 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReduce, Reuse, Recycle: Categories for Compositional Reinforcement Learning
Aug 23, 2024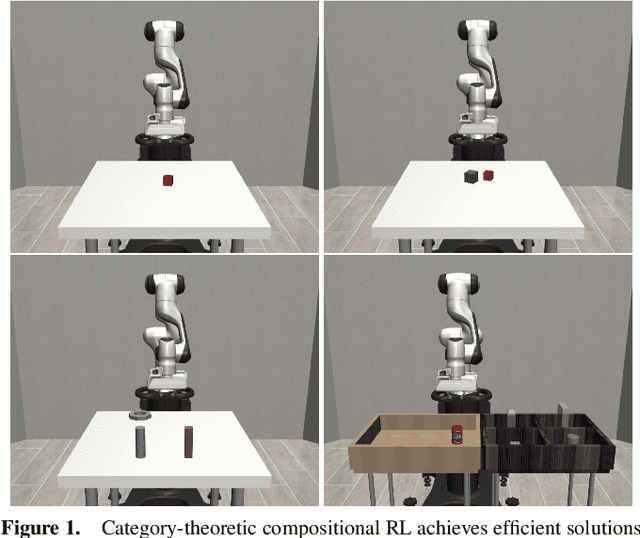
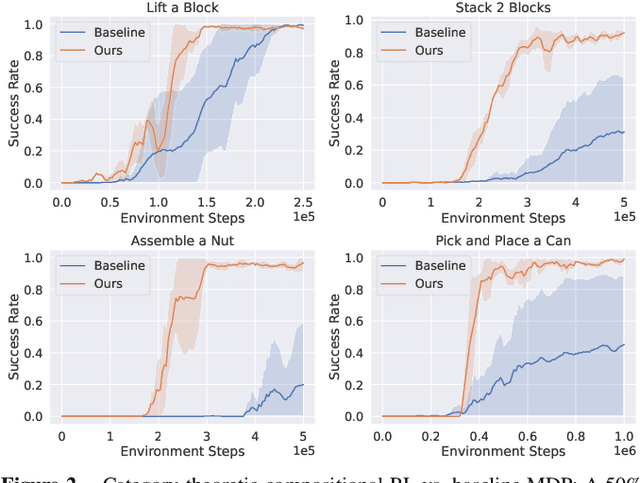
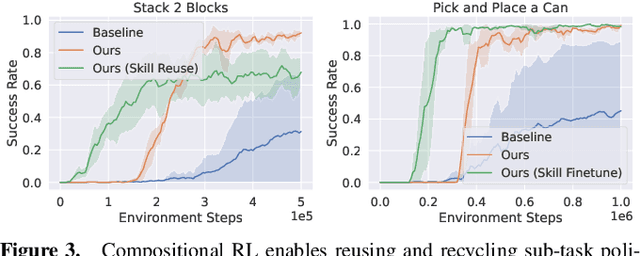
In reinforcement learning, conducting task composition by forming cohesive, executable sequences from multiple tasks remains challenging. However, the ability to (de)compose tasks is a linchpin in developing robotic systems capable of learning complex behaviors. Yet, compositional reinforcement learning is beset with difficulties, including the high dimensionality of the problem space, scarcity of rewards, and absence of system robustness after task composition. To surmount these challenges, we view task composition through the prism of category theory -- a mathematical discipline exploring structures and their compositional relationships. The categorical properties of Markov decision processes untangle complex tasks into manageable sub-tasks, allowing for strategical reduction of dimensionality, facilitating more tractable reward structures, and bolstering system robustness. Experimental results support the categorical theory of reinforcement learning by enabling skill reduction, reuse, and recycling when learning complex robotic arm tasks.
