 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCausal-Copilot: An Autonomous Causal Analysis Agent
Apr 21, 2025Causal analysis plays a foundational role in scientific discovery and reliable decision-making, yet it remains largely inaccessible to domain experts due to its conceptual and algorithmic complexity. This disconnect between causal methodology and practical usability presents a dual challenge: domain experts are unable to leverage recent advances in causal learning, while causal researchers lack broad, real-world deployment to test and refine their methods. To address this, we introduce Causal-Copilot, an autonomous agent that operationalizes expert-level causal analysis within a large language model framework. Causal-Copilot automates the full pipeline of causal analysis for both tabular and time-series data -- including causal discovery, causal inference, algorithm selection, hyperparameter optimization, result interpretation, and generation of actionable insights. It supports interactive refinement through natural language, lowering the barrier for non-specialists while preserving methodological rigor. By integrating over 20 state-of-the-art causal analysis techniques, our system fosters a virtuous cycle -- expanding access to advanced causal methods for domain experts while generating rich, real-world applications that inform and advance causal theory. Empirical evaluations demonstrate that Causal-Copilot achieves superior performance compared to existing baselines, offering a reliable, scalable, and extensible solution that bridges the gap between theoretical sophistication and real-world applicability in causal analysis. A live interactive demo of Causal-Copilot is available at https://causalcopilot.com/.
Robustness to Label Noise Depends on the Shape of the Noise Distribution in Feature Space
Jun 02, 2022

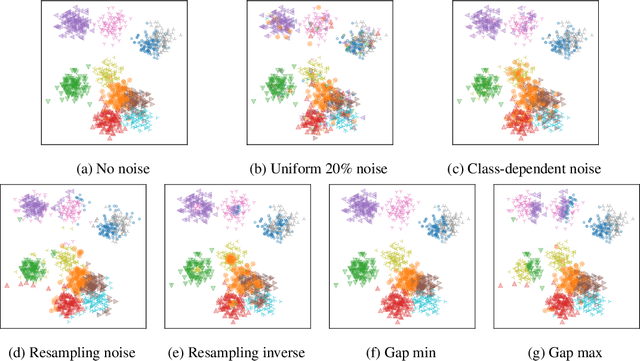
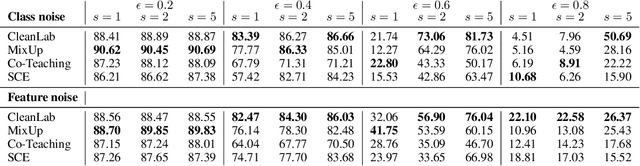
Machine learning classifiers have been demonstrated, both empirically and theoretically, to be robust to label noise under certain conditions -- notably the typical assumption is that label noise is independent of the features given the class label. We provide a theoretical framework that generalizes beyond this typical assumption by modeling label noise as a distribution over feature space. We show that both the scale and the shape of the noise distribution influence the posterior likelihood; and the shape of the noise distribution has a stronger impact on classification performance if the noise is concentrated in feature space where the decision boundary can be moved. For the special case of uniform label noise (independent of features and the class label), we show that the Bayes optimal classifier for $c$ classes is robust to label noise until the ratio of noisy samples goes above $\frac{c-1}{c}$ (e.g. 90% for 10 classes), which we call the tipping point. However, for the special case of class-dependent label noise (independent of features given the class label), the tipping point can be as low as 50%. Most importantly, we show that when the noise distribution targets decision boundaries (label noise is directly dependent on feature space), classification robustness can drop off even at a small scale of noise. Even when evaluating recent label-noise mitigation methods we see reduced accuracy when label noise is dependent on features. These findings explain why machine learning often handles label noise well if the noise distribution is uniform in feature-space; yet it also points to the difficulty of overcoming label noise when it is concentrated in a region of feature space where a decision boundary can move.
Analysis on Image Set Visual Question Answering
Mar 31, 2021
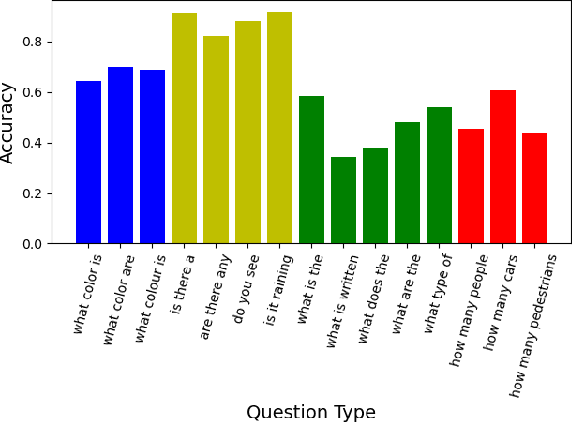
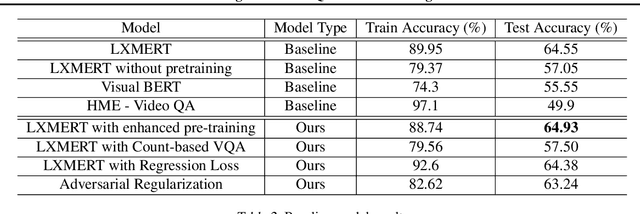

