 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnticipate & Act : Integrating LLMs and Classical Planning for Efficient Task Execution in Household Environments
Feb 04, 2025



Assistive agents performing household tasks such as making the bed or cooking breakfast often compute and execute actions that accomplish one task at a time. However, efficiency can be improved by anticipating upcoming tasks and computing an action sequence that jointly achieves these tasks. State-of-the-art methods for task anticipation use data-driven deep networks and Large Language Models (LLMs), but they do so at the level of high-level tasks and/or require many training examples. Our framework leverages the generic knowledge of LLMs through a small number of prompts to perform high-level task anticipation, using the anticipated tasks as goals in a classical planning system to compute a sequence of finer-granularity actions that jointly achieve these goals. We ground and evaluate our framework's abilities in realistic scenarios in the VirtualHome environment and demonstrate a 31% reduction in execution time compared with a system that does not consider upcoming tasks.
AdaptBot: Combining LLM with Knowledge Graphs and Human Input for Generic-to-Specific Task Decomposition and Knowledge Refinement
Feb 04, 2025Embodied agents assisting humans are often asked to complete a new task in a new scenario. An agent preparing a particular dish in the kitchen based on a known recipe may be asked to prepare a new dish or to perform cleaning tasks in the storeroom. There may not be sufficient resources, e.g., time or labeled examples, to train the agent for these new situations. Large Language Models (LLMs) trained on considerable knowledge across many domains are able to predict a sequence of abstract actions for such new tasks and scenarios, although it may not be possible for the agent to execute this action sequence due to task-, agent-, or domain-specific constraints. Our framework addresses these challenges by leveraging the generic predictions provided by LLM and the prior domain-specific knowledge encoded in a Knowledge Graph (KG), enabling an agent to quickly adapt to new tasks and scenarios. The robot also solicits and uses human input as needed to refine its existing knowledge. Based on experimental evaluation over cooking and cleaning tasks in simulation domains, we demonstrate that the interplay between LLM, KG, and human input leads to substantial performance gains compared with just using the LLM output.
Teledrive: An Embodied AI based Telepresence System
Jun 01, 2024



This article presents Teledrive, a telepresence robotic system with embodied AI features that empowers an operator to navigate the telerobot in any unknown remote place with minimal human intervention. We conceive Teledrive in the context of democratizing remote care-giving for elderly citizens as well as for isolated patients, affected by contagious diseases. In particular, this paper focuses on the problem of navigating to a rough target area (like bedroom or kitchen) rather than pre-specified point destinations. This ushers in a unique AreaGoal based navigation feature, which has not been explored in depth in the contemporary solutions. Further, we describe an edge computing-based software system built on a WebRTC-based communication framework to realize the aforementioned scheme through an easy-to-use speech-based human-robot interaction. Moreover, to enhance the ease of operation for the remote caregiver, we incorporate a person following feature, whereby a robot follows a person on the move in its premises as directed by the operator. Moreover, the system presented is loosely coupled with specific robot hardware, unlike the existing solutions. We have evaluated the efficacy of the proposed system through baseline experiments, user study, and real-life deployment.
* Accepted in Journal of Intelligent Robotic System
Anticipate & Collab: Data-driven Task Anticipation and Knowledge-driven Planning for Human-robot Collaboration
Apr 04, 2024



An agent assisting humans in daily living activities can collaborate more effectively by anticipating upcoming tasks. Data-driven methods represent the state of the art in task anticipation, planning, and related problems, but these methods are resource-hungry and opaque. Our prior work introduced a proof of concept framework that used an LLM to anticipate 3 high-level tasks that served as goals for a classical planning system that computed a sequence of low-level actions for the agent to achieve these goals. This paper describes DaTAPlan, our framework that significantly extends our prior work toward human-robot collaboration. Specifically, DaTAPlan planner computes actions for an agent and a human to collaboratively and jointly achieve the tasks anticipated by the LLM, and the agent automatically adapts to unexpected changes in human action outcomes and preferences. We evaluate DaTAPlan capabilities in a realistic simulation environment, demonstrating accurate task anticipation, effective human-robot collaboration, and the ability to adapt to unexpected changes. Project website: https://dataplan-hrc.github.io
CLIPGraphs: Multimodal Graph Networks to Infer Object-Room Affinities
Jun 02, 2023



