 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGemini Embedding 2: A Native Multimodal Embedding Model from Gemini
May 26, 2026We introduce Gemini Embedding 2, a native multimodal embedding model that allows embedding video, audio, image, and text modalities in a unified representation space. We leverage the multimodal capabilities of Gemini to produce embeddings for arbitrary combinations of interleaved inputs across all these modalities that generalize well across a wide variety of tasks. Applying large-scale contrastive learning in a multi-task multi-stage training setup, we achieve state-of-the-art performance on key embedding benchmarks including unimodal, cross-modal, and multimodal retrieval spanning a diverse set of tasks. We show that our embedding model demonstrates strong performance (with a score of 62.9 R@1 on MSCOCO, 68.8 NDCG@10 on Vatex, 69.9 on MTEB multilingual and 84.0 on MTEB Code) across a variety of tasks surpassing the performance of specialized models. These unified capabilities make Gemini Embedding 2 a promising candidate for downstream use cases such as RAG, recommendation and search. Furthermore, its robust zero-shot performance across distinct fields - from astronomy and bioscience to fine arts and the culinary arts - establishes it as a highly reliable, out-of-the-box representation even for specialized domains.
WorldBench: Disambiguating Physics for Diagnostic Evaluation of World Models
Jan 29, 2026Recent advances in generative foundational models, often termed "world models," have propelled interest in applying them to critical tasks like robotic planning and autonomous system training. For reliable deployment, these models must exhibit high physical fidelity, accurately simulating real-world dynamics. Existing physics-based video benchmarks, however, suffer from entanglement, where a single test simultaneously evaluates multiple physical laws and concepts, fundamentally limiting their diagnostic capability. We introduce WorldBench, a novel video-based benchmark specifically designed for concept-specific, disentangled evaluation, allowing us to rigorously isolate and assess understanding of a single physical concept or law at a time. To make WorldBench comprehensive, we design benchmarks at two different levels: 1) an evaluation of intuitive physical understanding with concepts such as object permanence or scale/perspective, and 2) an evaluation of low-level physical constants and material properties such as friction coefficients or fluid viscosity. When SOTA video-based world models are evaluated on WorldBench, we find specific patterns of failure in particular physics concepts, with all tested models lacking the physical consistency required to generate reliable real-world interactions. Through its concept-specific evaluation, WorldBench offers a more nuanced and scalable framework for rigorously evaluating the physical reasoning capabilities of video generation and world models, paving the way for more robust and generalizable world-model-driven learning.
Shape of Thought: When Distribution Matters More than Correctness in Reasoning Tasks
Dec 24, 2025We present the surprising finding that a language model's reasoning capabilities can be improved by training on synthetic datasets of chain-of-thought (CoT) traces from more capable models, even when all of those traces lead to an incorrect final answer. Our experiments show this approach can yield better performance on reasoning tasks than training on human-annotated datasets. We hypothesize that two key factors explain this phenomenon: first, the distribution of synthetic data is inherently closer to the language model's own distribution, making it more amenable to learning. Second, these `incorrect' traces are often only partially flawed and contain valid reasoning steps from which the model can learn. To further test the first hypothesis, we use a language model to paraphrase human-annotated traces -- shifting their distribution closer to the model's own distribution -- and show that this improves performance. For the second hypothesis, we introduce increasingly flawed CoT traces and study to what extent models are tolerant to these flaws. We demonstrate our findings across various reasoning domains like math, algorithmic reasoning and code generation using MATH, GSM8K, Countdown and MBPP datasets on various language models ranging from 1.5B to 9B across Qwen, Llama, and Gemma models. Our study shows that curating datasets that are closer to the model's distribution is a critical aspect to consider. We also show that a correct final answer is not always a reliable indicator of a faithful reasoning process.
Language Models' Factuality Depends on the Language of Inquiry
Feb 25, 2025



