 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMEGAN: Memory Enhanced Graph Attention Network for Space-Time Video Super-Resolution
Paper and Code
Oct 28, 2021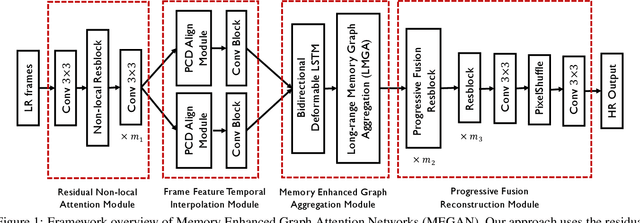
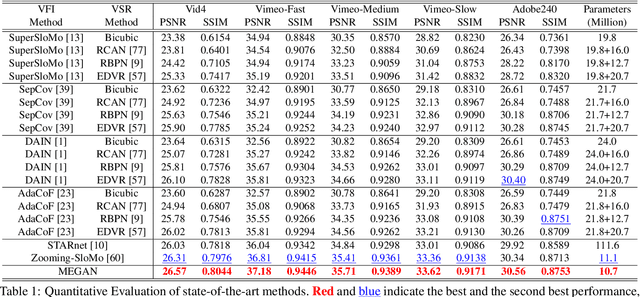
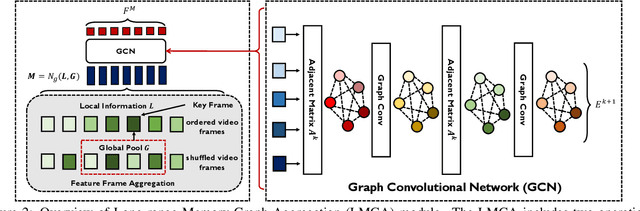
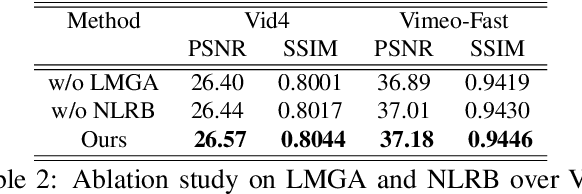
Space-time video super-resolution (STVSR) aims to construct a high space-time resolution video sequence from the corresponding low-frame-rate, low-resolution video sequence. Inspired by the recent success to consider spatial-temporal information for space-time super-resolution, our main goal in this work is to take full considerations of spatial and temporal correlations within the video sequences of fast dynamic events. To this end, we propose a novel one-stage memory enhanced graph attention network (MEGAN) for space-time video super-resolution. Specifically, we build a novel long-range memory graph aggregation (LMGA) module to dynamically capture correlations along the channel dimensions of the feature maps and adaptively aggregate channel features to enhance the feature representations. We introduce a non-local residual block, which enables each channel-wise feature to attend global spatial hierarchical features. In addition, we adopt a progressive fusion module to further enhance the representation ability by extensively exploiting spatial-temporal correlations from multiple frames. Experiment results demonstrate that our method achieves better results compared with the state-of-the-art methods quantitatively and visually.