 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKimi K2.5: Visual Agentic Intelligence
Feb 02, 2026We introduce Kimi K2.5, an open-source multimodal agentic model designed to advance general agentic intelligence. K2.5 emphasizes the joint optimization of text and vision so that two modalities enhance each other. This includes a series of techniques such as joint text-vision pre-training, zero-vision SFT, and joint text-vision reinforcement learning. Building on this multimodal foundation, K2.5 introduces Agent Swarm, a self-directed parallel agent orchestration framework that dynamically decomposes complex tasks into heterogeneous sub-problems and executes them concurrently. Extensive evaluations show that Kimi K2.5 achieves state-of-the-art results across various domains including coding, vision, reasoning, and agentic tasks. Agent Swarm also reduces latency by up to $4.5\times$ over single-agent baselines. We release the post-trained Kimi K2.5 model checkpoint to facilitate future research and real-world applications of agentic intelligence.
Perceptual Ratings Predict Speech Inversion Articulatory Kinematics in Childhood Speech Sound Disorders
Jul 02, 2025



Purpose: This study evaluated whether articulatory kinematics, inferred by Articulatory Phonology speech inversion neural networks, aligned with perceptual ratings of /r/ and /s/ in the speech of children with speech sound disorders. Methods: Articulatory Phonology vocal tract variables were inferred for 5,961 utterances from 118 children and 3 adults, aged 2.25-45 years. Perceptual ratings were standardized using the novel 5-point PERCEPT Rating Scale and training protocol. Two research questions examined if the articulatory patterns of inferred vocal tract variables aligned with the perceptual error category for the phones investigated (e.g., tongue tip is more anterior in dentalized /s/ productions than in correct /s/). A third research question examined if gradient PERCEPT Rating Scale scores predicted articulatory proximity to correct productions. Results: Estimated marginal means from linear mixed models supported 17 of 18 /r/ hypotheses, involving tongue tip and tongue body constrictions. For /s/, estimated marginal means from a second linear mixed model supported 7 of 15 hypotheses, particularly those related to the tongue tip. A third linear mixed model revealed that PERCEPT Rating Scale scores significantly predicted articulatory proximity of errored phones to correct productions. Conclusion: Inferred vocal tract variables differentiated category and magnitude of articulatory errors for /r/, and to a lesser extent for /s/, aligning with perceptual judgments. These findings support the clinical interpretability of speech inversion vocal tract variables and the PERCEPT Rating Scale in quantifying articulatory proximity to the target sound, particularly for /r/.
Kimi-VL Technical Report
Apr 10, 2025



We present Kimi-VL, an efficient open-source Mixture-of-Experts (MoE) vision-language model (VLM) that offers advanced multimodal reasoning, long-context understanding, and strong agent capabilities - all while activating only 2.8B parameters in its language decoder (Kimi-VL-A3B). Kimi-VL demonstrates strong performance across challenging domains: as a general-purpose VLM, Kimi-VL excels in multi-turn agent tasks (e.g., OSWorld), matching flagship models. Furthermore, it exhibits remarkable capabilities across diverse challenging vision language tasks, including college-level image and video comprehension, OCR, mathematical reasoning, and multi-image understanding. In comparative evaluations, it effectively competes with cutting-edge efficient VLMs such as GPT-4o-mini, Qwen2.5-VL-7B, and Gemma-3-12B-IT, while surpassing GPT-4o in several key domains. Kimi-VL also advances in processing long contexts and perceiving clearly. With a 128K extended context window, Kimi-VL can process diverse long inputs, achieving impressive scores of 64.5 on LongVideoBench and 35.1 on MMLongBench-Doc. Its native-resolution vision encoder, MoonViT, further allows it to see and understand ultra-high-resolution visual inputs, achieving 83.2 on InfoVQA and 34.5 on ScreenSpot-Pro, while maintaining lower computational cost for common tasks. Building upon Kimi-VL, we introduce an advanced long-thinking variant: Kimi-VL-Thinking. Developed through long chain-of-thought (CoT) supervised fine-tuning (SFT) and reinforcement learning (RL), this model exhibits strong long-horizon reasoning capabilities. It achieves scores of 61.7 on MMMU, 36.8 on MathVision, and 71.3 on MathVista while maintaining the compact 2.8B activated LLM parameters, setting a new standard for efficient multimodal thinking models. Code and models are publicly accessible at https://github.com/MoonshotAI/Kimi-VL.
