 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEgo2Web: A Web Agent Benchmark Grounded in Egocentric Videos
Mar 23, 2026Multimodal AI agents are increasingly automating complex real-world workflows that involve online web execution. However, current web-agent benchmarks suffer from a critical limitation: they focus entirely on web-based interaction and perception, lacking grounding in the user's real-world physical surroundings. This limitation prevents evaluation in crucial scenarios, such as when an agent must use egocentric visual perception (e.g., via AR glasses) to recognize an object in the user's surroundings and then complete a related task online. To address this gap, we introduce Ego2Web, the first benchmark designed to bridge egocentric video perception and web agent execution. Ego2Web pairs real-world first-person video recordings with web tasks that require visual understanding, web task planning, and interaction in an online environment for successful completion. We utilize an automatic data-generation pipeline combined with human verification and refinement to curate well-constructed, high-quality video-task pairs across diverse web task types, including e-commerce, media retrieval, knowledge lookup, etc. To facilitate accurate and scalable evaluation for our benchmark, we also develop a novel LLM-as-a-Judge automatic evaluation method, Ego2WebJudge, which achieves approximately 84% agreement with human judgment, substantially higher than existing evaluation methods. Experiments with diverse SoTA agents on our Ego2Web show that their performance is weak, with substantial headroom across all task categories. We also conduct a comprehensive ablation study on task design, highlighting the necessity of accurate video understanding in the proposed task and the limitations of current agents. We hope Ego2Web can be a critical new resource for developing truly capable AI assistants that can seamlessly see, understand, and act across the physical and digital worlds.
VisionCoach: Reinforcing Grounded Video Reasoning via Visual-Perception Prompting
Mar 15, 2026Video reasoning requires models to locate and track question-relevant evidence across frames. While reinforcement learning (RL) with verifiable rewards improves accuracy, it still struggles to achieve reliable spatio-temporal grounding during the reasoning process. Moreover, improving grounding typically relies on scaled training data or inference-time perception tools, which increases annotation cost or computational cost. To address this challenge, we propose VisonCoach, an input-adaptive RL framework that improves spatio-temporal grounding through visual prompting as training-time guidance. During RL training, visual prompts are selectively applied to challenging inputs to amplify question-relevant evidence and suppress distractors. The model then internalizes these improvements through self-distillation, enabling grounded reasoning directly on raw videos without visual prompting at inference. VisonCoach consists of two components: (1) Visual Prompt Selector, which predicts appropriate prompt types conditioned on the video and question, and (2) Spatio-Temporal Reasoner, optimized with RL under visual prompt guidance and object-aware grounding rewards that enforce object identity consistency and multi-region bounding-box overlap. Extensive experiments demonstrate that VisonCoach achieves state-of-the-art performance under comparable settings, across diverse video reasoning, video understanding, and temporal grounding benchmarks (V-STAR, VideoMME, World-Sense, VideoMMMU, PerceptionTest, and Charades-STA), while maintaining a single efficient inference pathway without external tools. Our results show that visual prompting during training improves grounded video reasoning, while self-distillation enables the model to internalize this ability without requiring prompts at inference time.
Balancing Faithfulness and Performance in Reasoning via Multi-Listener Soft Execution
Feb 18, 2026Chain-of-thought (CoT) reasoning sometimes fails to faithfully reflect the true computation of a large language model (LLM), hampering its utility in explaining how LLMs arrive at their answers. Moreover, optimizing for faithfulness and interpretability in reasoning often degrades task performance. To address this tradeoff and improve CoT faithfulness, we propose Reasoning Execution by Multiple Listeners (REMUL), a multi-party reinforcement learning approach. REMUL builds on the hypothesis that reasoning traces which other parties can follow will be more faithful. A speaker model generates a reasoning trace, which is truncated and passed to a pool of listener models who "execute" the trace, continuing the trace to an answer. Speakers are rewarded for producing reasoning that is clear to listeners, with additional correctness regularization via masked supervised finetuning to counter the tradeoff between faithfulness and performance. On multiple reasoning benchmarks (BIG-Bench Extra Hard, MuSR, ZebraLogicBench, and FOLIO), REMUL consistently and substantially improves three measures of faithfulness -- hint attribution, early answering area over the curve (AOC), and mistake injection AOC -- while also improving accuracy. Our analysis finds that these gains are robust across training domains, translate to legibility gains, and are associated with shorter and more direct CoTs.
