 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePause and Think: A Dataset and Benchmark for Video-Grounded Assistive Action Suggestion
May 30, 2026Recent Vision-Language Models (VLMs) struggle with grounded reasoning, temporal consistency, and context aware planning in videos. We introduce pause-and-think-T, a reasoning-centric training dataset that encourages models to pause, reason over visual evidence, and produce concise, actionable responses. The dataset promotes structured reasoning prior to answer generation, guiding models toward human-like, scene-grounded assistance. We fine-tune a compact 4B-parameter model and evaluate it on our pause-and-think-B benchmark targeting contextual understanding and goal planning tasks. The model achieves 58.0% accuracy at 59x fewer parameters than Qwen3-VL-235B (58.9%), matching GPT-5.2 on scene understanding and surpassing GPT-4o. Beyond our benchmark, it also shows strong out-of-distribution performance on EgoThink and TempCompass, with substantial gains in affordance, assistance, attribution recognition, situated reasoning, and temporal order, without benchmark-specific training. Our results indicate that targeted reasoning supervision enables compact models to deliver actionable, visually grounded guidance while generalizing beyond training data, without requiring large-scale model expansion.
Anticipate, Adapt, Act: A Hybrid Framework for Task Planning
Feb 23, 2026Anticipating and adapting to failures is a key capability robots need to collaborate effectively with humans in complex domains. This continues to be a challenge despite the impressive performance of state of the art AI planning systems and Large Language Models (LLMs) because of the uncertainty associated with the tasks and their outcomes. Toward addressing this challenge, we present a hybrid framework that integrates the generic prediction capabilities of an LLM with the probabilistic sequential decision-making capability of Relational Dynamic Influence Diagram Language. For any given task, the robot reasons about the task and the capabilities of the human attempting to complete it; predicts potential failures due to lack of ability (in the human) or lack of relevant domain objects; and executes actions to prevent such failures or recover from them. Experimental evaluation in the VirtualHome 3D simulation environment demonstrates substantial improvement in performance compared with state of the art baselines.
Causal-Copilot: An Autonomous Causal Analysis Agent
Apr 21, 2025Causal analysis plays a foundational role in scientific discovery and reliable decision-making, yet it remains largely inaccessible to domain experts due to its conceptual and algorithmic complexity. This disconnect between causal methodology and practical usability presents a dual challenge: domain experts are unable to leverage recent advances in causal learning, while causal researchers lack broad, real-world deployment to test and refine their methods. To address this, we introduce Causal-Copilot, an autonomous agent that operationalizes expert-level causal analysis within a large language model framework. Causal-Copilot automates the full pipeline of causal analysis for both tabular and time-series data -- including causal discovery, causal inference, algorithm selection, hyperparameter optimization, result interpretation, and generation of actionable insights. It supports interactive refinement through natural language, lowering the barrier for non-specialists while preserving methodological rigor. By integrating over 20 state-of-the-art causal analysis techniques, our system fosters a virtuous cycle -- expanding access to advanced causal methods for domain experts while generating rich, real-world applications that inform and advance causal theory. Empirical evaluations demonstrate that Causal-Copilot achieves superior performance compared to existing baselines, offering a reliable, scalable, and extensible solution that bridges the gap between theoretical sophistication and real-world applicability in causal analysis. A live interactive demo of Causal-Copilot is available at https://causalcopilot.com/.
Anticipate & Act : Integrating LLMs and Classical Planning for Efficient Task Execution in Household Environments
Feb 04, 2025



Assistive agents performing household tasks such as making the bed or cooking breakfast often compute and execute actions that accomplish one task at a time. However, efficiency can be improved by anticipating upcoming tasks and computing an action sequence that jointly achieves these tasks. State-of-the-art methods for task anticipation use data-driven deep networks and Large Language Models (LLMs), but they do so at the level of high-level tasks and/or require many training examples. Our framework leverages the generic knowledge of LLMs through a small number of prompts to perform high-level task anticipation, using the anticipated tasks as goals in a classical planning system to compute a sequence of finer-granularity actions that jointly achieve these goals. We ground and evaluate our framework's abilities in realistic scenarios in the VirtualHome environment and demonstrate a 31% reduction in execution time compared with a system that does not consider upcoming tasks.
