 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFormal Methods for Autonomous Systems
Nov 02, 2023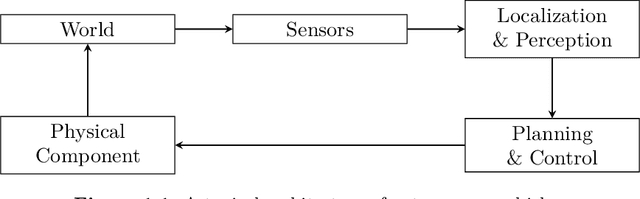
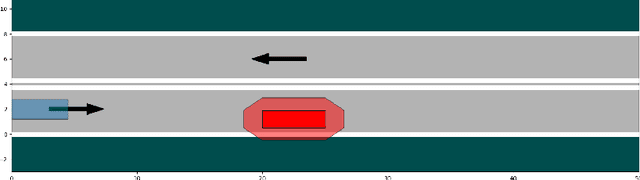
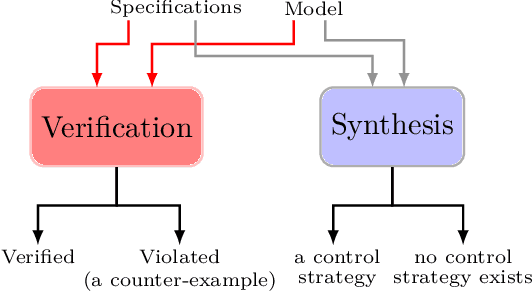
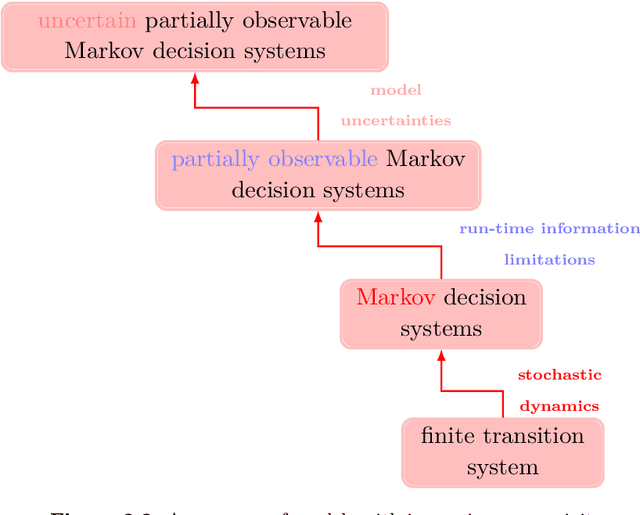
Formal methods refer to rigorous, mathematical approaches to system development and have played a key role in establishing the correctness of safety-critical systems. The main building blocks of formal methods are models and specifications, which are analogous to behaviors and requirements in system design and give us the means to verify and synthesize system behaviors with formal guarantees. This monograph provides a survey of the current state of the art on applications of formal methods in the autonomous systems domain. We consider correct-by-construction synthesis under various formulations, including closed systems, reactive, and probabilistic settings. Beyond synthesizing systems in known environments, we address the concept of uncertainty and bound the behavior of systems that employ learning using formal methods. Further, we examine the synthesis of systems with monitoring, a mitigation technique for ensuring that once a system deviates from expected behavior, it knows a way of returning to normalcy. We also show how to overcome some limitations of formal methods themselves with learning. We conclude with future directions for formal methods in reinforcement learning, uncertainty, privacy, explainability of formal methods, and regulation and certification.
Additive Logistic Mechanism for Privacy-Preserving Self-Supervised Learning
May 25, 2022

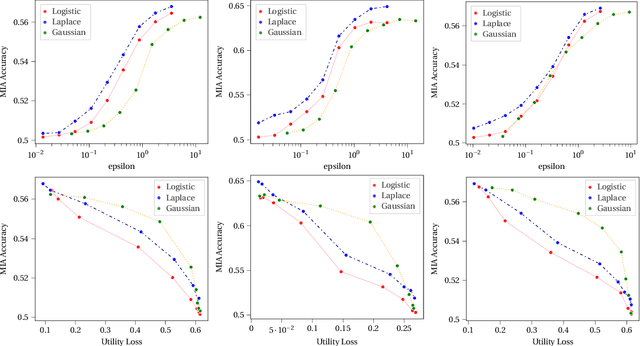
We study the privacy risks that are associated with training a neural network's weights with self-supervised learning algorithms. Through empirical evidence, we show that the fine-tuning stage, in which the network weights are updated with an informative and often private dataset, is vulnerable to privacy attacks. To address the vulnerabilities, we design a post-training privacy-protection algorithm that adds noise to the fine-tuned weights and propose a novel differential privacy mechanism that samples noise from the logistic distribution. Compared to the two conventional additive noise mechanisms, namely the Laplace and the Gaussian mechanisms, the proposed mechanism uses a bell-shaped distribution that resembles the distribution of the Gaussian mechanism, and it satisfies pure $\epsilon$-differential privacy similar to the Laplace mechanism. We apply membership inference attacks on both unprotected and protected models to quantify the trade-off between the models' privacy and performance. We show that the proposed protection algorithm can effectively reduce the attack accuracy to roughly 50\%-equivalent to random guessing-while maintaining a performance loss below 5\%.
