 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSimulation Distillation: Pretraining World Models in Simulation for Rapid Real-World Adaptation
Mar 16, 2026Simulation-to-real transfer remains a central challenge in robotics, as mismatches between simulated and real-world dynamics often lead to failures. While reinforcement learning offers a principled mechanism for adaptation, existing sim-to-real finetuning methods struggle with exploration and long-horizon credit assignment in the low-data regimes typical of real-world robotics. We introduce Simulation Distillation (SimDist), a sim-to-real framework that distills structural priors from a simulator into a latent world model and enables rapid real-world adaptation via online planning and supervised dynamics finetuning. By transferring reward and value models directly from simulation, SimDist provides dense planning signals from raw perception without requiring value learning during deployment. As a result, real-world adaptation reduces to short-horizon system identification, avoiding long-horizon credit assignment and enabling fast, stable improvement. Across precise manipulation and quadruped locomotion tasks, SimDist substantially outperforms prior methods in data efficiency, stability, and final performance. Project website and code: https://sim-dist.github.io/
Emergent Dexterity via Diverse Resets and Large-Scale Reinforcement Learning
Mar 16, 2026Reinforcement learning in massively parallel physics simulations has driven major progress in sim-to-real robot learning. However, current approaches remain brittle and task-specific, relying on extensive per-task engineering to design rewards, curricula, and demonstrations. Even with this engineering, they often fail on long-horizon, contact-rich manipulation tasks and do not meaningfully scale with compute, as performance quickly saturates when training revisits the same narrow regions of state space. We introduce \Method, a simple and scalable framework that enables on-policy reinforcement learning to robustly solve a broad class of dexterous manipulation tasks using a single reward function, fixed algorithm hyperparameters, no curricula, and no human demonstrations. Our key insight is that long-horizon exploration can be dramatically simplified by using simulator resets to systematically expose the RL algorithm to the diverse set of robot-object interactions which underlie dexterous manipulation. \Method\ programmatically generates such resets with minimal human input, converting additional compute directly into broader behavioral coverage and continued performance gains. We show that \Method\ gracefully scales to long-horizon dexterous manipulation tasks beyond the capabilities of existing approaches and is able to learn robust policies over significantly wider ranges of initial conditions than baselines. Finally, we distill \Method \ into visuomotor policies which display robust retrying behavior and substantially higher success rates than baselines when transferred to the real world zero-shot. Project webpage: https://omnireset.github.io
RFS: Reinforcement learning with Residual flow steering for dexterous manipulation
Feb 03, 2026Imitation learning has emerged as an effective approach for bootstrapping sequential decision-making in robotics, achieving strong performance even in high-dimensional dexterous manipulation tasks. Recent behavior cloning methods further leverage expressive generative models, such as diffusion models and flow matching, to represent multimodal action distributions. However, policies pretrained in this manner often exhibit limited generalization and require additional fine-tuning to achieve robust performance at deployment time. Such adaptation must preserve the global exploration benefits of pretraining while enabling rapid correction of local execution errors. We propose Residual Flow Steering(RFS), a data-efficient reinforcement learning framework for adapting pretrained generative policies. RFS steers a pretrained flow-matching policy by jointly optimizing a residual action and a latent noise distribution, enabling complementary forms of exploration: local refinement through residual corrections and global exploration through latent-space modulation. This design allows efficient adaptation while retaining the expressive structure of the pretrained policy. We demonstrate the effectiveness of RFS on dexterous manipulation tasks, showing efficient fine-tuning in both simulation and real-world settings when adapting pretrained base policies. Project website:https://weirdlabuw.github.io/rfs.
