 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiNO-Diffusion. Scaling Medical Diffusion via Self-Supervised Pre-Training
Jul 16, 2024



Diffusion models (DMs) have emerged as powerful foundation models for a variety of tasks, with a large focus in synthetic image generation. However, their requirement of large annotated datasets for training limits their applicability in medical imaging, where datasets are typically smaller and sparsely annotated. We introduce DiNO-Diffusion, a self-supervised method for training latent diffusion models (LDMs) that conditions the generation process on image embeddings extracted from DiNO. By eliminating the reliance on annotations, our training leverages over 868k unlabelled images from public chest X-Ray (CXR) datasets. Despite being self-supervised, DiNO-Diffusion shows comprehensive manifold coverage, with FID scores as low as 4.7, and emerging properties when evaluated in downstream tasks. It can be used to generate semantically-diverse synthetic datasets even from small data pools, demonstrating up to 20% AUC increase in classification performance when used for data augmentation. Images were generated with different sampling strategies over the DiNO embedding manifold and using real images as a starting point. Results suggest, DiNO-Diffusion could facilitate the creation of large datasets for flexible training of downstream AI models from limited amount of real data, while also holding potential for privacy preservation. Additionally, DiNO-Diffusion demonstrates zero-shot segmentation performance of up to 84.4% Dice score when evaluating lung lobe segmentation. This evidences good CXR image-anatomy alignment, akin to segmenting using textual descriptors on vanilla DMs. Finally, DiNO-Diffusion can be easily adapted to other medical imaging modalities or state-of-the-art diffusion models, opening the door for large-scale, multi-domain image generation pipelines for medical imaging.
Latent Diffusion Models with Image-Derived Annotations for Enhanced AI-Assisted Cancer Diagnosis in Histopathology
Dec 15, 2023Artificial Intelligence (AI) based image analysis has an immense potential to support diagnostic histopathology, including cancer diagnostics. However, developing supervised AI methods requires large-scale annotated datasets. A potentially powerful solution is to augment training data with synthetic data. Latent diffusion models, which can generate high-quality, diverse synthetic images, are promising. However, the most common implementations rely on detailed textual descriptions, which are not generally available in this domain. This work proposes a method that constructs structured textual prompts from automatically extracted image features. We experiment with the PCam dataset, composed of tissue patches only loosely annotated as healthy or cancerous. We show that including image-derived features in the prompt, as opposed to only healthy and cancerous labels, improves the Fr\'echet Inception Distance (FID) from 178.8 to 90.2. We also show that pathologists find it challenging to detect synthetic images, with a median sensitivity/specificity of 0.55/0.55. Finally, we show that synthetic data effectively trains AI models.
