 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSTORM: Internalized Modeling for Spatial-Temporal Reasoning in Video-Language Models
May 25, 2026Many video reasoning tasks require tracking motion, temporal order, and evolving visual states across frames. Existing methods built on large vision-language models (LVLMs) often address this challenge by externalizing reasoning through textual chain-of-thought (CoT), keyframe selection, repeated frame reinsertion, or external tool use. While effective, such pipelines increase inference-time latency and engineering complexity, and they force temporal-visual evidence to be serialized into text or repeatedly re-encoded from frames. Inspired by the intuition that visual reasoning can occur implicitly before verbalization, we propose STORMS (Spatial-Temporal reasOning via inteRnalized Modeling), a two-stage framework that teaches LVLMs to reason through bounded continuous latent trajectories instead of explicit textual CoT. In Stage I, STORMS aligns latent tokens with thought-video representations derived from generated videos, grounding the latent states in dynamic visual evidence. In Stage II, the model is further trained with answer-only supervision, encouraging the reasoning process to be internalized without step-by-step annotations. Generated thought videos are used only during training; at inference, STORMS performs a bounded latent rollout without regenerating videos, reinserting frames, or invoking external visual tools. Experiments on VideoMME, MVBench, TempCompass, and MMVU show that STORMS improves video reasoning accuracy while substantially reducing inference overhead compared with tool or video-generation-based reasoning pipelines.
VEBench:Benchmarking Large Multimodal Models for Real-World Video Editing
May 05, 2026Real-world video editing demands not only expert knowledge of cinematic techniques but also multimodal reasoning to select, align, and combine footage into coherent narratives. While recent Large Multimodal Models (LMMs) have shown remarkable progress in general video understanding, their abilities in multi-video reasoning and operational editing workflows remain largely unexplored. We introduce VEBENCH, the first comprehensive benchmark designed to evaluate both editing knowledge understanding and operational reasoning in realistic video editing scenarios. VEBENCH contains 3.9K high-quality edited videos (over 257 hours) and 3,080 human-verified QA pairs, built through a three-round human-AI collaborative annotation pipeline that ensures precise temporal labeling and semantic consistency. It features two complementary QA tasks: 1) Video Editing Technique Recognition, assessing models' ability to identify 7 editing techniques using multimodal cues; and 2) Video Editing Operation Simulation, modeling real-world editing workflows by requiring the selection and temporal localization of relevant clips from multiple candidates. Extensive experiments across proprietary (e.g., Gemini-2.5-Pro) and open-source LMMs reveal a large gap between current model performance and human-level editing cognition. These results highlight the urgent need for bridging video understanding with creative operational reasoning. We envision VEBENCH as a foundation for advancing intelligent video editing systems and driving future research on complex reasoning.
A.I.R.: Enabling Adaptive, Iterative, and Reasoning-based Frame Selection For Video Question Answering
Oct 06, 2025Effectively applying Vision-Language Models (VLMs) to Video Question Answering (VideoQA) hinges on selecting a concise yet comprehensive set of frames, as processing entire videos is computationally infeasible. However, current frame selection methods face a critical trade-off: approaches relying on lightweight similarity models, such as CLIP, often fail to capture the nuances of complex queries, resulting in inaccurate similarity scores that cannot reflect the authentic query-frame relevance, which further undermines frame selection. Meanwhile, methods that leverage a VLM for deeper analysis achieve higher accuracy but incur prohibitive computational costs. To address these limitations, we propose A.I.R., a training-free approach for Adaptive, Iterative, and Reasoning-based frame selection. We leverage a powerful VLM to perform deep, semantic analysis on complex queries, and this analysis is deployed within a cost-effective iterative loop that processes only a small batch of the most high-potential frames at a time. Extensive experiments on various VideoQA benchmarks demonstrate that our approach outperforms existing frame selection methods, significantly boosts the performance of the foundation VLM, and achieves substantial gains in computational efficiency over other VLM-based techniques.