Multilingual language models (LMs) are expected to recall factual knowledge consistently across languages, yet they often fail to transfer knowledge between languages even when they possess the correct information in one of the languages. For example, we find that an LM may correctly identify Rashed Al Shashai as being from Saudi Arabia when asked in Arabic, but consistently fails to do so when asked in English or Swahili. To systematically investigate this limitation, we introduce a benchmark of 10,000 country-related facts across 13 languages and propose three novel metrics: Factual Recall Score, Knowledge Transferability Score, and Cross-Lingual Factual Knowledge Transferability Score-to quantify factual recall and knowledge transferability in LMs across different languages. Our results reveal fundamental weaknesses in today's state-of-the-art LMs, particularly in cross-lingual generalization where models fail to transfer knowledge effectively across different languages, leading to inconsistent performance sensitive to the language used. Our findings emphasize the need for LMs to recognize language-specific factual reliability and leverage the most trustworthy information across languages. We release our benchmark and evaluation framework to drive future research in multilingual knowledge transfer.
Physical Reasoning and Object Planning for Household Embodied Agents
Nov 22, 2023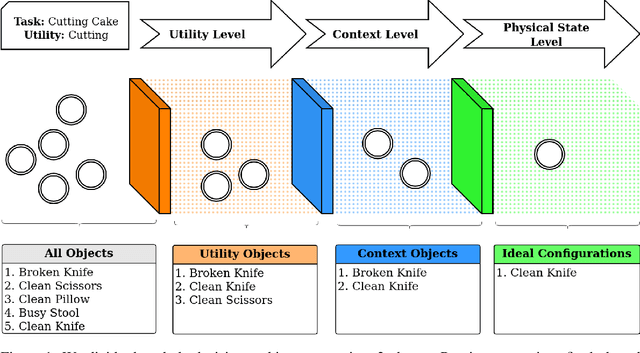



In this study, we explore the sophisticated domain of task planning for robust household embodied agents, with a particular emphasis on the intricate task of selecting substitute objects. We introduce the CommonSense Object Affordance Task (COAT), a novel framework designed to analyze reasoning capabilities in commonsense scenarios. This approach is centered on understanding how these agents can effectively identify and utilize alternative objects when executing household tasks, thereby offering insights into the complexities of practical decision-making in real-world environments.Drawing inspiration from human decision-making, we explore how large language models tackle this challenge through three meticulously crafted commonsense question-and-answer datasets, featuring refined rules and human annotations. Our evaluation of state-of-the-art language models on these datasets sheds light on three pivotal considerations: 1) aligning an object's inherent utility with the task at hand, 2) navigating contextual dependencies (societal norms, safety, appropriateness, and efficiency), and 3) accounting for the current physical state of the object. To maintain accessibility, we introduce five abstract variables reflecting an object's physical condition, modulated by human insights to simulate diverse household scenarios. Our contributions include insightful Object-Utility mappings addressing the first consideration and two extensive QA datasets (15k and 130k questions) probing the intricacies of contextual dependencies and object states. The datasets, along with our findings, are accessible at: \url{https://github.com/com-phy-affordance/COAT}. This research not only advances our understanding of physical commonsense reasoning in language models but also paves the way for future improvements in household agent intelligence.
CLIPGraphs: Multimodal Graph Networks to Infer Object-Room Affinities
Jun 02, 2023



This paper introduces a novel method for determining the best room to place an object in, for embodied scene rearrangement. While state-of-the-art approaches rely on large language models (LLMs) or reinforcement learned (RL) policies for this task, our approach, CLIPGraphs, efficiently combines commonsense domain knowledge, data-driven methods, and recent advances in multimodal learning. Specifically, it (a)encodes a knowledge graph of prior human preferences about the room location of different objects in home environments, (b) incorporates vision-language features to support multimodal queries based on images or text, and (c) uses a graph network to learn object-room affinities based on embeddings of the prior knowledge and the vision-language features. We demonstrate that our approach provides better estimates of the most appropriate location of objects from a benchmark set of object categories in comparison with state-of-the-art baselines
Do Language Models Know When They're Hallucinating References?
May 29, 2023