Perfecting Imperfect Physical Neural Networks with Transferable Robustness using Sharpness-Aware Training
Nov 19, 2024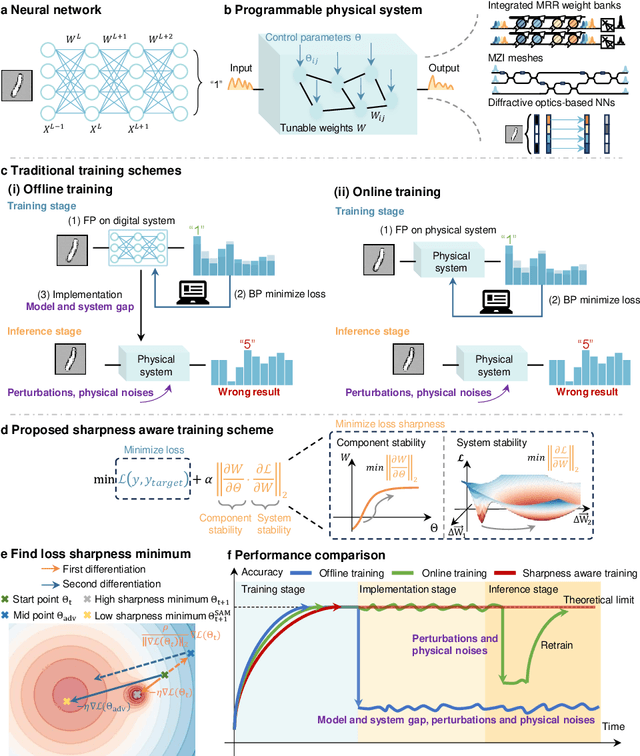
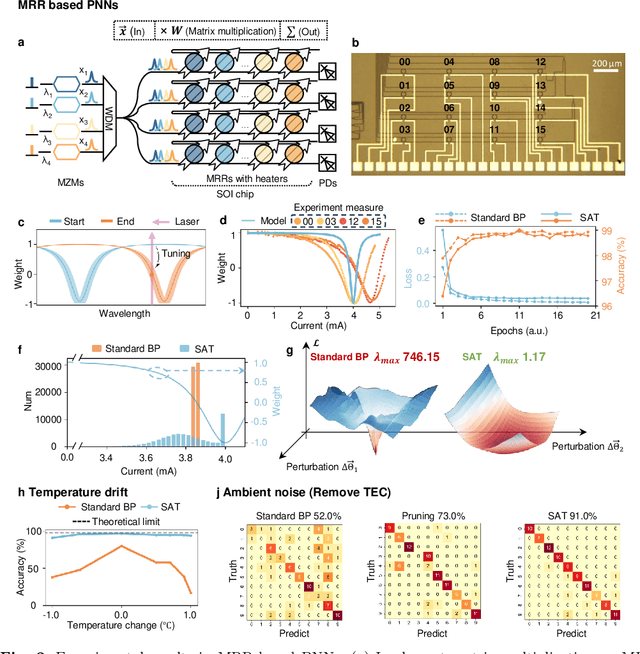
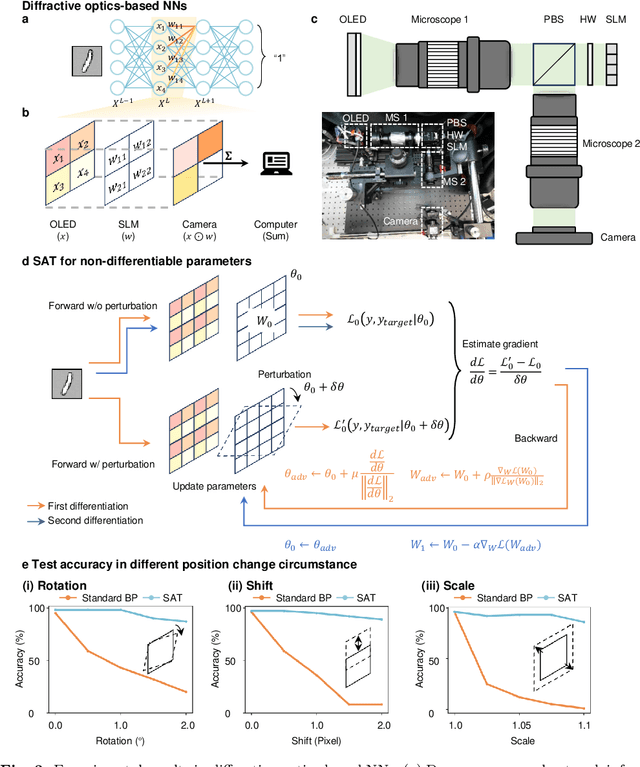
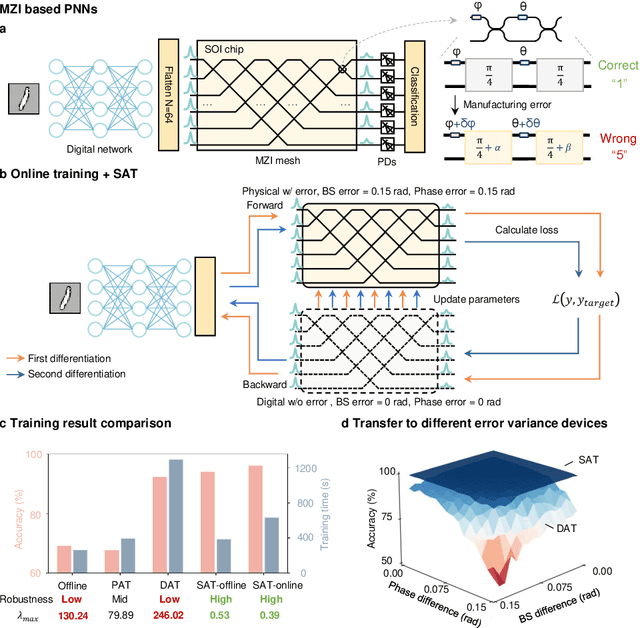
AI models are essential in science and engineering, but recent advances are pushing the limits of traditional digital hardware. To address these limitations, physical neural networks (PNNs), which use physical substrates for computation, have gained increasing attention. However, developing effective training methods for PNNs remains a significant challenge. Current approaches, regardless of offline and online training, suffer from significant accuracy loss. Offline training is hindered by imprecise modeling, while online training yields device-specific models that can't be transferred to other devices due to manufacturing variances. Both methods face challenges from perturbations after deployment, such as thermal drift or alignment errors, which make trained models invalid and require retraining. Here, we address the challenges with both offline and online training through a novel technique called Sharpness-Aware Training (SAT), where we innovatively leverage the geometry of the loss landscape to tackle the problems in training physical systems. SAT enables accurate training using efficient backpropagation algorithms, even with imprecise models. PNNs trained by SAT offline even outperform those trained online, despite modeling and fabrication errors. SAT also overcomes online training limitations by enabling reliable transfer of models between devices. Finally, SAT is highly resilient to perturbations after deployment, allowing PNNs to continuously operate accurately under perturbations without retraining. We demonstrate SAT across three types of PNNs, showing it is universally applicable, regardless of whether the models are explicitly known. This work offers a transformative, efficient approach to training PNNs, addressing critical challenges in analog computing and enabling real-world deployment.