Investigating the use of publicly available natural videos to learn Dynamic MR image reconstruction
Nov 23, 2023Purpose: To develop and assess a deep learning (DL) pipeline to learn dynamic MR image reconstruction from publicly available natural videos (Inter4K). Materials and Methods: Learning was performed for a range of DL architectures (VarNet, 3D UNet, FastDVDNet) and corresponding sampling patterns (Cartesian, radial, spiral) either from true multi-coil cardiac MR data (N=692) or from pseudo-MR data simulated from Inter4K natural videos (N=692). Real-time undersampled dynamic MR images were reconstructed using DL networks trained with cardiac data and natural videos, and compressed sensing (CS). Differences were assessed in simulations (N=104 datasets) in terms of MSE, PSNR, and SSIM and prospectively for cardiac (short axis, four chambers, N=20) and speech (N=10) data in terms of subjective image quality ranking, SNR and Edge sharpness. Friedman Chi Square tests with post-hoc Nemenyi analysis were performed to assess statistical significance. Results: For all simulation metrics, DL networks trained with cardiac data outperformed DL networks trained with natural videos, which outperformed CS (p<0.05). However, in prospective experiments DL reconstructions using both training datasets were ranked similarly (and higher than CS) and presented no statistical differences in SNR and Edge Sharpness for most conditions. Additionally, high SSIM was measured between the DL methods with cardiac data and natural videos (SSIM>0.85). Conclusion: The developed pipeline enabled learning dynamic MR reconstruction from natural videos preserving DL reconstruction advantages such as high quality fast and ultra-fast reconstructions while overcoming some limitations (data scarcity or sharing). The natural video dataset, code and pre-trained networks are made readily available on github. Key Words: real-time; dynamic MRI; deep learning; image reconstruction; machine learning;
Deep neural networks for fast acquisition of aortic 3D pressure and velocity flow fields
Aug 25, 2022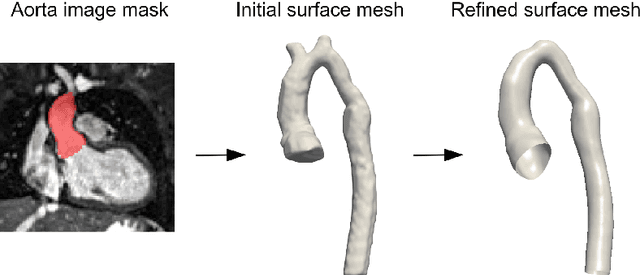

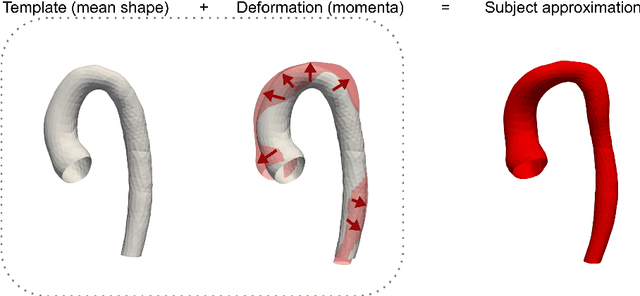
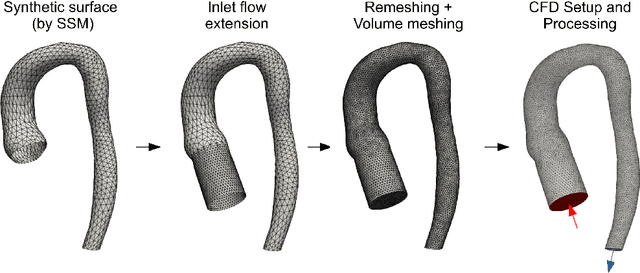