Current state-of-the-art language models (LMs) are notorious for generating text with "hallucinations," a primary example being book and paper references that lack any solid basis in their training data. However, we find that many of these fabrications can be identified using the same LM, using only black-box queries without consulting any external resources. Consistency checks done with direct queries about whether the generated reference title is real (inspired by Kadavath et al. 2022, Lin et al. 2022, Manakul et al. 2023) are compared to consistency checks with indirect queries which ask for ancillary details such as the authors of the work. These consistency checks are found to be partially reliable indicators of whether or not the reference is a hallucination. In particular, we find that LMs in the GPT-series will hallucinate differing authors of hallucinated references when queried in independent sessions, while it will consistently identify authors of real references. This suggests that the hallucination may be more a result of generation techniques than the underlying representation.
Sequence-Agnostic Multi-Object Navigation
May 10, 2023The Multi-Object Navigation (MultiON) task requires a robot to localize an instance (each) of multiple object classes. It is a fundamental task for an assistive robot in a home or a factory. Existing methods for MultiON have viewed this as a direct extension of Object Navigation (ON), the task of localising an instance of one object class, and are pre-sequenced, i.e., the sequence in which the object classes are to be explored is provided in advance. This is a strong limitation in practical applications characterized by dynamic changes. This paper describes a deep reinforcement learning framework for sequence-agnostic MultiON based on an actor-critic architecture and a suitable reward specification. Our framework leverages past experiences and seeks to reward progress toward individual as well as multiple target object classes. We use photo-realistic scenes from the Gibson benchmark dataset in the AI Habitat 3D simulation environment to experimentally show that our method performs better than a pre-sequenced approach and a state of the art ON method extended to MultiON.
Towards a Mathematics Formalisation Assistant using Large Language Models
Nov 14, 2022



Mathematics formalisation is the task of writing mathematics (i.e., definitions, theorem statements, proofs) in natural language, as found in books and papers, into a formal language that can then be checked for correctness by a program. It is a thriving activity today, however formalisation remains cumbersome. In this paper, we explore the abilities of a large language model (Codex) to help with formalisation in the Lean theorem prover. We find that with careful input-dependent prompt selection and postprocessing, Codex is able to formalise short mathematical statements at undergrad level with nearly 75\% accuracy for $120$ theorem statements. For proofs quantitative analysis is infeasible and we undertake a detailed case study. We choose a diverse set of $13$ theorems at undergrad level with proofs that fit in two-three paragraphs. We show that with a new prompting strategy Codex can formalise these proofs in natural language with at least one out of twelve Codex completion being easy to repair into a complete proof. This is surprising as essentially no aligned data exists for formalised mathematics, particularly for proofs. These results suggest that large language models are a promising avenue towards fully or partially automating formalisation.
Lyapunov Design for Robust and Efficient Robotic Reinforcement Learning
Aug 13, 2022
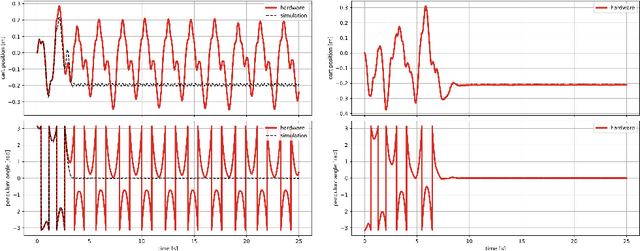


Recent advances in the reinforcement learning (RL) literature have enabled roboticists to automatically train complex policies in simulated environments. However, due to the poor sample complexity of these methods, solving reinforcement learning problems using real-world data remains a challenging problem. This paper introduces a novel cost-shaping method which aims to reduce the number of samples needed to learn a stabilizing controller. The method adds a term involving a control Lyapunov function (CLF) -- an `energy-like' function from the model-based control literature -- to typical cost formulations. Theoretical results demonstrate the new costs lead to stabilizing controllers when smaller discount factors are used, which is well-known to reduce sample complexity. Moreover, the addition of the CLF term `robustifies' the search for a stabilizing controller by ensuring that even highly sub-optimal polices will stabilize the system. We demonstrate our approach with two hardware examples where we learn stabilizing controllers for a cartpole and an A1 quadruped with only seconds and a few minutes of fine-tuning data, respectively.