When and How Much to Imagine: Adaptive Test-Time Scaling with World Models for Visual Spatial Reasoning
Feb 09, 2026Despite rapid progress in Multimodal Large Language Models (MLLMs), visual spatial reasoning remains unreliable when correct answers depend on how a scene would appear under unseen or alternative viewpoints. Recent work addresses this by augmenting reasoning with world models for visual imagination, but questions such as when imagination is actually necessary, how much of it is beneficial, and when it becomes harmful, remain poorly understood. In practice, indiscriminate imagination can increase computation and even degrade performance by introducing misleading evidence. In this work, we present an in-depth analysis of test-time visual imagination as a controllable resource for spatial reasoning. We study when static visual evidence is sufficient, when imagination improves reasoning, and how excessive or unnecessary imagination affects accuracy and efficiency. To support this analysis, we introduce AVIC, an adaptive test-time framework with world models that explicitly reasons about the sufficiency of current visual evidence before selectively invoking and scaling visual imagination. Across spatial reasoning benchmarks (SAT, MMSI) and an embodied navigation benchmark (R2R), our results reveal clear scenarios where imagination is critical, marginal, or detrimental, and show that selective control can match or outperform fixed imagination strategies with substantially fewer world-model calls and language tokens. Overall, our findings highlight the importance of analyzing and controlling test-time imagination for efficient and reliable spatial reasoning.
Video-RTS: Rethinking Reinforcement Learning and Test-Time Scaling for Efficient and Enhanced Video Reasoning
Jul 09, 2025Despite advances in reinforcement learning (RL)-based video reasoning with large language models (LLMs), data collection and finetuning remain significant challenges. These methods often rely on large-scale supervised fine-tuning (SFT) with extensive video data and long Chain-of-Thought (CoT) annotations, making them costly and hard to scale. To address this, we present Video-RTS, a new approach to improve video reasoning capability with drastically improved data efficiency by combining data-efficient RL with a video-adaptive test-time scaling (TTS) strategy. Based on observations about the data scaling of RL samples, we skip the resource-intensive SFT step and employ efficient pure-RL training with output-based rewards, requiring no additional annotations or extensive fine-tuning. Furthermore, to utilize computational resources more efficiently, we introduce a sparse-to-dense video TTS strategy that improves inference by iteratively adding frames based on output consistency. We validate our approach on multiple video reasoning benchmarks, showing that Video-RTS surpasses existing video reasoning models by an average of 2.4% in accuracy using only 3.6% training samples. For example, Video-RTS achieves a 4.2% improvement on Video-Holmes, a recent and challenging video reasoning benchmark, and a 2.6% improvement on MMVU. Notably, our pure RL training and adaptive video TTS offer complementary strengths, enabling Video-RTS's strong reasoning performance.
4D-LRM: Large Space-Time Reconstruction Model From and To Any View at Any Time
Jun 23, 2025Can we scale 4D pretraining to learn general space-time representations that reconstruct an object from a few views at some times to any view at any time? We provide an affirmative answer with 4D-LRM, the first large-scale 4D reconstruction model that takes input from unconstrained views and timestamps and renders arbitrary novel view-time combinations. Unlike prior 4D approaches, e.g., optimization-based, geometry-based, or generative, that struggle with efficiency, generalization, or faithfulness, 4D-LRM learns a unified space-time representation and directly predicts per-pixel 4D Gaussian primitives from posed image tokens across time, enabling fast, high-quality rendering at, in principle, infinite frame rate. Our results demonstrate that scaling spatiotemporal pretraining enables accurate and efficient 4D reconstruction. We show that 4D-LRM generalizes to novel objects, interpolates across time, and handles diverse camera setups. It reconstructs 24-frame sequences in one forward pass with less than 1.5 seconds on a single A100 GPU.