Computational fluid dynamics (CFD) can be used to simulate vascular haemodynamics and analyse potential treatment options. CFD has shown to be beneficial in improving patient outcomes. However, the implementation of CFD for routine clinical use is yet to be realised. Barriers for CFD include high computational resources, specialist experience needed for designing simulation set-ups, and long processing times. The aim of this study was to explore the use of machine learning (ML) to replicate conventional aortic CFD with automatic and fast regression models. Data used to train/test the model comprised of 3,000 CFD simulations performed on synthetically generated 3D aortic shapes. These subjects were generated from a statistical shape model (SSM) built on real patient-specific aortas (N=67). Inference performed on 200 test shapes resulted in average errors of 6.01% +/-3.12 SD and 3.99% +/-0.93 SD for pressure and velocity, respectively. Our ML-based models performed CFD in ~0.075 seconds (4,000x faster than the solver). This study shows that results from conventional vascular CFD can be reproduced using ML at a much faster rate, in an automatic process, and with high accuracy.
FReSCO: Flow Reconstruction and Segmentation for low latency Cardiac Output monitoring using deep artifact suppression and segmentation
Mar 25, 2022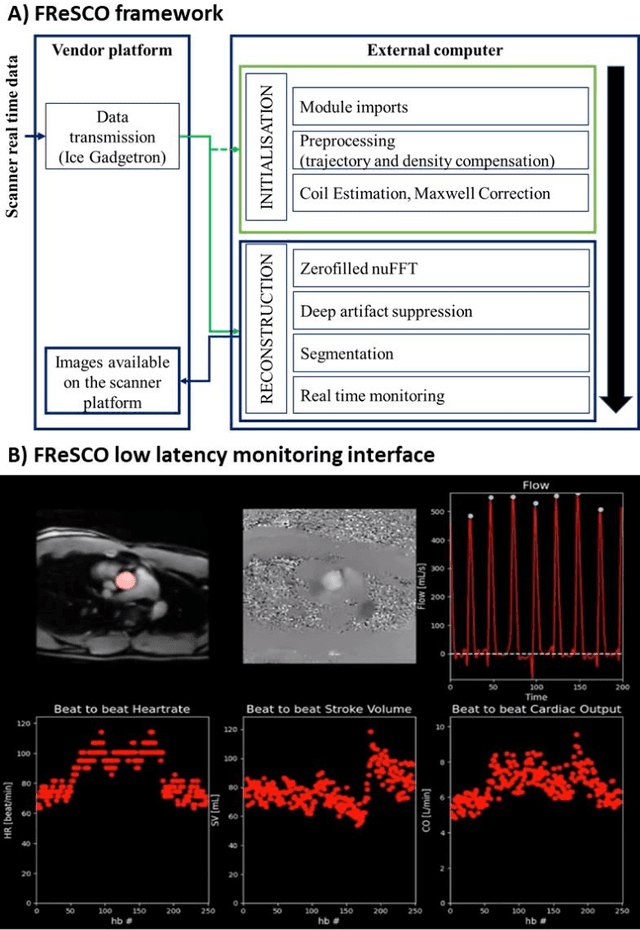
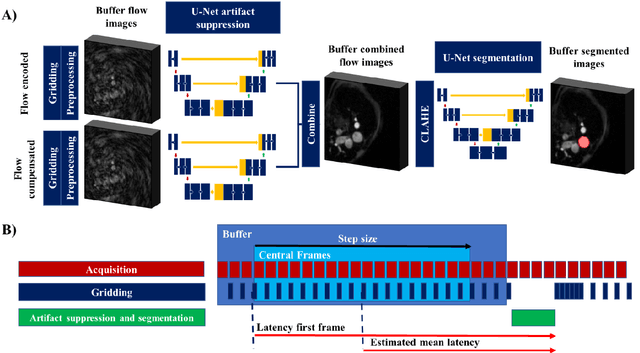
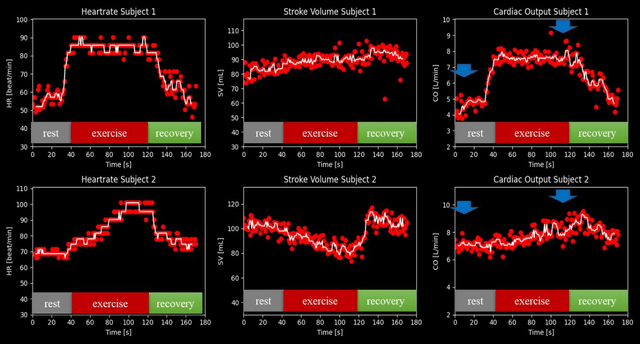
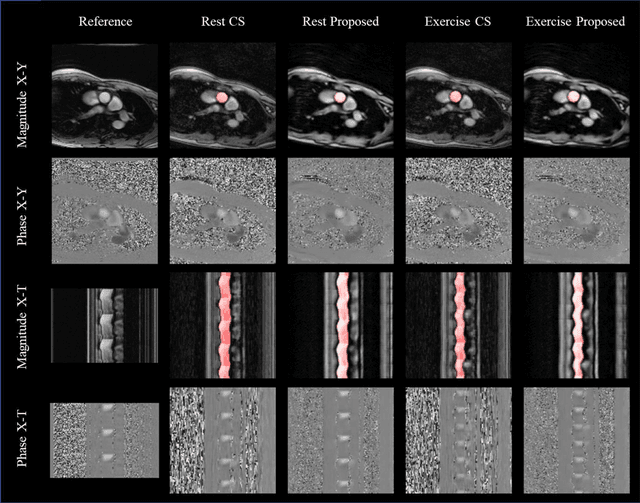
Purpose: Real-time monitoring of cardiac output (CO) requires low latency reconstruction and segmentation of real-time phase contrast MR (PCMR), which has previously been difficult to perform. Here we propose a deep learning framework for 'Flow Reconstruction and Segmentation for low latency Cardiac Output monitoring' (FReSCO). Methods: Deep artifact suppression and segmentation U-Nets were independently trained. Breath hold spiral PCMR data (n=516) was synthetically undersampled using a variable density spiral sampling pattern and gridded to create aliased data for training of the artifact suppression U-net. A subset of the data (n=96) was segmented and used to train the segmentation U-net. Real-time spiral PCMR was prospectively acquired and then reconstructed and segmented using the trained models (FReSCO) at low latency at the scanner in 10 healthy subjects during rest, exercise and recovery periods. CO obtained via FReSCO was compared to a reference rest CO and rest and exercise Compressed Sensing (CS) CO. Results: FReSCO was demonstrated prospectively at the scanner. Beat-to-beat heartrate, stroke volume and CO could be visualized with a mean latency of 622ms. No significant differences were noted when compared to reference at rest (Bias = -0.21+-0.50 L/min, p=0.246) or CS at peak exercise (Bias=0.12+-0.48 L/min, p=0.458). Conclusion: FReSCO was successfully demonstrated for real-time monitoring of CO during exercise and could provide a convenient tool for assessment of the hemodynamic response to a range of stressors.
