 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDense Dynamics-Aware Reward Synthesis: Integrating Prior Experience with Demonstrations
Dec 02, 2024



Many continuous control problems can be formulated as sparse-reward reinforcement learning (RL) tasks. In principle, online RL methods can automatically explore the state space to solve each new task. However, discovering sequences of actions that lead to a non-zero reward becomes exponentially more difficult as the task horizon increases. Manually shaping rewards can accelerate learning for a fixed task, but it is an arduous process that must be repeated for each new environment. We introduce a systematic reward-shaping framework that distills the information contained in 1) a task-agnostic prior data set and 2) a small number of task-specific expert demonstrations, and then uses these priors to synthesize dense dynamics-aware rewards for the given task. This supervision substantially accelerates learning in our experiments, and we provide analysis demonstrating how the approach can effectively guide online learning agents to faraway goals.
Reward-Machine-Guided, Self-Paced Reinforcement Learning
May 25, 2023


Self-paced reinforcement learning (RL) aims to improve the data efficiency of learning by automatically creating sequences, namely curricula, of probability distributions over contexts. However, existing techniques for self-paced RL fail in long-horizon planning tasks that involve temporally extended behaviors. We hypothesize that taking advantage of prior knowledge about the underlying task structure can improve the effectiveness of self-paced RL. We develop a self-paced RL algorithm guided by reward machines, i.e., a type of finite-state machine that encodes the underlying task structure. The algorithm integrates reward machines in 1) the update of the policy and value functions obtained by any RL algorithm of choice, and 2) the update of the automated curriculum that generates context distributions. Our empirical results evidence that the proposed algorithm achieves optimal behavior reliably even in cases in which existing baselines cannot make any meaningful progress. It also decreases the curriculum length and reduces the variance in the curriculum generation process by up to one-fourth and four orders of magnitude, respectively.
Joint Learning of Reward Machines and Policies in Environments with Partially Known Semantics
Apr 20, 2022

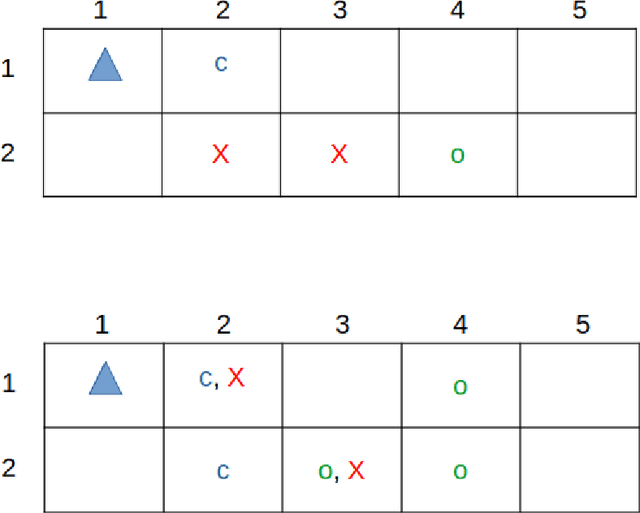
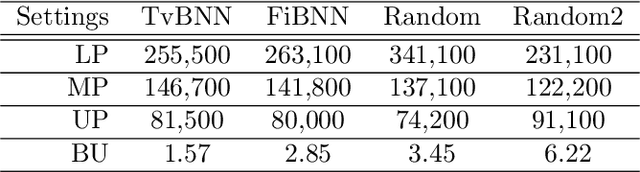
We study the problem of reinforcement learning for a task encoded by a reward machine. The task is defined over a set of properties in the environment, called atomic propositions, and represented by Boolean variables. One unrealistic assumption commonly used in the literature is that the truth values of these propositions are accurately known. In real situations, however, these truth values are uncertain since they come from sensors that suffer from imperfections. At the same time, reward machines can be difficult to model explicitly, especially when they encode complicated tasks. We develop a reinforcement-learning algorithm that infers a reward machine that encodes the underlying task while learning how to execute it, despite the uncertainties of the propositions' truth values. In order to address such uncertainties, the algorithm maintains a probabilistic estimate about the truth value of the atomic propositions; it updates this estimate according to new sensory measurements that arrive from the exploration of the environment. Additionally, the algorithm maintains a hypothesis reward machine, which acts as an estimate of the reward machine that encodes the task to be learned. As the agent explores the environment, the algorithm updates the hypothesis reward machine according to the obtained rewards and the estimate of the atomic propositions' truth value. Finally, the algorithm uses a Q-learning procedure for the states of the hypothesis reward machine to determine the policy that accomplishes the task. We prove that the algorithm successfully infers the reward machine and asymptotically learns a policy that accomplishes the respective task.