This paper introduces a novel method for determining the best room to place an object in, for embodied scene rearrangement. While state-of-the-art approaches rely on large language models (LLMs) or reinforcement learned (RL) policies for this task, our approach, CLIPGraphs, efficiently combines commonsense domain knowledge, data-driven methods, and recent advances in multimodal learning. Specifically, it (a)encodes a knowledge graph of prior human preferences about the room location of different objects in home environments, (b) incorporates vision-language features to support multimodal queries based on images or text, and (c) uses a graph network to learn object-room affinities based on embeddings of the prior knowledge and the vision-language features. We demonstrate that our approach provides better estimates of the most appropriate location of objects from a benchmark set of object categories in comparison with state-of-the-art baselines
Sequence-Agnostic Multi-Object Navigation
May 10, 2023The Multi-Object Navigation (MultiON) task requires a robot to localize an instance (each) of multiple object classes. It is a fundamental task for an assistive robot in a home or a factory. Existing methods for MultiON have viewed this as a direct extension of Object Navigation (ON), the task of localising an instance of one object class, and are pre-sequenced, i.e., the sequence in which the object classes are to be explored is provided in advance. This is a strong limitation in practical applications characterized by dynamic changes. This paper describes a deep reinforcement learning framework for sequence-agnostic MultiON based on an actor-critic architecture and a suitable reward specification. Our framework leverages past experiences and seeks to reward progress toward individual as well as multiple target object classes. We use photo-realistic scenes from the Gibson benchmark dataset in the AI Habitat 3D simulation environment to experimentally show that our method performs better than a pre-sequenced approach and a state of the art ON method extended to MultiON.
Spatial Relation Graph and Graph Convolutional Network for Object Goal Navigation
Aug 27, 2022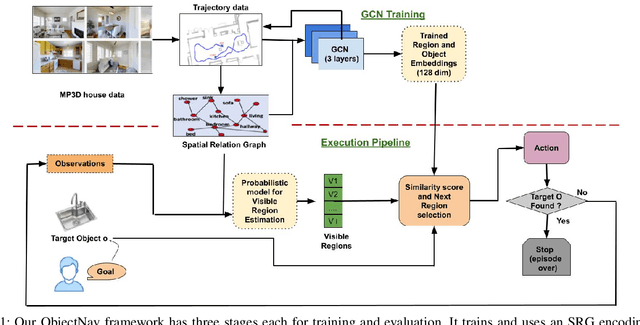
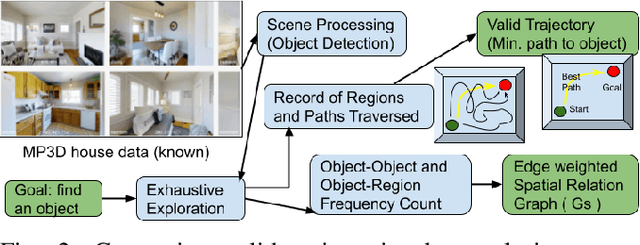
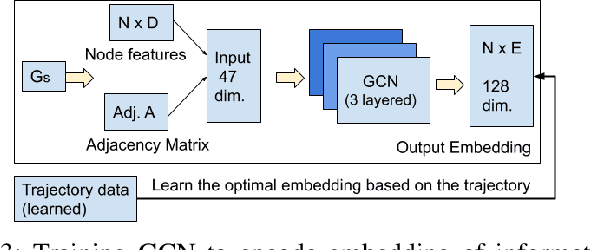
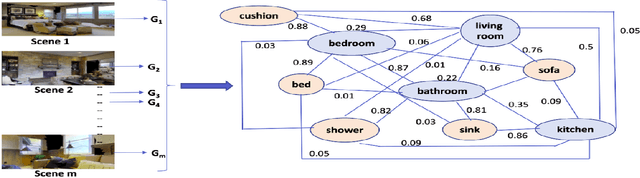
This paper describes a framework for the object-goal navigation task, which requires a robot to find and move to the closest instance of a target object class from a random starting position. The framework uses a history of robot trajectories to learn a Spatial Relational Graph (SRG) and Graph Convolutional Network (GCN)-based embeddings for the likelihood of proximity of different semantically-labeled regions and the occurrence of different object classes in these regions. To locate a target object instance during evaluation, the robot uses Bayesian inference and the SRG to estimate the visible regions, and uses the learned GCN embeddings to rank visible regions and select the region to explore next.
Object Goal Navigation using Data Regularized Q-Learning
Aug 27, 2022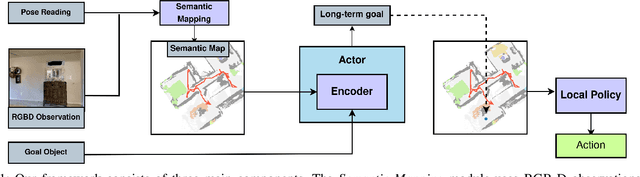
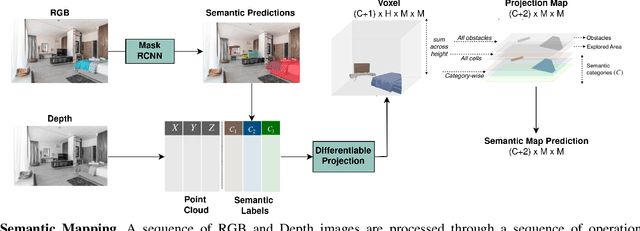
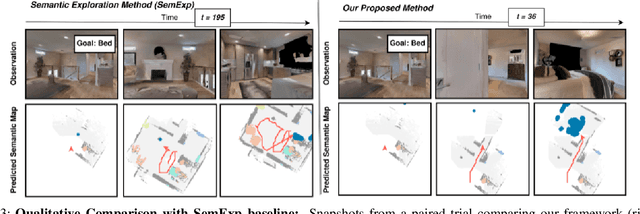