Rapidly Adapting Policies to the Real World via Simulation-Guided Fine-Tuning
Feb 04, 2025



Robot learning requires a considerable amount of high-quality data to realize the promise of generalization. However, large data sets are costly to collect in the real world. Physics simulators can cheaply generate vast data sets with broad coverage over states, actions, and environments. However, physics engines are fundamentally misspecified approximations to reality. This makes direct zero-shot transfer from simulation to reality challenging, especially in tasks where precise and force-sensitive manipulation is necessary. Thus, fine-tuning these policies with small real-world data sets is an appealing pathway for scaling robot learning. However, current reinforcement learning fine-tuning frameworks leverage general, unstructured exploration strategies which are too inefficient to make real-world adaptation practical. This paper introduces the Simulation-Guided Fine-tuning (SGFT) framework, which demonstrates how to extract structural priors from physics simulators to substantially accelerate real-world adaptation. Specifically, our approach uses a value function learned in simulation to guide real-world exploration. We demonstrate this approach across five real-world dexterous manipulation tasks where zero-shot sim-to-real transfer fails. We further demonstrate our framework substantially outperforms baseline fine-tuning methods, requiring up to an order of magnitude fewer real-world samples and succeeding at difficult tasks where prior approaches fail entirely. Last but not least, we provide theoretical justification for this new paradigm which underpins how SGFT can rapidly learn high-performance policies in the face of large sim-to-real dynamics gaps. Project webpage: https://weirdlabuw.github.io/sgft/{weirdlabuw.github.io/sgft}
Dense Dynamics-Aware Reward Synthesis: Integrating Prior Experience with Demonstrations
Dec 02, 2024



Many continuous control problems can be formulated as sparse-reward reinforcement learning (RL) tasks. In principle, online RL methods can automatically explore the state space to solve each new task. However, discovering sequences of actions that lead to a non-zero reward becomes exponentially more difficult as the task horizon increases. Manually shaping rewards can accelerate learning for a fixed task, but it is an arduous process that must be repeated for each new environment. We introduce a systematic reward-shaping framework that distills the information contained in 1) a task-agnostic prior data set and 2) a small number of task-specific expert demonstrations, and then uses these priors to synthesize dense dynamics-aware rewards for the given task. This supervision substantially accelerates learning in our experiments, and we provide analysis demonstrating how the approach can effectively guide online learning agents to faraway goals.
Learning to Walk from Three Minutes of Real-World Data with Semi-structured Dynamics Models
Oct 11, 2024Traditionally, model-based reinforcement learning (MBRL) methods exploit neural networks as flexible function approximators to represent a priori unknown environment dynamics. However, training data are typically scarce in practice, and these black-box models often fail to generalize. Modeling architectures that leverage known physics can substantially reduce the complexity of system-identification, but break down in the face of complex phenomena such as contact. We introduce a novel framework for learning semi-structured dynamics models for contact-rich systems which seamlessly integrates structured first principles modeling techniques with black-box auto-regressive models. Specifically, we develop an ensemble of probabilistic models to estimate external forces, conditioned on historical observations and actions, and integrate these predictions using known Lagrangian dynamics. With this semi-structured approach, we can make accurate long-horizon predictions with substantially less data than prior methods. We leverage this capability and propose Semi-Structured Reinforcement Learning (SSRL) a simple model-based learning framework which pushes the sample complexity boundary for real-world learning. We validate our approach on a real-world Unitree Go1 quadruped robot, learning dynamic gaits -- from scratch -- on both hard and soft surfaces with just a few minutes of real-world data. Video and code are available at: https://sites.google.com/utexas.edu/ssrl
Feedback is All You Need: Real-World Reinforcement Learning with Approximate Physics-Based Models
Jul 16, 2023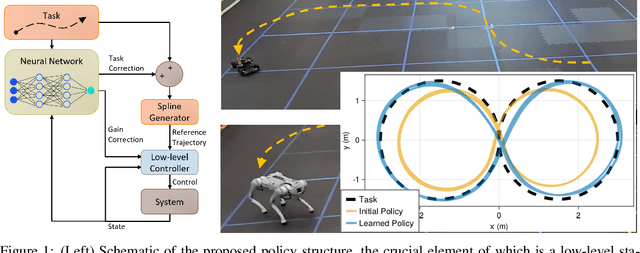
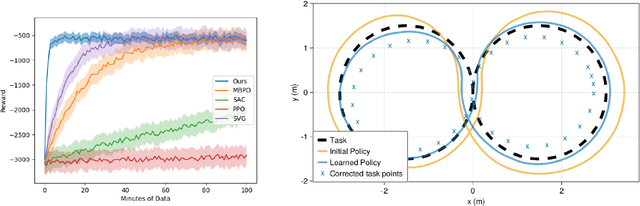
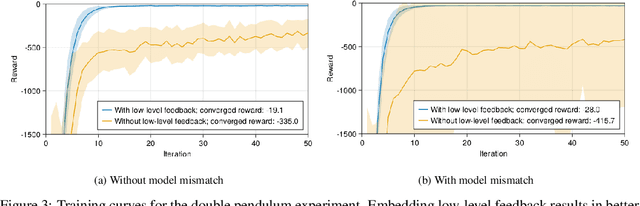
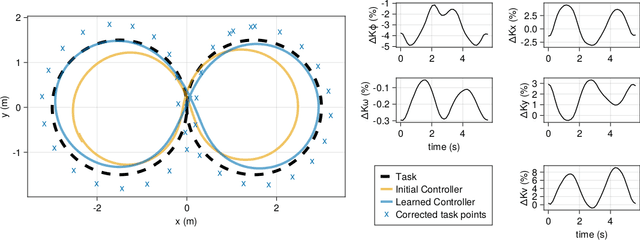
We focus on developing efficient and reliable policy optimization strategies for robot learning with real-world data. In recent years, policy gradient methods have emerged as a promising paradigm for training control policies in simulation. However, these approaches often remain too data inefficient or unreliable to train on real robotic hardware. In this paper we introduce a novel policy gradient-based policy optimization framework which systematically leverages a (possibly highly simplified) first-principles model and enables learning precise control policies with limited amounts of real-world data. Our approach $1)$ uses the derivatives of the model to produce sample-efficient estimates of the policy gradient and $2)$ uses the model to design a low-level tracking controller, which is embedded in the policy class. Theoretical analysis provides insight into how the presence of this feedback controller addresses overcomes key limitations of stand-alone policy gradient methods, while hardware experiments with a small car and quadruped demonstrate that our approach can learn precise control strategies reliably and with only minutes of real-world data.