On The Vulnerability of Recurrent Neural Networks to Membership Inference Attacks
Oct 06, 2021



We study the privacy implications of deploying recurrent neural networks in machine learning. We consider membership inference attacks (MIAs) in which an attacker aims to infer whether a given data record has been used in the training of a learning agent. Using existing MIAs that target feed-forward neural networks, we empirically demonstrate that the attack accuracy wanes for data records used earlier in the training history. Alternatively, recurrent networks are specifically designed to better remember their past experience; hence, they are likely to be more vulnerable to MIAs than their feed-forward counterparts. We develop a pair of MIA layouts for two primary applications of recurrent networks, namely, deep reinforcement learning and sequence-to-sequence tasks. We use the first attack to provide empirical evidence that recurrent networks are indeed more vulnerable to MIAs than feed-forward networks with the same performance level. We use the second attack to showcase the differences between the effects of overtraining recurrent and feed-forward networks on the accuracy of their respective MIAs. Finally, we deploy a differential privacy mechanism to resolve the privacy vulnerability that the MIAs exploit. For both attack layouts, the privacy mechanism degrades the attack accuracy from above 80% to 50%, which is equal to guessing the data membership uniformly at random, while trading off less than 10% utility.
Privacy-Preserving Teacher-Student Deep Reinforcement Learning
Feb 18, 2021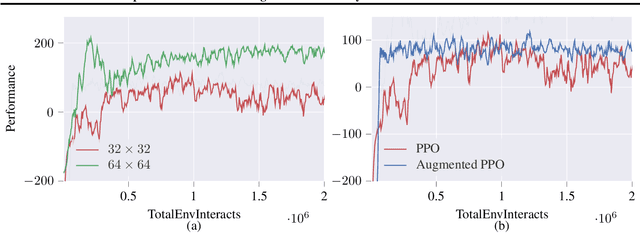
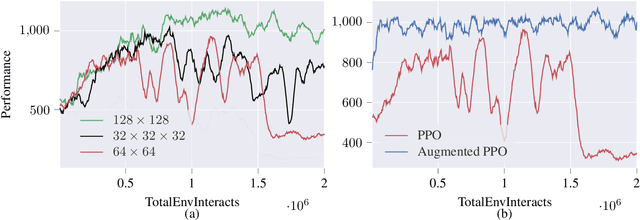
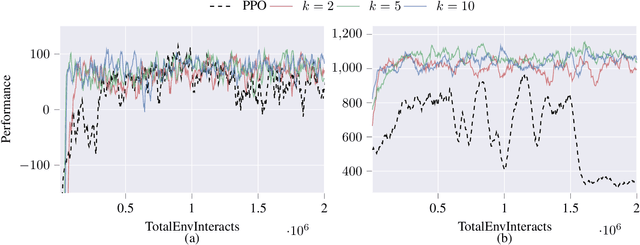
Deep reinforcement learning agents may learn complex tasks more efficiently when they coordinate with one another. We consider a teacher-student coordination scheme wherein an agent may ask another agent for demonstrations. Despite the benefits of sharing demonstrations, however, potential adversaries may obtain sensitive information belonging to the teacher by observing the demonstrations. In particular, deep reinforcement learning algorithms are known to be vulnerable to membership attacks, which make accurate inferences about the membership of the entries of training datasets. Therefore, there is a need to safeguard the teacher against such privacy threats. We fix the teacher's policy as the context of the demonstrations, which allows for different internal models across the student and the teacher, and contrasts the existing methods. We make the following two contributions. (i) We develop a differentially private mechanism that protects the privacy of the teacher's training dataset. (ii) We propose a proximal policy-optimization objective that enables the student to benefit from the demonstrations despite the perturbations of the privacy mechanism. We empirically show that the algorithm improves the student's learning upon convergence rate and utility. Specifically, compared with an agent who learns the same task on its own, we observe that the student's policy converges faster, and the converging policy accumulates higher rewards more robustly.