Movie Facts and Fibs (MF$^2$): A Benchmark for Long Movie Understanding
Jun 06, 2025Despite recent progress in vision-language models (VLMs), holistic understanding of long-form video content remains a significant challenge, partly due to limitations in current benchmarks. Many focus on peripheral, ``needle-in-a-haystack'' details, encouraging context-insensitive retrieval over deep comprehension. Others rely on large-scale, semi-automatically generated questions (often produced by language models themselves) that are easier for models to answer but fail to reflect genuine understanding. In this paper, we introduce MF$^2$, a new benchmark for evaluating whether models can comprehend, consolidate, and recall key narrative information from full-length movies (50-170 minutes long). MF$^2$ includes over 50 full-length, open-licensed movies, each paired with manually constructed sets of claim pairs -- one true (fact) and one plausible but false (fib), totalling over 850 pairs. These claims target core narrative elements such as character motivations and emotions, causal chains, and event order, and refer to memorable moments that humans can recall without rewatching the movie. Instead of multiple-choice formats, we adopt a binary claim evaluation protocol: for each pair, models must correctly identify both the true and false claims. This reduces biases like answer ordering and enables a more precise assessment of reasoning. Our experiments demonstrate that both open-weight and closed state-of-the-art models fall well short of human performance, underscoring the relative ease of the task for humans and their superior ability to retain and reason over critical narrative information -- an ability current VLMs lack.
Training-free Guidance in Text-to-Video Generation via Multimodal Planning and Structured Noise Initialization
Apr 11, 2025Recent advancements in text-to-video (T2V) diffusion models have significantly enhanced the visual quality of the generated videos. However, even recent T2V models find it challenging to follow text descriptions accurately, especially when the prompt requires accurate control of spatial layouts or object trajectories. A recent line of research uses layout guidance for T2V models that require fine-tuning or iterative manipulation of the attention map during inference time. This significantly increases the memory requirement, making it difficult to adopt a large T2V model as a backbone. To address this, we introduce Video-MSG, a training-free Guidance method for T2V generation based on Multimodal planning and Structured noise initialization. Video-MSG consists of three steps, where in the first two steps, Video-MSG creates Video Sketch, a fine-grained spatio-temporal plan for the final video, specifying background, foreground, and object trajectories, in the form of draft video frames. In the last step, Video-MSG guides a downstream T2V diffusion model with Video Sketch through noise inversion and denoising. Notably, Video-MSG does not need fine-tuning or attention manipulation with additional memory during inference time, making it easier to adopt large T2V models. Video-MSG demonstrates its effectiveness in enhancing text alignment with multiple T2V backbones (VideoCrafter2 and CogVideoX-5B) on popular T2V generation benchmarks (T2VCompBench and VBench). We provide comprehensive ablation studies about noise inversion ratio, different background generators, background object detection, and foreground object segmentation.
VEGGIE: Instructional Editing and Reasoning of Video Concepts with Grounded Generation
Mar 19, 2025Recent video diffusion models have enhanced video editing, but it remains challenging to handle instructional editing and diverse tasks (e.g., adding, removing, changing) within a unified framework. In this paper, we introduce VEGGIE, a Video Editor with Grounded Generation from Instructions, a simple end-to-end framework that unifies video concept editing, grounding, and reasoning based on diverse user instructions. Specifically, given a video and text query, VEGGIE first utilizes an MLLM to interpret user intentions in instructions and ground them to the video contexts, generating frame-specific grounded task queries for pixel-space responses. A diffusion model then renders these plans and generates edited videos that align with user intent. To support diverse tasks and complex instructions, we employ a curriculum learning strategy: first aligning the MLLM and video diffusion model with large-scale instructional image editing data, followed by end-to-end fine-tuning on high-quality multitask video data. Additionally, we introduce a novel data synthesis pipeline to generate paired instructional video editing data for model training. It transforms static image data into diverse, high-quality video editing samples by leveraging Image-to-Video models to inject dynamics. VEGGIE shows strong performance in instructional video editing with different editing skills, outperforming the best instructional baseline as a versatile model, while other models struggle with multi-tasking. VEGGIE also excels in video object grounding and reasoning segmentation, where other baselines fail. We further reveal how the multiple tasks help each other and highlight promising applications like zero-shot multimodal instructional and in-context video editing.