Negotiating Control: Neurosymbolic Variable Autonomy
Jul 23, 2024Variable autonomy equips a system, such as a robot, with mixed initiatives such that it can adjust its independence level based on the task's complexity and the surrounding environment. Variable autonomy solves two main problems in robotic planning: the first is the problem of humans being unable to keep focus in monitoring and intervening during robotic tasks without appropriate human factor indicators, and the second is achieving mission success in unforeseen and uncertain environments in the face of static reward structures. An open problem in variable autonomy is developing robust methods to dynamically balance autonomy and human intervention in real-time, ensuring optimal performance and safety in unpredictable and evolving environments. We posit that addressing unpredictable and evolving environments through an addition of rule-based symbolic logic has the potential to make autonomy adjustments more contextually reliable and adding feedback to reinforcement learning through data from mixed-initiative control further increases efficacy and safety of autonomous behaviour.
Formal Methods for Autonomous Systems
Nov 02, 2023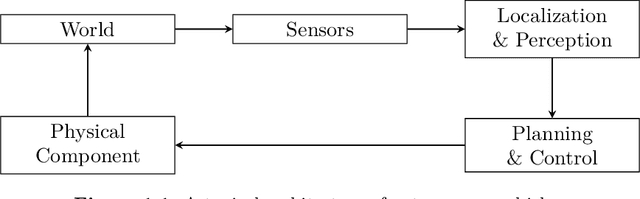
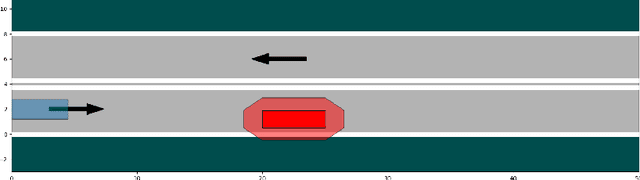
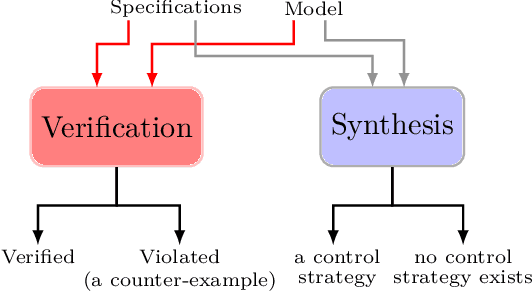
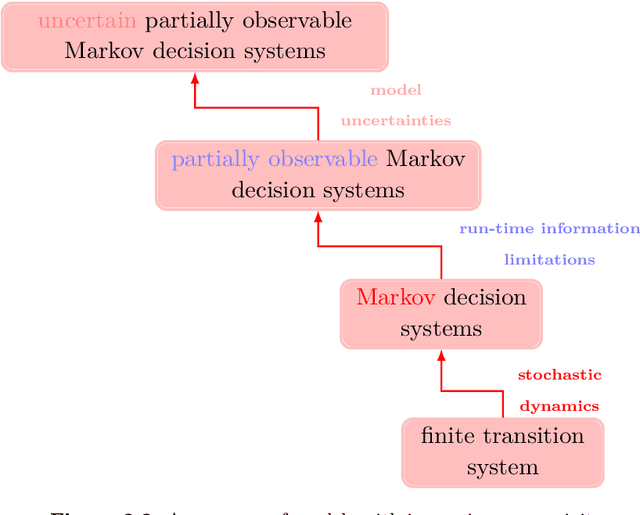
Formal methods refer to rigorous, mathematical approaches to system development and have played a key role in establishing the correctness of safety-critical systems. The main building blocks of formal methods are models and specifications, which are analogous to behaviors and requirements in system design and give us the means to verify and synthesize system behaviors with formal guarantees. This monograph provides a survey of the current state of the art on applications of formal methods in the autonomous systems domain. We consider correct-by-construction synthesis under various formulations, including closed systems, reactive, and probabilistic settings. Beyond synthesizing systems in known environments, we address the concept of uncertainty and bound the behavior of systems that employ learning using formal methods. Further, we examine the synthesis of systems with monitoring, a mitigation technique for ensuring that once a system deviates from expected behavior, it knows a way of returning to normalcy. We also show how to overcome some limitations of formal methods themselves with learning. We conclude with future directions for formal methods in reinforcement learning, uncertainty, privacy, explainability of formal methods, and regulation and certification.