Seq2Time: Sequential Knowledge Transfer for Video LLM Temporal Grounding
Nov 25, 2024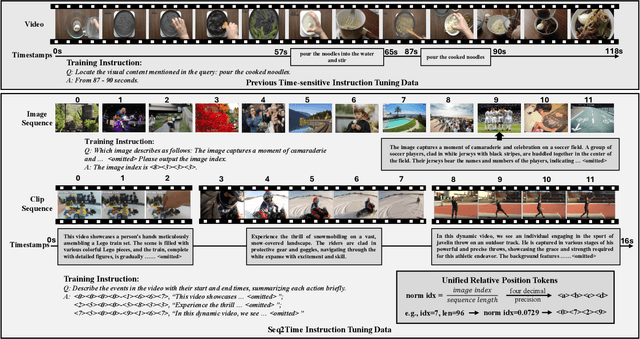



Temporal awareness is essential for video large language models (LLMs) to understand and reason about events within long videos, enabling applications like dense video captioning and temporal video grounding in a unified system. However, the scarcity of long videos with detailed captions and precise temporal annotations limits their temporal awareness. In this paper, we propose Seq2Time, a data-oriented training paradigm that leverages sequences of images and short video clips to enhance temporal awareness in long videos. By converting sequence positions into temporal annotations, we transform large-scale image and clip captioning datasets into sequences that mimic the temporal structure of long videos, enabling self-supervised training with abundant time-sensitive data. To enable sequence-to-time knowledge transfer, we introduce a novel time representation that unifies positional information across image sequences, clip sequences, and long videos. Experiments demonstrate the effectiveness of our method, achieving a 27.6% improvement in F1 score and 44.8% in CIDEr on the YouCook2 benchmark and a 14.7% increase in recall on the Charades-STA benchmark compared to the baseline.
Motion-Grounded Video Reasoning: Understanding and Perceiving Motion at Pixel Level
Nov 15, 2024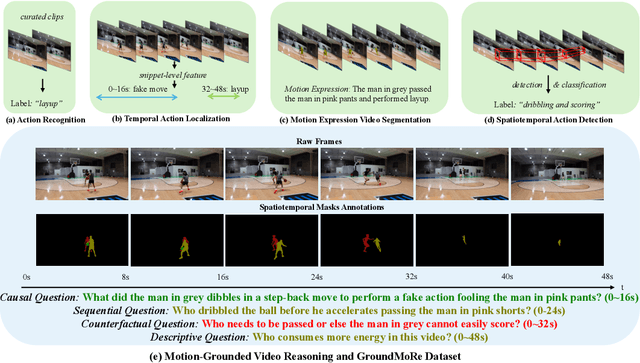

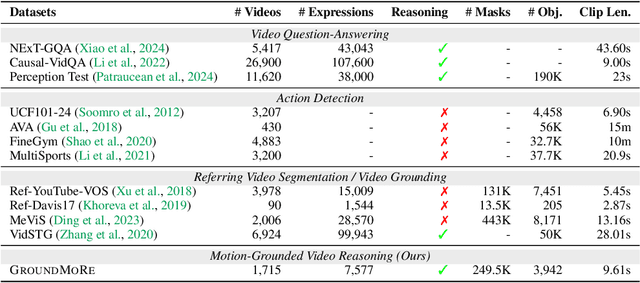

In this paper, we introduce Motion-Grounded Video Reasoning, a new motion understanding task that requires generating visual answers (video segmentation masks) according to the input question, and hence needs implicit spatiotemporal reasoning and grounding. This task extends existing spatiotemporal grounding work focusing on explicit action/motion grounding, to a more general format by enabling implicit reasoning via questions. To facilitate the development of the new task, we collect a large-scale dataset called GROUNDMORE, which comprises 1,715 video clips, 249K object masks that are deliberately designed with 4 question types (Causal, Sequential, Counterfactual, and Descriptive) for benchmarking deep and comprehensive motion reasoning abilities. GROUNDMORE uniquely requires models to generate visual answers, providing a more concrete and visually interpretable response than plain texts. It evaluates models on both spatiotemporal grounding and reasoning, fostering to address complex challenges in motion-related video reasoning, temporal perception, and pixel-level understanding. Furthermore, we introduce a novel baseline model named Motion-Grounded Video Reasoning Assistant (MORA). MORA incorporates the multimodal reasoning ability from the Multimodal LLM, the pixel-level perception capability from the grounding model (SAM), and the temporal perception ability from a lightweight localization head. MORA achieves respectable performance on GROUNDMORE outperforming the best existing visual grounding baseline model by an average of 21.5% relatively. We hope this novel and challenging task will pave the way for future advancements in robust and general motion understanding via video reasoning segmentation