AdaptBot: Combining LLM with Knowledge Graphs and Human Input for Generic-to-Specific Task Decomposition and Knowledge Refinement
Feb 04, 2025Embodied agents assisting humans are often asked to complete a new task in a new scenario. An agent preparing a particular dish in the kitchen based on a known recipe may be asked to prepare a new dish or to perform cleaning tasks in the storeroom. There may not be sufficient resources, e.g., time or labeled examples, to train the agent for these new situations. Large Language Models (LLMs) trained on considerable knowledge across many domains are able to predict a sequence of abstract actions for such new tasks and scenarios, although it may not be possible for the agent to execute this action sequence due to task-, agent-, or domain-specific constraints. Our framework addresses these challenges by leveraging the generic predictions provided by LLM and the prior domain-specific knowledge encoded in a Knowledge Graph (KG), enabling an agent to quickly adapt to new tasks and scenarios. The robot also solicits and uses human input as needed to refine its existing knowledge. Based on experimental evaluation over cooking and cleaning tasks in simulation domains, we demonstrate that the interplay between LLM, KG, and human input leads to substantial performance gains compared with just using the LLM output.
Anticipate & Collab: Data-driven Task Anticipation and Knowledge-driven Planning for Human-robot Collaboration
Apr 04, 2024



An agent assisting humans in daily living activities can collaborate more effectively by anticipating upcoming tasks. Data-driven methods represent the state of the art in task anticipation, planning, and related problems, but these methods are resource-hungry and opaque. Our prior work introduced a proof of concept framework that used an LLM to anticipate 3 high-level tasks that served as goals for a classical planning system that computed a sequence of low-level actions for the agent to achieve these goals. This paper describes DaTAPlan, our framework that significantly extends our prior work toward human-robot collaboration. Specifically, DaTAPlan planner computes actions for an agent and a human to collaboratively and jointly achieve the tasks anticipated by the LLM, and the agent automatically adapts to unexpected changes in human action outcomes and preferences. We evaluate DaTAPlan capabilities in a realistic simulation environment, demonstrating accurate task anticipation, effective human-robot collaboration, and the ability to adapt to unexpected changes. Project website: https://dataplan-hrc.github.io
Latent Diffusion Models with Image-Derived Annotations for Enhanced AI-Assisted Cancer Diagnosis in Histopathology
