 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeX-VC: Zero-shot Streaming Voice Conversion in Codec Space
Apr 14, 2026Zero-shot voice conversion (VC) aims to convert a source utterance into the voice of an unseen target speaker while preserving its linguistic content. Although recent systems have improved conversion quality, building zero-shot VC systems for interactive scenarios remains challenging because high-fidelity speaker transfer and low-latency streaming inference are difficult to achieve simultaneously. In this work, we present X-VC, a zero-shot streaming VC system that performs one-step conversion in the latent space of a pretrained neural codec. X-VC uses a dual-conditioning acoustic converter that jointly models source codec latents and frame-level acoustic conditions derived from target reference speech, while injecting utterance-level target speaker information through adaptive normalization. To reduce the mismatch between training and inference, we train the model with generated paired data and a role-assignment strategy that combines standard, reconstruction, and reversed modes. For streaming inference, we further adopt a chunkwise inference scheme with overlap smoothing that is aligned with the segment-based training paradigm of the codec. Experiments on Seed-TTS-Eval show that X-VC achieves the best streaming WER in both English and Chinese, strong speaker similarity in same-language and cross-lingual settings, and substantially lower offline real-time factor than the compared baselines. These results suggest that codec-space one-step conversion is a practical approach for building high-quality low-latency zero-shot VC systems. Audio samples are available at https://x-vc.github.io. Our code and checkpoints will also be released.
LPM 1.0: Video-based Character Performance Model
Apr 09, 2026Performance, the externalization of intent, emotion, and personality through visual, vocal, and temporal behavior, is what makes a character alive. Learning such performance from video is a promising alternative to traditional 3D pipelines. However, existing video models struggle to jointly achieve high expressiveness, real-time inference, and long-horizon identity stability, a tension we call the performance trilemma. Conversation is the most comprehensive performance scenario, as characters simultaneously speak, listen, react, and emote while maintaining identity over time. To address this, we present LPM 1.0 (Large Performance Model), focusing on single-person full-duplex audio-visual conversational performance. Concretely, we build a multimodal human-centric dataset through strict filtering, speaking-listening audio-video pairing, performance understanding, and identity-aware multi-reference extraction; train a 17B-parameter Diffusion Transformer (Base LPM) for highly controllable, identity-consistent performance through multimodal conditioning; and distill it into a causal streaming generator (Online LPM) for low-latency, infinite-length interaction. At inference, given a character image with identity-aware references, LPM 1.0 generates listening videos from user audio and speaking videos from synthesized audio, with text prompts for motion control, all at real-time speed with identity-stable, infinite-length generation. LPM 1.0 thus serves as a visual engine for conversational agents, live streaming characters, and game NPCs. To systematically evaluate this setting, we propose LPM-Bench, the first benchmark for interactive character performance. LPM 1.0 achieves state-of-the-art results across all evaluated dimensions while maintaining real-time inference.
TS-MLLM: A Multi-Modal Large Language Model-based Framework for Industrial Time-Series Big Data Analysis
Mar 08, 2026Accurate analysis of industrial time-series big data is critical for the Prognostics and Health Management (PHM) of industrial equipment. While recent advancements in Large Language Models (LLMs) have shown promise in time-series analysis, existing methods typically focus on single-modality adaptations, failing to exploit the complementary nature of temporal signals, frequency-domain visual representations, and textual knowledge information. In this paper, we propose TS-MLLM, a unified multi-modal large language model framework designed to jointly model temporal signals, frequency-domain images, and textual domain knowledge. Specifically, we first develop an Industrial time-series Patch Modeling branch to capture long-range temporal dynamics. To integrate cross-modal priors, we introduce a Spectrum-aware Vision-Language Model Adaptation (SVLMA) mechanism that enables the model to internalize frequency-domain patterns and semantic context. Furthermore, a Temporal-centric Multi-modal Attention Fusion (TMAF) mechanism is designed to actively retrieve relevant visual and textual cues using temporal features as queries, ensuring deep cross-modal alignment. Extensive experiments on multiple industrial benchmarks demonstrate that TS-MLLM significantly outperforms state-of-the-art methods, particularly in few-shot and complex scenarios. The results validate our framework's superior robustness, efficiency, and generalization capabilities for industrial time-series prediction.
