 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRDEx-CMOP: Feasibility-Aware Indicator-Guided Differential Evolution for Fixed-Budget Constrained Multiobjective Optimization
Apr 04, 2026Constrained multiobjective optimisation requires fast feasibility attainment together with stable convergence and diversity preservation under strict evaluation budgets. This report documents RDEx-CMOP, the differential evolution variant used in the IEEE CEC 2025 numerical optimisation competition (C06 special session) constrained multiobjective track. RDEx-CMOP integrates an ε-level feasibility schedule, a SPEA2-style indicator-driven fitness assignment, and a fitness-oriented current-to-pbest/1 mutation operator. We evaluate RDEx-CMOP on the official CEC 2025 CMOP benchmark using the median-target U-score framework and the released trace data. Experimental results show that RDEx-CMOP achieves the highest total score and the best overall average rank among all released comparison algorithms, with strong target-attainment behaviour and near-zero final violation on most problems.
RDEx-SOP: Exploitation-Biased Reconstructed Differential Evolution for Fixed-Budget Bound-Constrained Single-Objective Optimization
Mar 28, 2026Bound-constrained single-objective numerical optimisation remains a key benchmark for assessing the robustness and efficiency of evolutionary algorithms. This report documents RDEx-SOP, an exploitation-biased success-history differential evolution variant used in the IEEE CEC 2025 numerical optimisation competition (C06 special session). RDEx-SOP combines success-history parameter adaptation, an exploitation-biased hybrid branch, and lightweight local perturbations to balance fast convergence and final solution quality under a strict evaluation budget. We evaluate RDEx-SOP on the official CEC 2025 SOP benchmark with the U-score framework (Speed and Accuracy categories). Experimental results show that RDEx-SOP achieves strong overall performance and statistically competitive final outcomes across the 29 benchmark functions.
RDEx-MOP: Indicator-Guided Reconstructed Differential Evolution for Fixed-Budget Multiobjective Optimization
Mar 28, 2026Multiobjective optimisation in the CEC 2025 MOP track is evaluated not only by final IGD values but also by how quickly an algorithm reaches the target region under a fixed evaluation budget. This report documents RDEx-MOP, the reconstructed differential evolution variant used in the IEEE CEC 2025 numerical optimisation competition (C06 special session) bound-constrained multiobjective track. RDEx-MOP integrates indicator-based environmental selection, a niche-maintained Pareto-candidate set, and complementary differential evolution operators for exploration and exploitation. We evaluate RDEx-MOP on the official CEC 2025 MOP benchmark using the released checkpoint traces and the median-target U-score framework. Experimental results show that RDEx-MOP achieves the highest total score and the best average rank among all released comparison algorithms, including the earlier RDEx baseline.
RDEx-CSOP: Feasibility-Aware Reconstructed Differential Evolution with Adaptive epsilon-Constraint Ranking
Mar 28, 2026Constrained single-objective numerical optimisation requires both feasibility maintenance and strong objective-value convergence under limited evaluation budgets. This report documents RDEx-CSOP, a constrained differential evolution variant used in the IEEE CEC 2025 numerical optimisation competition (C06 special session). RDEx-CSOP combines success-history parameter adaptation with an exploitation-biased hybrid search and an ε-constraint handling mechanism with a time-varying threshold. We evaluate RDEx-CSOP on the official CEC 2025 CSOP benchmark using the U-score framework (Speed, Accuracy, and Constraint categories). The results show that RDEx-CSOP achieves the highest total score and the best average rank among all released comparison algorithms, mainly through strong speed and competitive constraint-handling performance across the 28 benchmark functions.
Learning Human Perception Dynamics for Informative Robot Communication
Feb 03, 2025



Human-robot cooperative navigation is challenging in environments with incomplete information. We introduce CoNav-Maze, a simulated robotics environment where a robot navigates using local perception while a human operator provides guidance based on an inaccurate map. The robot can share its camera views to improve the operator's understanding of the environment. To enable efficient human-robot cooperation, we propose Information Gain Monte Carlo Tree Search (IG-MCTS), an online planning algorithm that balances autonomous movement and informative communication. Central to IG-MCTS is a neural human perception dynamics model that estimates how humans distill information from robot communications. We collect a dataset through a crowdsourced mapping task in CoNav-Maze and train this model using a fully convolutional architecture with data augmentation. User studies show that IG-MCTS outperforms teleoperation and instruction-following baselines, achieving comparable task performance with significantly less communication and lower human cognitive load, as evidenced by eye-tracking metrics.