StreetSurf: Extending Multi-view Implicit Surface Reconstruction to Street Views
Jun 08, 2023



We present a novel multi-view implicit surface reconstruction technique, termed StreetSurf, that is readily applicable to street view images in widely-used autonomous driving datasets, such as Waymo-perception sequences, without necessarily requiring LiDAR data. As neural rendering research expands rapidly, its integration into street views has started to draw interests. Existing approaches on street views either mainly focus on novel view synthesis with little exploration of the scene geometry, or rely heavily on dense LiDAR data when investigating reconstruction. Neither of them investigates multi-view implicit surface reconstruction, especially under settings without LiDAR data. Our method extends prior object-centric neural surface reconstruction techniques to address the unique challenges posed by the unbounded street views that are captured with non-object-centric, long and narrow camera trajectories. We delimit the unbounded space into three parts, close-range, distant-view and sky, with aligned cuboid boundaries, and adapt cuboid/hyper-cuboid hash-grids along with road-surface initialization scheme for finer and disentangled representation. To further address the geometric errors arising from textureless regions and insufficient viewing angles, we adopt geometric priors that are estimated using general purpose monocular models. Coupled with our implementation of efficient and fine-grained multi-stage ray marching strategy, we achieve state of the art reconstruction quality in both geometry and appearance within only one to two hours of training time with a single RTX3090 GPU for each street view sequence. Furthermore, we demonstrate that the reconstructed implicit surfaces have rich potential for various downstream tasks, including ray tracing and LiDAR simulation.
Discovering A Variety of Objects in Spatio-Temporal Human-Object Interactions
Nov 18, 2022


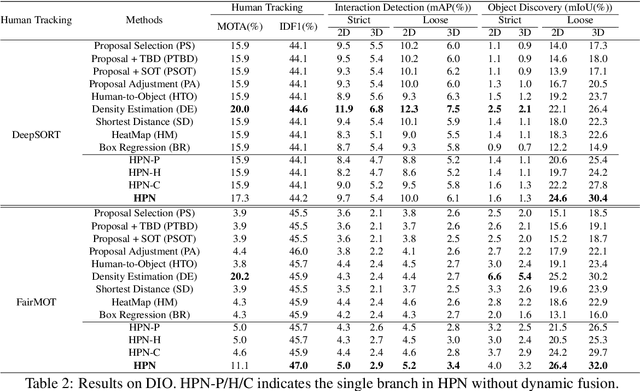
Spatio-temporal Human-Object Interaction (ST-HOI) detection aims at detecting HOIs from videos, which is crucial for activity understanding. In daily HOIs, humans often interact with a variety of objects, e.g., holding and touching dozens of household items in cleaning. However, existing whole body-object interaction video benchmarks usually provide limited object classes. Here, we introduce a new benchmark based on AVA: Discovering Interacted Objects (DIO) including 51 interactions and 1,000+ objects. Accordingly, an ST-HOI learning task is proposed expecting vision systems to track human actors, detect interactions and simultaneously discover interacted objects. Even though today's detectors/trackers excel in object detection/tracking tasks, they perform unsatisfied to localize diverse/unseen objects in DIO. This profoundly reveals the limitation of current vision systems and poses a great challenge. Thus, how to leverage spatio-temporal cues to address object discovery is explored, and a Hierarchical Probe Network (HPN) is devised to discover interacted objects utilizing hierarchical spatio-temporal human/context cues. In extensive experiments, HPN demonstrates impressive performance. Data and code are available at https://github.com/DirtyHarryLYL/HAKE-AVA.