We tackle the challenge of Visual Question Answering in multi-image setting for the ISVQA dataset. Traditional VQA tasks have focused on a single-image setting where the target answer is generated from a single image. Image set VQA, however, comprises of a set of images and requires finding connection between images, relate the objects across images based on these connections and generate a unified answer. In this report, we work with 4 approaches in a bid to improve the performance on the task. We analyse and compare our results with three baseline models - LXMERT, HME-VideoQA and VisualBERT - and show that our approaches can provide a slight improvement over the baselines. In specific, we try to improve on the spatial awareness of the model and help the model identify color using enhanced pre-training, reduce language dependence using adversarial regularization, and improve counting using regression loss and graph based deduplication. We further delve into an in-depth analysis on the language bias in the ISVQA dataset and show how models trained on ISVQA implicitly learn to associate language more strongly with the final answer.
Zero-Shot Language Transfer vs Iterative Back Translation for Unsupervised Machine Translation
Mar 31, 2021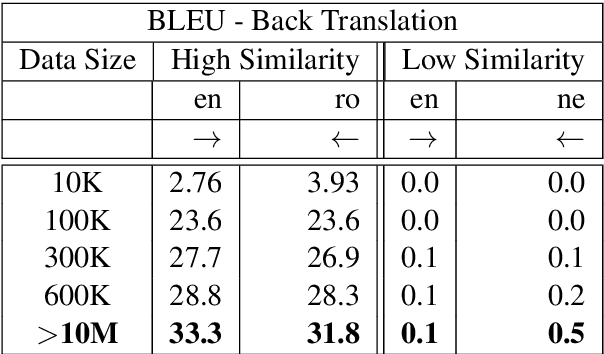

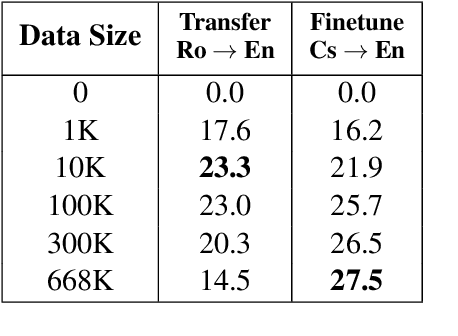
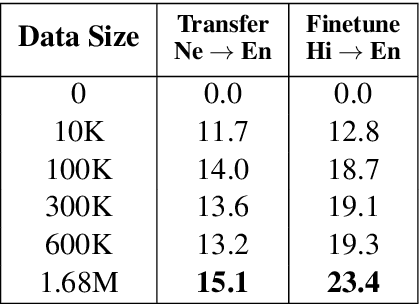
This work focuses on comparing different solutions for machine translation on low resource language pairs, namely, with zero-shot transfer learning and unsupervised machine translation. We discuss how the data size affects the performance of both unsupervised MT and transfer learning. Additionally we also look at how the domain of the data affects the result of unsupervised MT. The code to all the experiments performed in this project are accessible on Github.
Lexically-constrained Text Generation through Commonsense Knowledge Extraction and Injection
Dec 19, 2020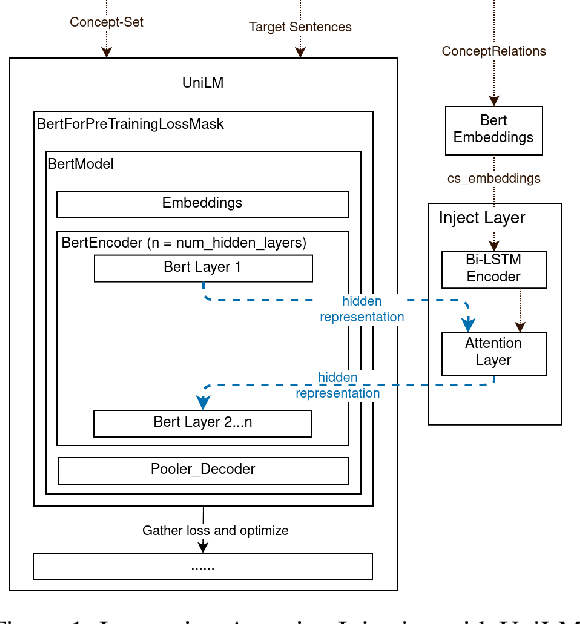


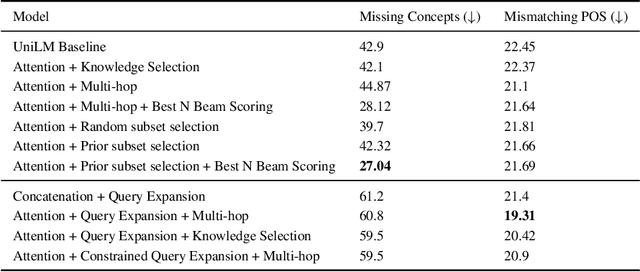
Conditional text generation has been a challenging task that is yet to see human-level performance from state-of-the-art models. In this work, we specifically focus on the Commongen benchmark, wherein the aim is to generate a plausible sentence for a given set of input concepts. Despite advances in other tasks, large pre-trained language models that are fine-tuned on this dataset often produce sentences that are syntactically correct but qualitatively deviate from a human understanding of common sense. Furthermore, generated sequences are unable to fulfill such lexical requirements as matching part-of-speech and full concept coverage. In this paper, we explore how commonsense knowledge graphs can enhance model performance, with respect to commonsense reasoning and lexically-constrained decoding. We propose strategies for enhancing the semantic correctness of the generated text, which we accomplish through: extracting commonsense relations from Conceptnet, injecting these relations into the Unified Language Model (UniLM) through attention mechanisms, and enforcing the aforementioned lexical requirements through output constraints. By performing several ablations, we find that commonsense injection enables the generation of sentences that are more aligned with human understanding, while remaining compliant with lexical requirements.