Dense Dynamics-Aware Reward Synthesis: Integrating Prior Experience with Demonstrations
Dec 02, 2024



Many continuous control problems can be formulated as sparse-reward reinforcement learning (RL) tasks. In principle, online RL methods can automatically explore the state space to solve each new task. However, discovering sequences of actions that lead to a non-zero reward becomes exponentially more difficult as the task horizon increases. Manually shaping rewards can accelerate learning for a fixed task, but it is an arduous process that must be repeated for each new environment. We introduce a systematic reward-shaping framework that distills the information contained in 1) a task-agnostic prior data set and 2) a small number of task-specific expert demonstrations, and then uses these priors to synthesize dense dynamics-aware rewards for the given task. This supervision substantially accelerates learning in our experiments, and we provide analysis demonstrating how the approach can effectively guide online learning agents to faraway goals.
Human-Agent Coordination in Games under Incomplete Information via Multi-Step Intent
Oct 23, 2024Strategic coordination between autonomous agents and human partners under incomplete information can be modeled as turn-based cooperative games. We extend a turn-based game under incomplete information, the shared-control game, to allow players to take multiple actions per turn rather than a single action. The extension enables the use of multi-step intent, which we hypothesize will improve performance in long-horizon tasks. To synthesize cooperative policies for the agent in this extended game, we propose an approach featuring a memory module for a running probabilistic belief of the environment dynamics and an online planning algorithm called IntentMCTS. This algorithm strategically selects the next action by leveraging any communicated multi-step intent via reward augmentation while considering the current belief. Agent-to-agent simulations in the Gnomes at Night testbed demonstrate that IntentMCTS requires fewer steps and control switches than baseline methods. A human-agent user study corroborates these findings, showing an 18.52% higher success rate compared to the heuristic baseline and a 5.56% improvement over the single-step prior work. Participants also report lower cognitive load, frustration, and higher satisfaction with the IntentMCTS agent partner.
PEERNet: An End-to-End Profiling Tool for Real-Time Networked Robotic Systems
Sep 09, 2024Networked robotic systems balance compute, power, and latency constraints in applications such as self-driving vehicles, drone swarms, and teleoperated surgery. A core problem in this domain is deciding when to offload a computationally expensive task to the cloud, a remote server, at the cost of communication latency. Task offloading algorithms often rely on precise knowledge of system-specific performance metrics, such as sensor data rates, network bandwidth, and machine learning model latency. While these metrics can be modeled during system design, uncertainties in connection quality, server load, and hardware conditions introduce real-time performance variations, hindering overall performance. We introduce PEERNet, an end-to-end and real-time profiling tool for cloud robotics. PEERNet enables performance monitoring on heterogeneous hardware through targeted yet adaptive profiling of system components such as sensors, networks, deep-learning pipelines, and devices. We showcase PEERNet's capabilities through networked robotics tasks, such as image-based teleoperation of a Franka Emika Panda arm and querying vision language models using an Nvidia Jetson Orin. PEERNet reveals non-intuitive behavior in robotic systems, such as asymmetric network transmission and bimodal language model output. Our evaluation underscores the effectiveness and importance of benchmarking in networked robotics, demonstrating PEERNet's adaptability. Our code is open-source and available at github.com/UTAustin-SwarmLab/PEERNet.