Explicit Discovery of Nonlinear Symmetries from Dynamic Data
Oct 02, 2025Symmetry is widely applied in problems such as the design of equivariant networks and the discovery of governing equations, but in complex scenarios, it is not known in advance. Most previous symmetry discovery methods are limited to linear symmetries, and recent attempts to discover nonlinear symmetries fail to explicitly get the Lie algebra subspace. In this paper, we propose LieNLSD, which is, to our knowledge, the first method capable of determining the number of infinitesimal generators with nonlinear terms and their explicit expressions. We specify a function library for the infinitesimal group action and aim to solve for its coefficient matrix, proving that its prolongation formula for differential equations, which governs dynamic data, is also linear with respect to the coefficient matrix. By substituting the central differences of the data and the Jacobian matrix of the trained neural network into the infinitesimal criterion, we get a system of linear equations for the coefficient matrix, which can then be solved using SVD. On top quark tagging and a series of dynamic systems, LieNLSD shows qualitative advantages over existing methods and improves the long rollout accuracy of neural PDE solvers by over 20% while applying to guide data augmentation. Code and data are available at https://github.com/hulx2002/LieNLSD.
Governing Equation Discovery from Data Based on Differential Invariants
May 24, 2025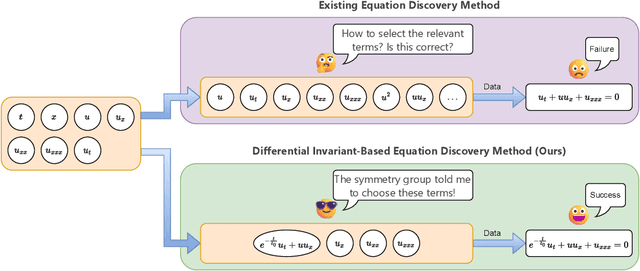

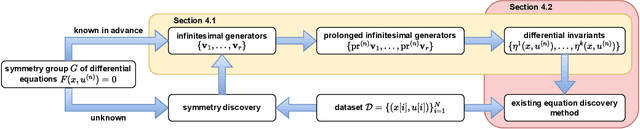
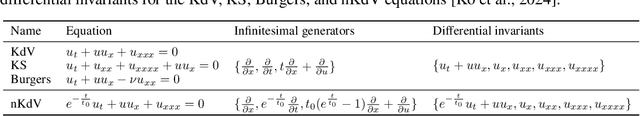
The explicit governing equation is one of the simplest and most intuitive forms for characterizing physical laws. However, directly discovering partial differential equations (PDEs) from data poses significant challenges, primarily in determining relevant terms from a vast search space. Symmetry, as a crucial prior knowledge in scientific fields, has been widely applied in tasks such as designing equivariant networks and guiding neural PDE solvers. In this paper, we propose a pipeline for governing equation discovery based on differential invariants, which can losslessly reduce the search space of existing equation discovery methods while strictly adhering to symmetry. Specifically, we compute the set of differential invariants corresponding to the infinitesimal generators of the symmetry group and select them as the relevant terms for equation discovery. Taking DI-SINDy (SINDy based on Differential Invariants) as an example, we demonstrate that its success rate and accuracy in PDE discovery surpass those of other symmetry-informed governing equation discovery methods across a series of PDEs.
High-Rank Irreducible Cartesian Tensor Decomposition and Bases of Equivariant Spaces
Dec 30, 2024



Irreducible Cartesian tensors (ICTs) play a crucial role in the design of equivariant graph neural networks, as well as in theoretical chemistry and chemical physics. Meanwhile, the design space of available linear operations on tensors that preserve symmetry presents a significant challenge. The ICT decomposition and a basis of this equivariant space are difficult to obtain for high-order tensors. After decades of research, we recently achieve an explicit ICT decomposition for $n=5$ \citep{bonvicini2024irreducible} with factorial time/space complexity. This work, for the first time, obtains decomposition matrices for ICTs up to rank $n=9$ with reduced and affordable complexity, by constructing what we call path matrices. The path matrices are obtained via performing chain-like contraction with Clebsch-Gordan matrices following the parentage scheme. We prove and leverage that the concatenation of path matrices is an orthonormal change-of-basis matrix between the Cartesian tensor product space and the spherical direct sum spaces. Furthermore, we identify a complete orthogonal basis for the equivariant space, rather than a spanning set \citep{pearce2023brauer}, through this path matrices technique. We further extend our result to the arbitrary tensor product and direct sum spaces, enabling free design between different spaces while keeping symmetry. The Python code is available in https://github.com/ShihaoShao-GH/ICT-decomposition-and-equivariant-bases where the $n=6,\dots,9$ ICT decomposition matrices are obtained in 1s, 3s, 11s, and 4m32s, respectively.
