RL) considers problems where learning is performed using only previously collected samples and is helpful for the settings in which collecting new data is costly or risky. In model-based offline RL, the learner performs estimation (or optimization) using a model constructed according to the empirical transition frequencies. We analyze the sample complexity of vanilla model-based offline RL with dependent samples in the infinite-horizon discounted-reward setting. In our setting, the samples obey the dynamics of the Markov decision process and, consequently, may have interdependencies. Under no assumption of independent samples, we provide a high-probability, polynomial sample complexity bound for vanilla model-based off-policy evaluation that requires partial or uniform coverage. We extend this result to the off-policy optimization under uniform coverage. As a comparison to the model-based approach, we analyze the sample complexity of off-policy evaluation with vanilla importance sampling in the infinite-horizon setting. Finally, we provide an estimator that outperforms the sample-mean estimator for almost deterministic dynamics that are prevalent in reinforcement learning.
Differential Privacy in Cooperative Multiagent Planning
Jan 20, 2023



Privacy-aware multiagent systems must protect agents' sensitive data while simultaneously ensuring that agents accomplish their shared objectives. Towards this goal, we propose a framework to privatize inter-agent communications in cooperative multiagent decision-making problems. We study sequential decision-making problems formulated as cooperative Markov games with reach-avoid objectives. We apply a differential privacy mechanism to privatize agents' communicated symbolic state trajectories, and then we analyze tradeoffs between the strength of privacy and the team's performance. For a given level of privacy, this tradeoff is shown to depend critically upon the total correlation among agents' state-action processes. We synthesize policies that are robust to privacy by reducing the value of the total correlation. Numerical experiments demonstrate that the team's performance under these policies decreases by only 3 percent when comparing private versus non-private implementations of communication. By contrast, the team's performance decreases by roughly 86 percent when using baseline policies that ignore total correlation and only optimize team performance.
Deceptive Planning for Resource Allocation
Jun 02, 2022
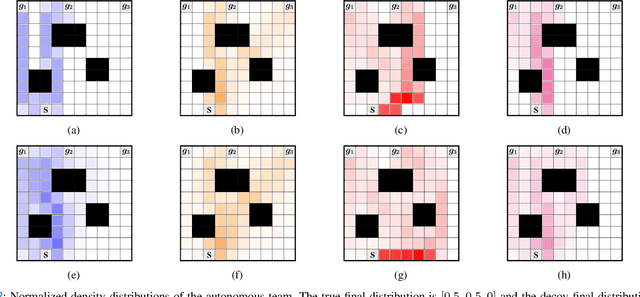
We consider a team of autonomous agents that navigate in an adversarial environment and aim to achieve a task by allocating their resources over a set of target locations. The adversaries in the environment observe the autonomous team's behavior to infer their objective and counter-allocate their own resources to the target locations. In this setting, we develop strategies for controlling the density of the autonomous team so that they can deceive the adversaries regarding their objective while achieving the desired final resource allocation. We first develop a prediction algorithm, based on the principle of maximum entropy, to express the team's behavior expected by the adversaries. Then, by measuring the deceptiveness via Kullback-Leibler divergence, we develop convex optimization-based planning algorithms that deceives adversaries by either exaggerating the behavior towards a decoy allocation strategy or creating ambiguity regarding the final allocation strategy. Finally, we illustrate the performance of the proposed algorithms through numerical simulations.
Planning Not to Talk: Multiagent Systems that are Robust to Communication Loss
Jan 17, 2022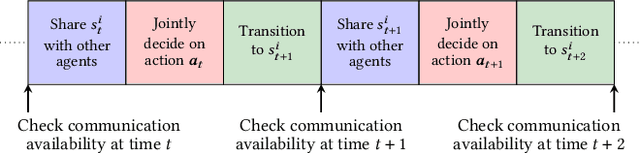

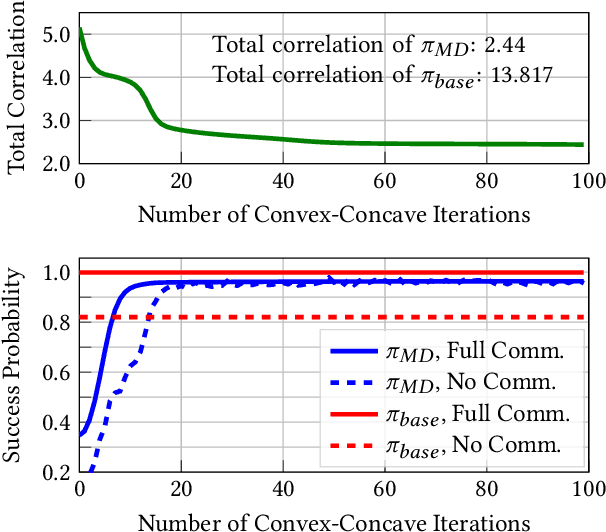
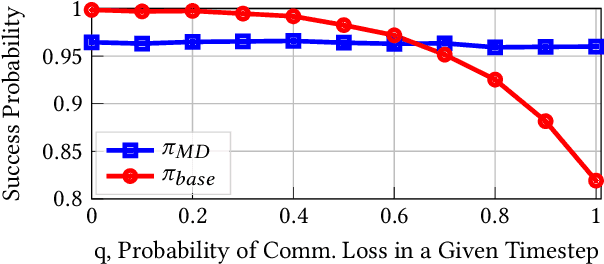
In a cooperative multiagent system, a collection of agents executes a joint policy in order to achieve some common objective. The successful deployment of such systems hinges on the availability of reliable inter-agent communication. However, many sources of potential disruption to communication exist in practice, such as radio interference, hardware failure, and adversarial attacks. In this work, we develop joint policies for cooperative multiagent systems that are robust to potential losses in communication. More specifically, we develop joint policies for cooperative Markov games with reach-avoid objectives. First, we propose an algorithm for the decentralized execution of joint policies during periods of communication loss. Next, we use the total correlation of the state-action process induced by a joint policy as a measure of the intrinsic dependencies between the agents. We then use this measure to lower-bound the performance of a joint policy when communication is lost. Finally, we present an algorithm that maximizes a proxy to this lower bound in order to synthesize minimum-dependency joint policies that are robust to communication loss. Numerical experiments show that the proposed minimum-dependency policies require minimal coordination between the agents while incurring little to no loss in performance; the total correlation value of the synthesized policy is one fifth of the total correlation value of the baseline policy which does not take potential communication losses into account. As a result, the performance of the minimum-dependency policies remains consistently high regardless of whether or not communication is available. By contrast, the performance of the baseline policy decreases by twenty percent when communication is lost.