Reduce, Reuse, Recycle: Categories for Compositional Reinforcement Learning
Aug 23, 2024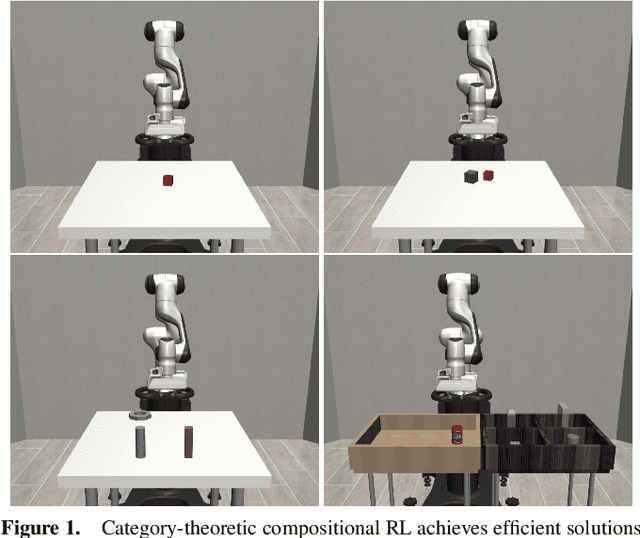
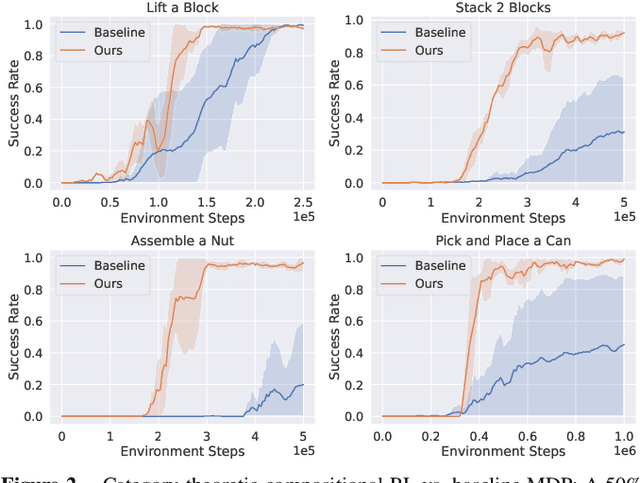
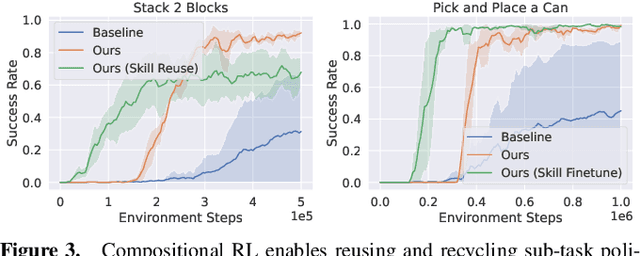
In reinforcement learning, conducting task composition by forming cohesive, executable sequences from multiple tasks remains challenging. However, the ability to (de)compose tasks is a linchpin in developing robotic systems capable of learning complex behaviors. Yet, compositional reinforcement learning is beset with difficulties, including the high dimensionality of the problem space, scarcity of rewards, and absence of system robustness after task composition. To surmount these challenges, we view task composition through the prism of category theory -- a mathematical discipline exploring structures and their compositional relationships. The categorical properties of Markov decision processes untangle complex tasks into manageable sub-tasks, allowing for strategical reduction of dimensionality, facilitating more tractable reward structures, and bolstering system robustness. Experimental results support the categorical theory of reinforcement learning by enabling skill reduction, reuse, and recycling when learning complex robotic arm tasks.
An Efficient Reconstructed Differential Evolution Variant by Some of the Current State-of-the-art Strategies for Solving Single Objective Bound Constrained Problems
Apr 25, 2024Complex single-objective bounded problems are often difficult to solve. In evolutionary computation methods, since the proposal of differential evolution algorithm in 1997, it has been widely studied and developed due to its simplicity and efficiency. These developments include various adaptive strategies, operator improvements, and the introduction of other search methods. After 2014, research based on LSHADE has also been widely studied by researchers. However, although recently proposed improvement strategies have shown superiority over their previous generation's first performance, adding all new strategies may not necessarily bring the strongest performance. Therefore, we recombine some effective advances based on advanced differential evolution variants in recent years and finally determine an effective combination scheme to further promote the performance of differential evolution. In this paper, we propose a strategy recombination and reconstruction differential evolution algorithm called reconstructed differential evolution (RDE) to solve single-objective bounded optimization problems. Based on the benchmark suite of the 2024 IEEE Congress on Evolutionary Computation (CEC2024), we tested RDE and several other advanced differential evolution variants. The experimental results show that RDE has superior performance in solving complex optimization problems.