Object Goal Navigation requires a robot to find and navigate to an instance of a target object class in a previously unseen environment. Our framework incrementally builds a semantic map of the environment over time, and then repeatedly selects a long-term goal ('where to go') based on the semantic map to locate the target object instance. Long-term goal selection is formulated as a vision-based deep reinforcement learning problem. Specifically, an Encoder Network is trained to extract high-level features from a semantic map and select a long-term goal. In addition, we incorporate data augmentation and Q-function regularization to make the long-term goal selection more effective. We report experimental results using the photo-realistic Gibson benchmark dataset in the AI Habitat 3D simulation environment to demonstrate substantial performance improvement on standard measures in comparison with a state of the art data-driven baseline.
Talk-to-Resolve: Combining scene understanding and spatial dialogue to resolve granular task ambiguity for a collocated robot
Nov 22, 2021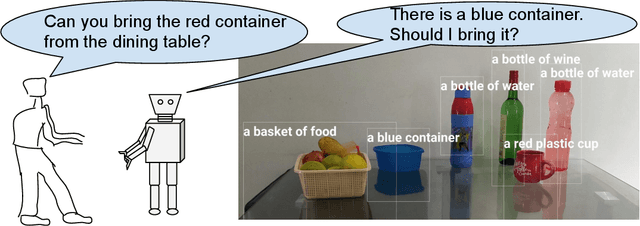
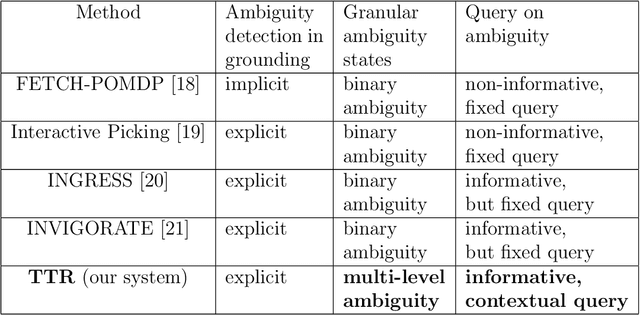
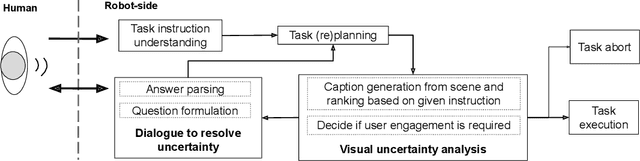

The utility of collocating robots largely depends on the easy and intuitive interaction mechanism with the human. If a robot accepts task instruction in natural language, first, it has to understand the user's intention by decoding the instruction. However, while executing the task, the robot may face unforeseeable circumstances due to the variations in the observed scene and therefore requires further user intervention. In this article, we present a system called Talk-to-Resolve (TTR) that enables a robot to initiate a coherent dialogue exchange with the instructor by observing the scene visually to resolve the impasse. Through dialogue, it either finds a cue to move forward in the original plan, an acceptable alternative to the original plan, or affirmation to abort the task altogether. To realize the possible stalemate, we utilize the dense captions of the observed scene and the given instruction jointly to compute the robot's next action. We evaluate our system based on a data set of initial instruction and situational scene pairs. Our system can identify the stalemate and resolve them with appropriate dialogue exchange with 82% accuracy. Additionally, a user study reveals that the questions from our systems are more natural (4.02 on average on a scale of 1 to 5) as compared to a state-of-the-art (3.08 on average).
Interpretable Feature Recommendation for Signal Analytics
Nov 06, 2017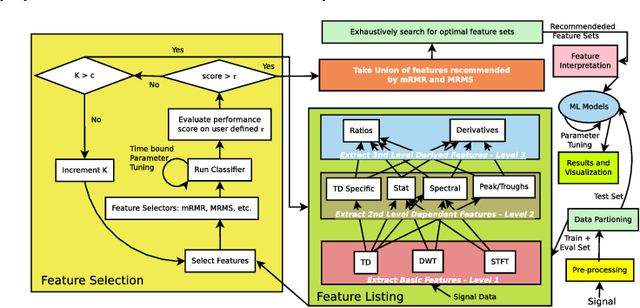

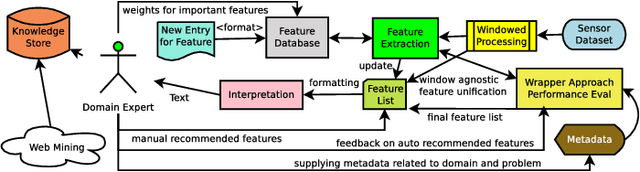

This paper presents an automated approach for interpretable feature recommendation for solving signal data analytics problems. The method has been tested by performing experiments on datasets in the domain of prognostics where interpretation of features is considered very important. The proposed approach is based on Wide Learning architecture and provides means for interpretation of the recommended features. It is to be noted that such an interpretation is not available with feature learning approaches like Deep Learning (such as Convolutional Neural Network) or feature transformation approaches like Principal Component Analysis. Results show that the feature recommendation and interpretation techniques are quite effective for the problems at hand in terms of performance and drastic reduction in time to develop a solution. It is further shown by an example, how this human-in-loop interpretation system can be used as a prescriptive system.