Free the Design Space of Equivariant Graph Neural Networks: High-Rank Irreducible Cartesian Tensor Decomposition and Bases of Equivariant Spaces
Dec 24, 2024Irreducible Cartesian tensors (ICTs) play a crucial role in the design of equivariant graph neural networks, as well as in theoretical chemistry and chemical physics. Meanwhile, the design space of available linear operations on tensors that preserve symmetry presents a significant challenge. The ICT decomposition and a basis of this equivariant space are difficult to obtain for high-order tensors. After decades of research, we recently achieve an explicit ICT decomposition for $n=5$ \citep{bonvicini2024irreducible} with factorial time/space complexity. This work, for the first time, obtains decomposition matrices for ICTs up to rank $n=9$ with reduced and affordable complexity, by constructing what we call path matrices. The path matrices are obtained via performing chain-like contraction with Clebsch-Gordan matrices following the parentage scheme. We prove and leverage that the concatenation of path matrices is an orthonormal change-of-basis matrix between the Cartesian tensor product space and the spherical direct sum spaces. Furthermore, we identify a complete orthogonal basis for the equivariant space, rather than a spanning set \citep{pearce2023brauer}, through this path matrices technique. We further extend our result to the arbitrary tensor product and direct sum spaces, enabling free design between different spaces while keeping symmetry. The Python code is available in the appendix where the $n=6,\dots,9$ ICT decomposition matrices are obtained in <0.1s, 0.5s, 1s, 3s, 11s, and 4m32s, respectively.
Symmetry Discovery for Different Data Types
Oct 13, 2024Equivariant neural networks incorporate symmetries into their architecture, achieving higher generalization performance. However, constructing equivariant neural networks typically requires prior knowledge of data types and symmetries, which is difficult to achieve in most tasks. In this paper, we propose LieSD, a method for discovering symmetries via trained neural networks which approximate the input-output mappings of the tasks. It characterizes equivariance and invariance (a special case of equivariance) of continuous groups using Lie algebra and directly solves the Lie algebra space through the inputs, outputs, and gradients of the trained neural network. Then, we extend the method to make it applicable to multi-channel data and tensor data, respectively. We validate the performance of LieSD on tasks with symmetries such as the two-body problem, the moment of inertia matrix prediction, and top quark tagging. Compared with the baseline, LieSD can accurately determine the number of Lie algebra bases without the need for expensive group sampling. Furthermore, LieSD can perform well on non-uniform datasets, whereas methods based on GANs fail.
Optimizing the Placement of Roadside LiDARs for Autonomous Driving
Oct 11, 2023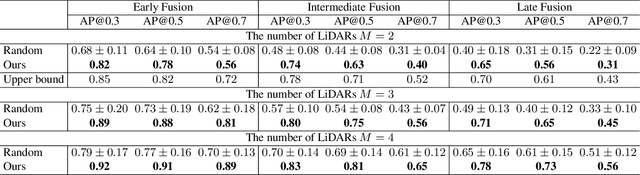
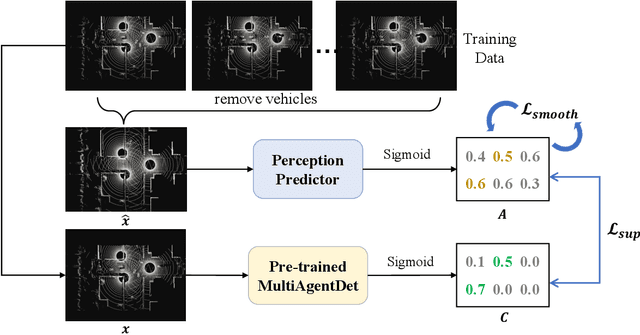
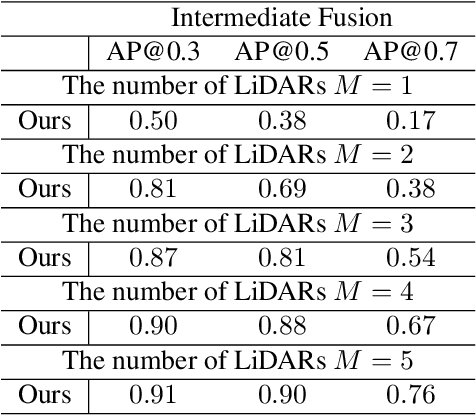

Multi-agent cooperative perception is an increasingly popular topic in the field of autonomous driving, where roadside LiDARs play an essential role. However, how to optimize the placement of roadside LiDARs is a crucial but often overlooked problem. This paper proposes an approach to optimize the placement of roadside LiDARs by selecting optimized positions within the scene for better perception performance. To efficiently obtain the best combination of locations, a greedy algorithm based on perceptual gain is proposed, which selects the location that can maximize the perceptual gain sequentially. We define perceptual gain as the increased perceptual capability when a new LiDAR is placed. To obtain the perception capability, we propose a perception predictor that learns to evaluate LiDAR placement using only a single point cloud frame. A dataset named Roadside-Opt is created using the CARLA simulator to facilitate research on the roadside LiDAR placement problem.