Order-aware Interactive Segmentation
Oct 17, 2024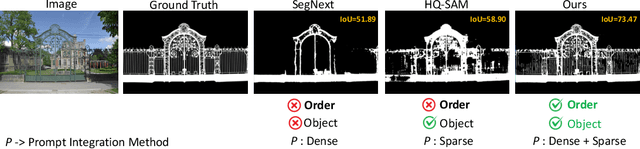
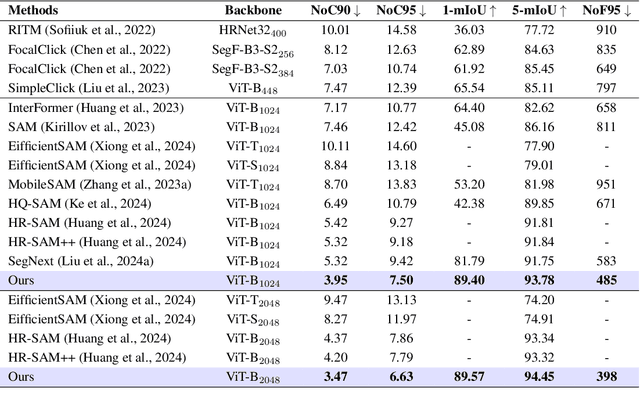
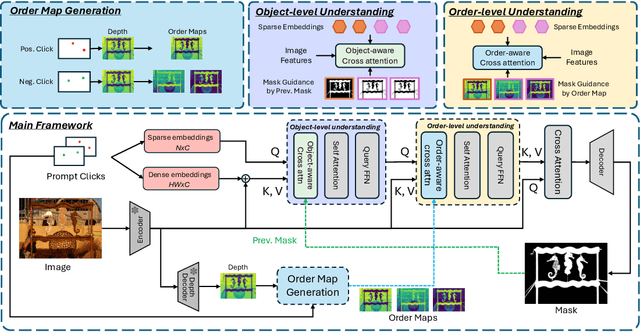
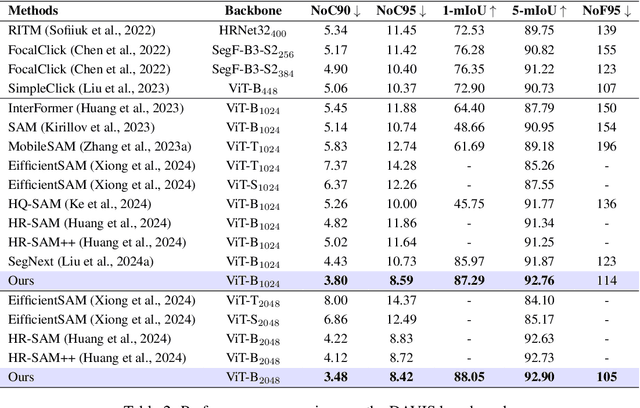
Interactive segmentation aims to accurately segment target objects with minimal user interactions. However, current methods often fail to accurately separate target objects from the background, due to a limited understanding of order, the relative depth between objects in a scene. To address this issue, we propose OIS: order-aware interactive segmentation, where we explicitly encode the relative depth between objects into order maps. We introduce a novel order-aware attention, where the order maps seamlessly guide the user interactions (in the form of clicks) to attend to the image features. We further present an object-aware attention module to incorporate a strong object-level understanding to better differentiate objects with similar order. Our approach allows both dense and sparse integration of user clicks, enhancing both accuracy and efficiency as compared to prior works. Experimental results demonstrate that OIS achieves state-of-the-art performance, improving mIoU after one click by 7.61 on the HQSeg44K dataset and 1.32 on the DAVIS dataset as compared to the previous state-of-the-art SegNext, while also doubling inference speed compared to current leading methods. The project page is https://ukaukaaaa.github.io/projects/OIS/index.html
Sports-QA: A Large-Scale Video Question Answering Benchmark for Complex and Professional Sports
Jan 07, 2024Reasoning over sports videos for question answering is an important task with numerous applications, such as player training and information retrieval. However, this task has not been explored due to the lack of relevant datasets and the challenging nature it presents. Most datasets for video question answering (VideoQA) focus mainly on general and coarse-grained understanding of daily-life videos, which is not applicable to sports scenarios requiring professional action understanding and fine-grained motion analysis. In this paper, we introduce the first dataset, named Sports-QA, specifically designed for the sports VideoQA task. The Sports-QA dataset includes various types of questions, such as descriptions, chronologies, causalities, and counterfactual conditions, covering multiple sports. Furthermore, to address the characteristics of the sports VideoQA task, we propose a new Auto-Focus Transformer (AFT) capable of automatically focusing on particular scales of temporal information for question answering. We conduct extensive experiments on Sports-QA, including baseline studies and the evaluation of different methods. The results demonstrate that our AFT achieves state-of-the-art performance.