Dec 15, 2023Artificial Intelligence (AI) based image analysis has an immense potential to support diagnostic histopathology, including cancer diagnostics. However, developing supervised AI methods requires large-scale annotated datasets. A potentially powerful solution is to augment training data with synthetic data. Latent diffusion models, which can generate high-quality, diverse synthetic images, are promising. However, the most common implementations rely on detailed textual descriptions, which are not generally available in this domain. This work proposes a method that constructs structured textual prompts from automatically extracted image features. We experiment with the PCam dataset, composed of tissue patches only loosely annotated as healthy or cancerous. We show that including image-derived features in the prompt, as opposed to only healthy and cancerous labels, improves the Fr\'echet Inception Distance (FID) from 178.8 to 90.2. We also show that pathologists find it challenging to detect synthetic images, with a median sensitivity/specificity of 0.55/0.55. Finally, we show that synthetic data effectively trains AI models.
Metal Oxide-based Gas Sensor Array for the VOCs Analysis in Complex Mixtures using Machine Learning
Jul 13, 2023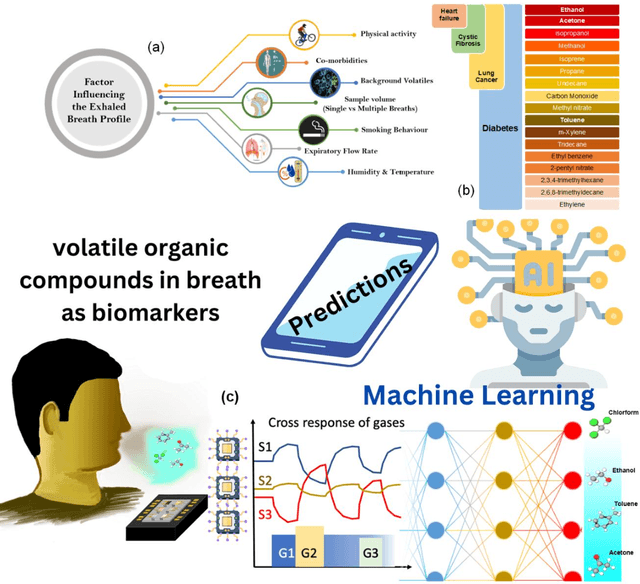
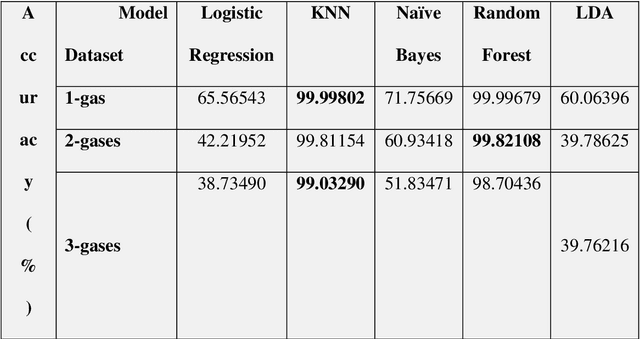
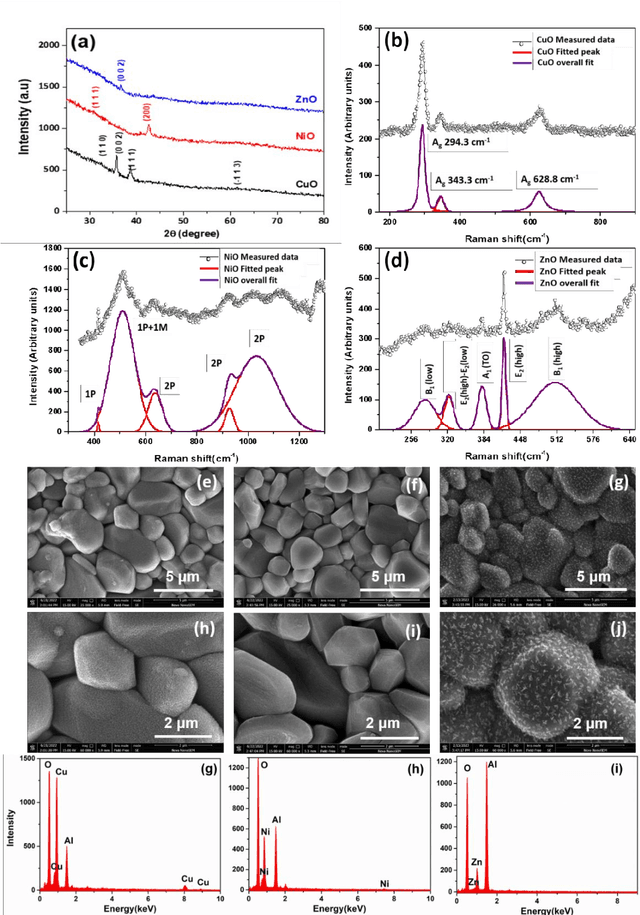
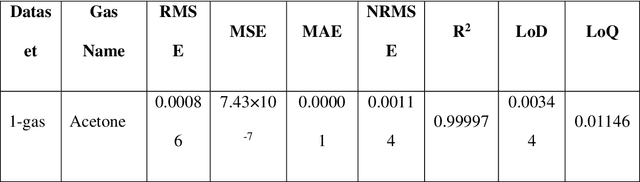
Detection of Volatile Organic Compounds (VOCs) from the breath is becoming a viable route for the early detection of diseases non-invasively. This paper presents a sensor array with three metal oxide electrodes that can use machine learning methods to identify four distinct VOCs in a mixture. The metal oxide sensor array was subjected to various VOC concentrations, including ethanol, acetone, toluene and chloroform. The dataset obtained from individual gases and their mixtures were analyzed using multiple machine learning algorithms, such as Random Forest (RF), K-Nearest Neighbor (KNN), Decision Tree, Linear Regression, Logistic Regression, Naive Bayes, Linear Discriminant Analysis, Artificial Neural Network, and Support Vector Machine. KNN and RF have shown more than 99% accuracy in classifying different varying chemicals in the gas mixtures. In regression analysis, KNN has delivered the best results with R2 value of more than 0.99 and LOD of 0.012, 0.015, 0.014 and 0.025 PPM for predicting the concentrations of varying chemicals Acetone, Toluene, Ethanol, and Chloroform, respectively in complex mixtures. Therefore, it is demonstrated that the array utilizing the provided algorithms can classify and predict the concentrations of the four gases simultaneously for disease diagnosis and treatment monitoring.