UniSeg: A Unified Multi-Modal LiDAR Segmentation Network and the OpenPCSeg Codebase
Sep 11, 2023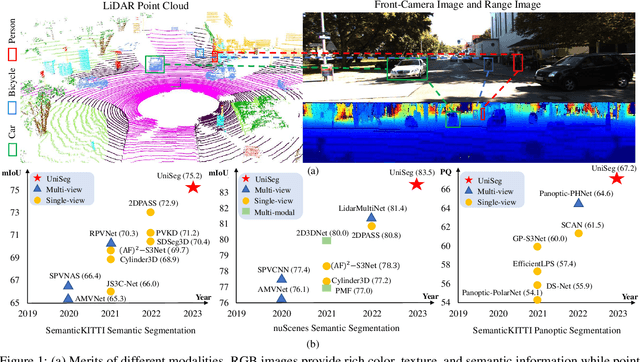

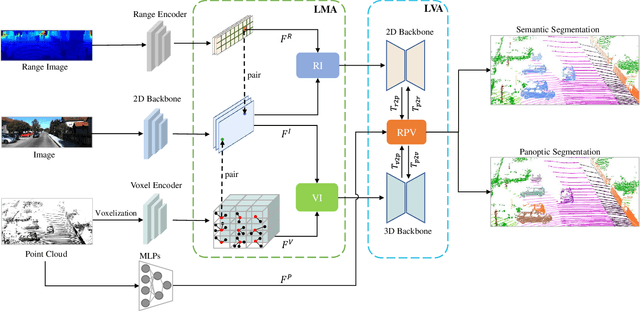
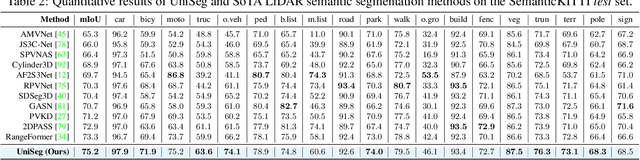
Point-, voxel-, and range-views are three representative forms of point clouds. All of them have accurate 3D measurements but lack color and texture information. RGB images are a natural complement to these point cloud views and fully utilizing the comprehensive information of them benefits more robust perceptions. In this paper, we present a unified multi-modal LiDAR segmentation network, termed UniSeg, which leverages the information of RGB images and three views of the point cloud, and accomplishes semantic segmentation and panoptic segmentation simultaneously. Specifically, we first design the Learnable cross-Modal Association (LMA) module to automatically fuse voxel-view and range-view features with image features, which fully utilize the rich semantic information of images and are robust to calibration errors. Then, the enhanced voxel-view and range-view features are transformed to the point space,where three views of point cloud features are further fused adaptively by the Learnable cross-View Association module (LVA). Notably, UniSeg achieves promising results in three public benchmarks, i.e., SemanticKITTI, nuScenes, and Waymo Open Dataset (WOD); it ranks 1st on two challenges of two benchmarks, including the LiDAR semantic segmentation challenge of nuScenes and panoptic segmentation challenges of SemanticKITTI. Besides, we construct the OpenPCSeg codebase, which is the largest and most comprehensive outdoor LiDAR segmentation codebase. It contains most of the popular outdoor LiDAR segmentation algorithms and provides reproducible implementations. The OpenPCSeg codebase will be made publicly available at https://github.com/PJLab-ADG/PCSeg.