The Power of Learned Locally Linear Models for Nonlinear Policy Optimization
May 16, 2023A common pipeline in learning-based control is to iteratively estimate a model of system dynamics, and apply a trajectory optimization algorithm - e.g.~$\mathtt{iLQR}$ - on the learned model to minimize a target cost. This paper conducts a rigorous analysis of a simplified variant of this strategy for general nonlinear systems. We analyze an algorithm which iterates between estimating local linear models of nonlinear system dynamics and performing $\mathtt{iLQR}$-like policy updates. We demonstrate that this algorithm attains sample complexity polynomial in relevant problem parameters, and, by synthesizing locally stabilizing gains, overcomes exponential dependence in problem horizon. Experimental results validate the performance of our algorithm, and compare to natural deep-learning baselines.
Lyapunov Design for Robust and Efficient Robotic Reinforcement Learning
Aug 13, 2022
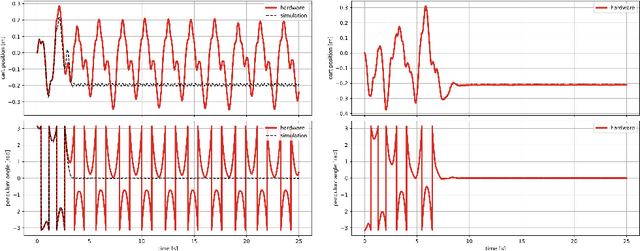


Recent advances in the reinforcement learning (RL) literature have enabled roboticists to automatically train complex policies in simulated environments. However, due to the poor sample complexity of these methods, solving reinforcement learning problems using real-world data remains a challenging problem. This paper introduces a novel cost-shaping method which aims to reduce the number of samples needed to learn a stabilizing controller. The method adds a term involving a control Lyapunov function (CLF) -- an `energy-like' function from the model-based control literature -- to typical cost formulations. Theoretical results demonstrate the new costs lead to stabilizing controllers when smaller discount factors are used, which is well-known to reduce sample complexity. Moreover, the addition of the CLF term `robustifies' the search for a stabilizing controller by ensuring that even highly sub-optimal polices will stabilize the system. We demonstrate our approach with two hardware examples where we learn stabilizing controllers for a cartpole and an A1 quadruped with only seconds and a few minutes of fine-tuning data, respectively.
On the Stability of Nonlinear Receding Horizon Control: A Geometric Perspective
Mar 27, 2021
The widespread adoption of nonlinear Receding Horizon Control (RHC) strategies by industry has led to more than 30 years of intense research efforts to provide stability guarantees for these methods. However, current theoretical guarantees require that each (generally nonconvex) planning problem can be solved to (approximate) global optimality, which is an unrealistic requirement for the derivative-based local optimization methods generally used in practical implementations of RHC. This paper takes the first step towards understanding stability guarantees for nonlinear RHC when the inner planning problem is solved to first-order stationary points, but not necessarily global optima. Special attention is given to feedback linearizable systems, and a mixture of positive and negative results are provided. We establish that, under certain strong conditions, first-order solutions to RHC exponentially stabilize linearizable systems. Crucially, this guarantee requires that state costs applied to the planning problems are in a certain sense `compatible' with the global geometry of the system, and a simple counter-example demonstrates the necessity of this condition. These results highlight the need to rethink the role of global geometry in the context of optimization-based control.