Categorical semantics of compositional reinforcement learning
Aug 29, 2022
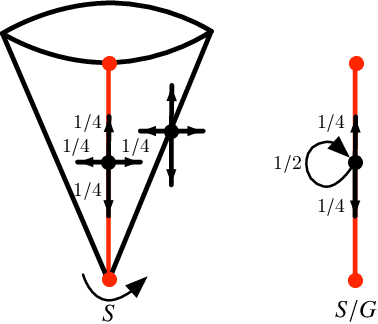
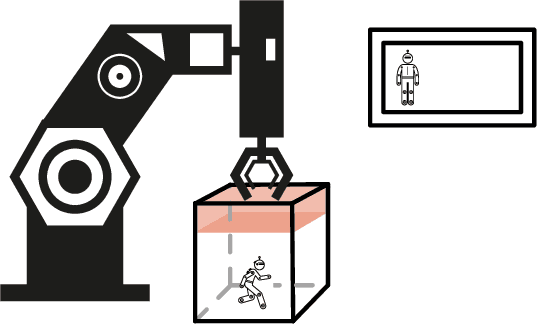
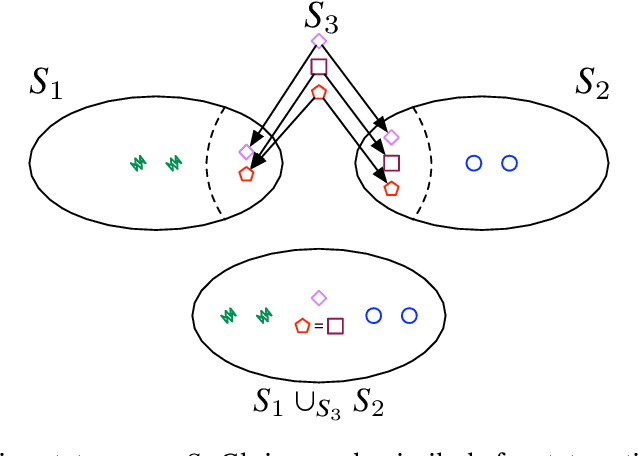
Reinforcement learning (RL) often requires decomposing a problem into subtasks and composing learned behaviors on these tasks. Compositionality in RL has the potential to create modular subtask units that interface with other system capabilities. However, generating compositional models requires the characterization of minimal assumptions for the robustness of the compositional feature. We develop a framework for a \emph{compositional theory} of RL using a categorical point of view. Given the categorical representation of compositionality, we investigate sufficient conditions under which learning-by-parts results in the same optimal policy as learning on the whole. In particular, our approach introduces a category $\mathsf{MDP}$, whose objects are Markov decision processes (MDPs) acting as models of tasks. We show that $\mathsf{MDP}$ admits natural compositional operations, such as certain fiber products and pushouts. These operations make explicit compositional phenomena in RL and unify existing constructions, such as puncturing hazardous states in composite MDPs and incorporating state-action symmetry. We also model sequential task completion by introducing the language of zig-zag diagrams that is an immediate application of the pushout operation in $\mathsf{MDP}$.
Dynamic Certification for Autonomous Systems
Mar 21, 2022
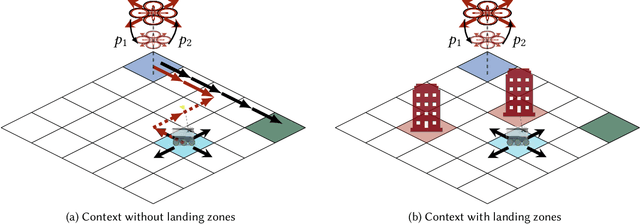
Autonomous systems are often deployed in complex sociotechnical environments, such as public roads, where they must behave safely and securely. Unlike many traditionally engineered systems, autonomous systems are expected to behave predictably in varying "open world" environmental contexts that cannot be fully specified formally. As a result, assurance about autonomous systems requires us to develop new certification methods and mathematical tools that can bound the uncertainty engendered by these diverse deployment scenarios, rather than relying on static tools.