 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDexterous Manipulation Based on Prior Dexterous Grasp Pose Knowledge
Dec 20, 2024Dexterous manipulation has received considerable attention in recent research. Predominantly, existing studies have concentrated on reinforcement learning methods to address the substantial degrees of freedom in hand movements. Nonetheless, these methods typically suffer from low efficiency and accuracy. In this work, we introduce a novel reinforcement learning approach that leverages prior dexterous grasp pose knowledge to enhance both efficiency and accuracy. Unlike previous work, they always make the robotic hand go with a fixed dexterous grasp pose, We decouple the manipulation process into two distinct phases: initially, we generate a dexterous grasp pose targeting the functional part of the object; after that, we employ reinforcement learning to comprehensively explore the environment. Our findings suggest that the majority of learning time is expended in identifying the appropriate initial position and selecting the optimal manipulation viewpoint. Experimental results demonstrate significant improvements in learning efficiency and success rates across four distinct tasks.
Regularity Learning via Explicit Distribution Modeling for Skeletal Video Anomaly Detection
Dec 08, 2021



Anomaly detection in surveillance videos is challenging and important for ensuring public security. Different from pixel-based anomaly detection methods, pose-based methods utilize highly-structured skeleton data, which decreases the computational burden and also avoids the negative impact of background noise. However, unlike pixel-based methods, which could directly exploit explicit motion features such as optical flow, pose-based methods suffer from the lack of alternative dynamic representation. In this paper, a novel Motion Embedder (ME) is proposed to provide a pose motion representation from the probability perspective. Furthermore, a novel task-specific Spatial-Temporal Transformer (STT) is deployed for self-supervised pose sequence reconstruction. These two modules are then integrated into a unified framework for pose regularity learning, which is referred to as Motion Prior Regularity Learner (MoPRL). MoPRL achieves the state-of-the-art performance by an average improvement of 4.7% AUC on several challenging datasets. Extensive experiments validate the versatility of each proposed module.
Learning Pose Grammar to Encode Human Body Configuration for 3D Pose Estimation
Jan 04, 2018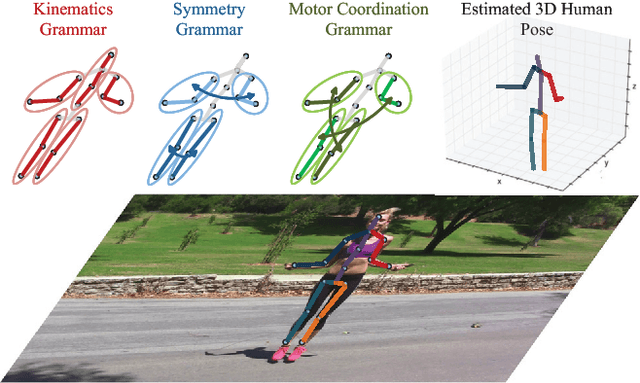
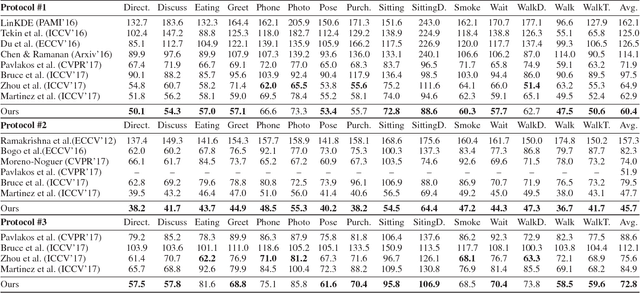
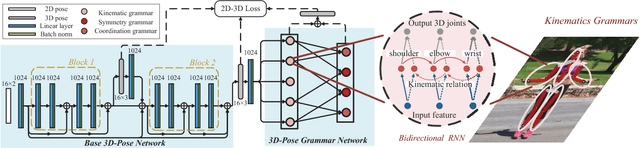
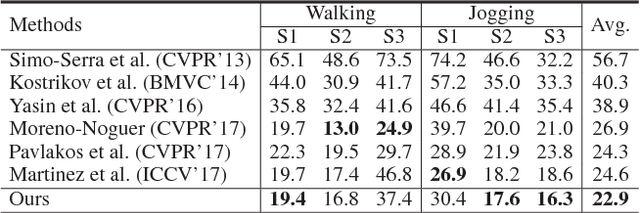
In this paper, we propose a pose grammar to tackle the problem of 3D human pose estimation. Our model directly takes 2D pose as input and learns a generalized 2D-3D mapping function. The proposed model consists of a base network which efficiently captures pose-aligned features and a hierarchy of Bi-directional RNNs (BRNN) on the top to explicitly incorporate a set of knowledge regarding human body configuration (i.e., kinematics, symmetry, motor coordination). The proposed model thus enforces high-level constraints over human poses. In learning, we develop a pose sample simulator to augment training samples in virtual camera views, which further improves our model generalizability. We validate our method on public 3D human pose benchmarks and propose a new evaluation protocol working on cross-view setting to verify the generalization capability of different methods. We empirically observe that most state-of-the-art methods encounter difficulty under such setting while our method can well handle such challenges.