Bootstrapping Language-Guided Navigation Learning with Self-Refining Data Flywheel
Dec 11, 2024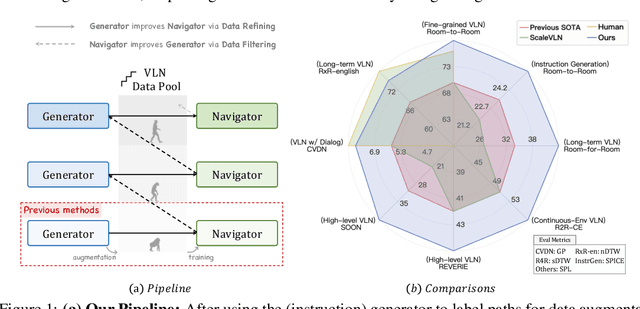
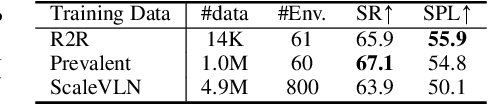
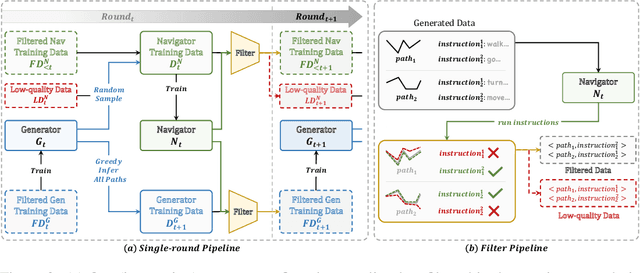
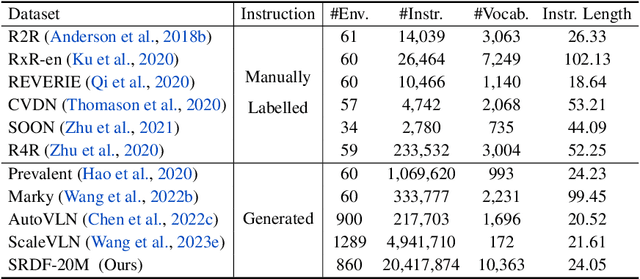
Creating high-quality data for training robust language-instructed agents is a long-lasting challenge in embodied AI. In this paper, we introduce a Self-Refining Data Flywheel (SRDF) that generates high-quality and large-scale navigational instruction-trajectory pairs by iteratively refining the data pool through the collaboration between two models, the instruction generator and the navigator, without any human-in-the-loop annotation. Specifically, SRDF starts with using a base generator to create an initial data pool for training a base navigator, followed by applying the trained navigator to filter the data pool. This leads to higher-fidelity data to train a better generator, which can, in turn, produce higher-quality data for training the next-round navigator. Such a flywheel establishes a data self-refining process, yielding a continuously improved and highly effective dataset for large-scale language-guided navigation learning. Our experiments demonstrate that after several flywheel rounds, the navigator elevates the performance boundary from 70% to 78% SPL on the classic R2R test set, surpassing human performance (76%) for the first time. Meanwhile, this process results in a superior generator, evidenced by a SPICE increase from 23.5 to 26.2, better than all previous VLN instruction generation methods. Finally, we demonstrate the scalability of our method through increasing environment and instruction diversity, and the generalization ability of our pre-trained navigator across various downstream navigation tasks, surpassing state-of-the-art methods by a large margin in all cases.