Machine Learning in Magnetic Resonance Imaging: Image Reconstruction
Dec 09, 2020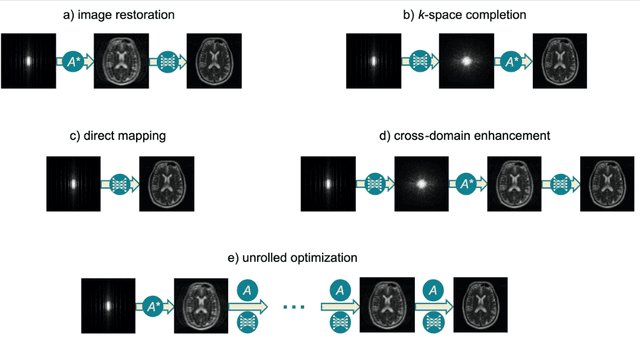
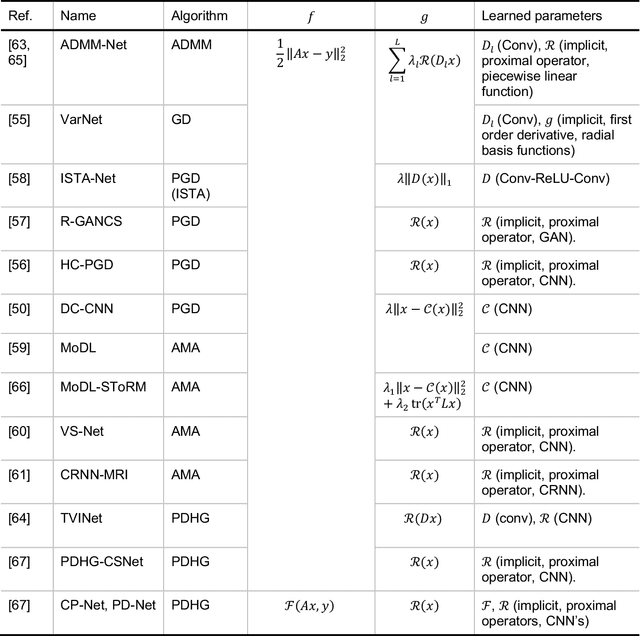
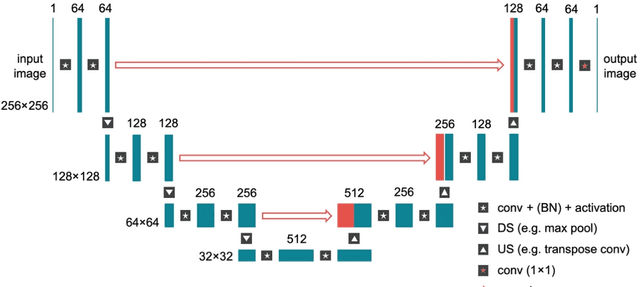
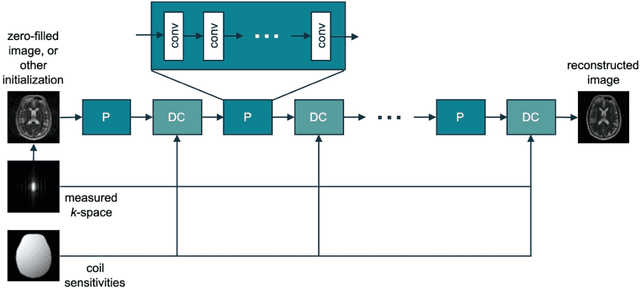
Magnetic Resonance Imaging (MRI) plays a vital role in diagnosis, management and monitoring of many diseases. However, it is an inherently slow imaging technique. Over the last 20 years, parallel imaging, temporal encoding and compressed sensing have enabled substantial speed-ups in the acquisition of MRI data, by accurately recovering missing lines of k-space data. However, clinical uptake of vastly accelerated acquisitions has been limited, in particular in compressed sensing, due to the time-consuming nature of the reconstructions and unnatural looking images. Following the success of machine learning in a wide range of imaging tasks, there has been a recent explosion in the use of machine learning in the field of MRI image reconstruction. A wide range of approaches have been proposed, which can be applied in k-space and/or image-space. Promising results have been demonstrated from a range of methods, enabling natural looking images and rapid computation. In this review article we summarize the current machine learning approaches used in MRI reconstruction, discuss their drawbacks, clinical applications, and current trends.