Segmentation of Microscopy Data for finding Nuclei in Divergent Images
Aug 23, 2018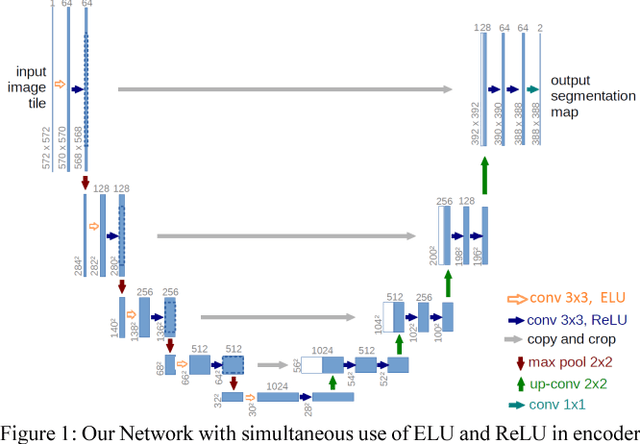
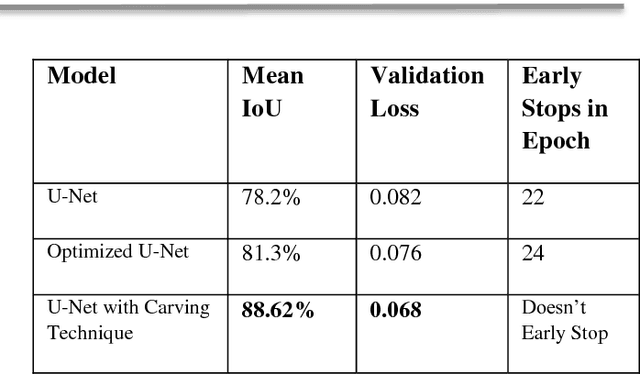
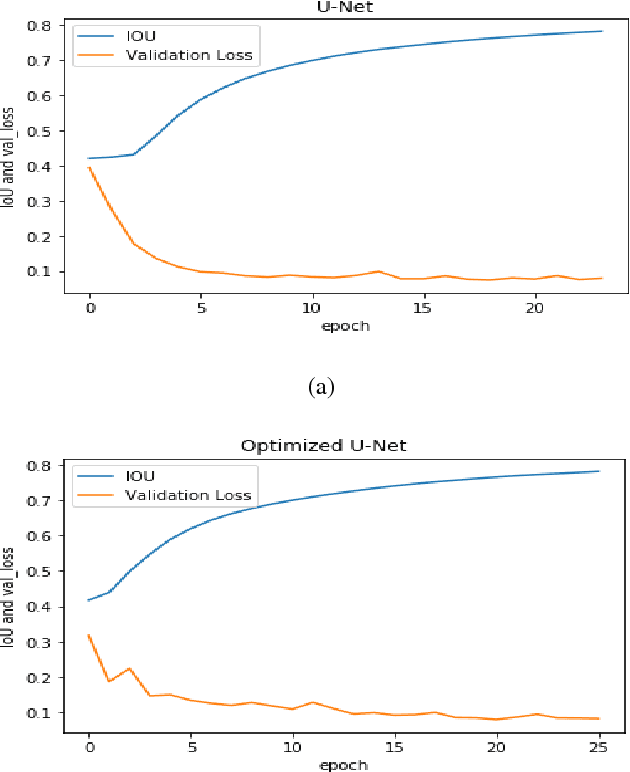
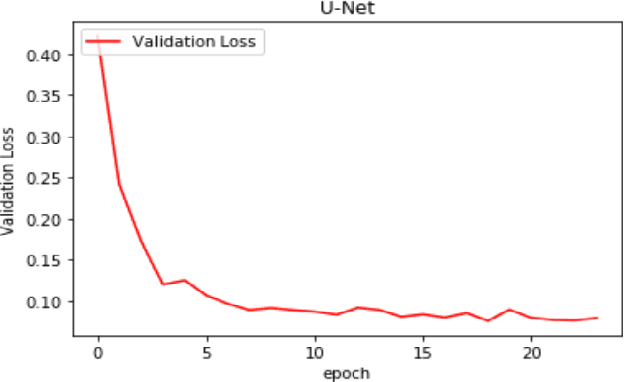
Every year millions of people die due to disease of Cancer. Due to its invasive nature it is very complex to cure even in primary stages. Hence, only method to survive this disease completely is via forecasting by analyzing the early mutation in cells of the patient biopsy. Cell Segmentation can be used to find cell which have left their nuclei. This enables faster cure and high rate of survival. Cell counting is a hard, yet tedious task that would greatly benefit from automation. To accomplish this task, segmentation of cells need to be accurate. In this paper, we have improved the learning of training data by our network. It can annotate precise masks on test data. we examine the strength of activation functions in medical image segmentation task by improving learning rates by our proposed Carving Technique. Identifying the cells nuclei is the starting point for most analyses, identifying nuclei allows researchers to identify each individual cell in a sample, and by measuring how cells react to various treatments, the researcher can understand the underlying biological processes at work. Experimental results shows the efficiency of the proposed work.