AGENT: An Adaptive Grouping Entrapping Method of Flocking Systems
Jun 25, 2022



This study proposes a distributed algorithm that makes agents' adaptive grouping entrap multiple targets via automatic decision making, smooth flocking, and well-distributed entrapping. Agents make their own decisions about which targets to surround based on environmental information. An improved artificial potential field method is proposed to enable agents to smoothly and naturally change the formation to adapt to the environment. The proposed strategies guarantee that the coordination of swarm agents develops the phenomenon of multiple targets entrapping at the swarm level. We validate the performance of the proposed method using simulation experiments and design indicators for the analysis of these simulation and physical experiments.
ActFormer: A GAN Transformer Framework towards General Action-Conditioned 3D Human Motion Generation
Mar 15, 2022



We present a GAN Transformer framework for general action-conditioned 3D human motion generation, including not only single-person actions but also multi-person interactive actions. Our approach consists of a powerful Action-conditioned motion transFormer (ActFormer) under a GAN training scheme, equipped with a Gaussian Process latent prior. Such a design combines the strong spatio-temporal representation capacity of Transformer, superiority in generative modeling of GAN, and inherent temporal correlations from latent prior. Furthermore, ActFormer can be naturally extended to multi-person motions by alternately modeling temporal correlations and human interactions with Transformer encoders. We validate our approach by comparison with other methods on larger-scale benchmarks, including NTU RGB+D 120 and BABEL. We also introduce a new synthetic dataset of complex multi-person combat behaviors to facilitate research on multi-person motion generation. Our method demonstrates adaptability to various human motion representations and achieves leading performance over SOTA methods on both single-person and multi-person motion generation tasks, indicating a hopeful step towards a universal human motion generator.
Regularity Learning via Explicit Distribution Modeling for Skeletal Video Anomaly Detection
Dec 08, 2021



Anomaly detection in surveillance videos is challenging and important for ensuring public security. Different from pixel-based anomaly detection methods, pose-based methods utilize highly-structured skeleton data, which decreases the computational burden and also avoids the negative impact of background noise. However, unlike pixel-based methods, which could directly exploit explicit motion features such as optical flow, pose-based methods suffer from the lack of alternative dynamic representation. In this paper, a novel Motion Embedder (ME) is proposed to provide a pose motion representation from the probability perspective. Furthermore, a novel task-specific Spatial-Temporal Transformer (STT) is deployed for self-supervised pose sequence reconstruction. These two modules are then integrated into a unified framework for pose regularity learning, which is referred to as Motion Prior Regularity Learner (MoPRL). MoPRL achieves the state-of-the-art performance by an average improvement of 4.7% AUC on several challenging datasets. Extensive experiments validate the versatility of each proposed module.
Transferable Knowledge-Based Multi-Granularity Aggregation Network for Temporal Action Localization: Submission to ActivityNet Challenge 2021
Jul 27, 2021



This technical report presents an overview of our solution used in the submission to 2021 HACS Temporal Action Localization Challenge on both Supervised Learning Track and Weakly-Supervised Learning Track. Temporal Action Localization (TAL) requires to not only precisely locate the temporal boundaries of action instances, but also accurately classify the untrimmed videos into specific categories. However, Weakly-Supervised TAL indicates locating the action instances using only video-level class labels. In this paper, to train a supervised temporal action localizer, we adopt Temporal Context Aggregation Network (TCANet) to generate high-quality action proposals through ``local and global" temporal context aggregation and complementary as well as progressive boundary refinement. As for the WSTAL, a novel framework is proposed to handle the poor quality of CAS generated by simple classification network, which can only focus on local discriminative parts, rather than locate the entire interval of target actions. Further inspired by the transfer learning method, we also adopt an additional module to transfer the knowledge from trimmed videos (HACS Clips dataset) to untrimmed videos (HACS Segments dataset), aiming at promoting the classification performance on untrimmed videos. Finally, we employ a boundary regression module embedded with Outer-Inner-Contrastive (OIC) loss to automatically predict the boundaries based on the enhanced CAS. Our proposed scheme achieves 39.91 and 29.78 average mAP on the challenge testing set of supervised and weakly-supervised temporal action localization track respectively.