Robust Cross-Modal Knowledge Distillation for Unconstrained Videos
Apr 27, 2023Cross-modal distillation has been widely used to transfer knowledge across different modalities, enriching the representation of the target unimodal one. Recent studies highly relate the temporal synchronization between vision and sound to the semantic consistency for cross-modal distillation. However, such semantic consistency from the synchronization is hard to guarantee in unconstrained videos, due to the irrelevant modality noise and differentiated semantic correlation. To this end, we first propose a \textit{Modality Noise Filter} (MNF) module to erase the irrelevant noise in teacher modality with cross-modal context. After this purification, we then design a \textit{Contrastive Semantic Calibration} (CSC) module to adaptively distill useful knowledge for target modality, by referring to the differentiated sample-wise semantic correlation in a contrastive fashion. Extensive experiments show that our method could bring a performance boost compared with other distillation methods in both visual action recognition and video retrieval task. We also extend to the audio tagging task to prove the generalization of our method. The source code is available at \href{https://github.com/GeWu-Lab/cross-modal-distillation}{https://github.com/GeWu-Lab/cross-modal-distillation}.
A Large-scale Study of Spatiotemporal Representation Learning with a New Benchmark on Action Recognition
Mar 23, 2023
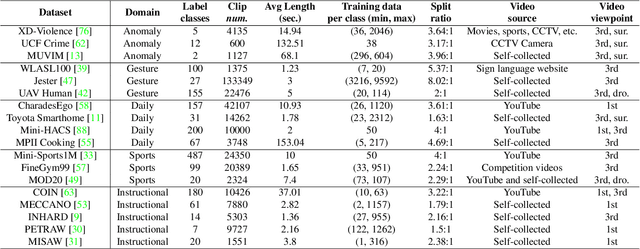
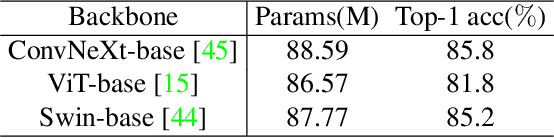
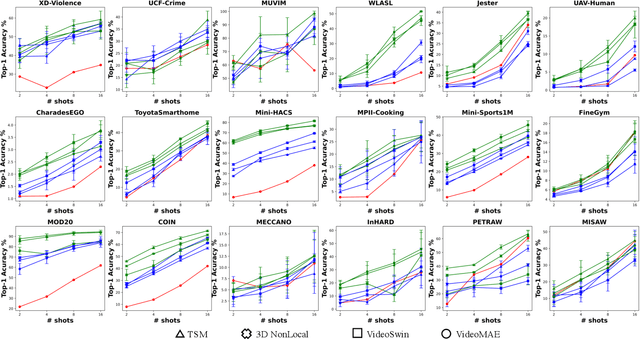
The goal of building a benchmark (suite of datasets) is to provide a unified protocol for fair evaluation and thus facilitate the evolution of a specific area. Nonetheless, we point out that existing protocols of action recognition could yield partial evaluations due to several limitations. To comprehensively probe the effectiveness of spatiotemporal representation learning, we introduce BEAR, a new BEnchmark on video Action Recognition. BEAR is a collection of 18 video datasets grouped into 5 categories (anomaly, gesture, daily, sports, and instructional), which covers a diverse set of real-world applications. With BEAR, we thoroughly evaluate 6 common spatiotemporal models pre-trained by both supervised and self-supervised learning. We also report transfer performance via standard finetuning, few-shot finetuning, and unsupervised domain adaptation. Our observation suggests that current state-of-the-art cannot solidly guarantee high performance on datasets close to real-world applications, and we hope BEAR can serve as a fair and challenging evaluation benchmark to gain insights on building next-generation spatiotemporal learners. Our dataset, code, and models are released at: https://github.com/AndongDeng/BEAR
Problem Behaviors Recognition in Videos using Language-Assisted Deep Learning Model for Children with Autism
Nov 17, 2022


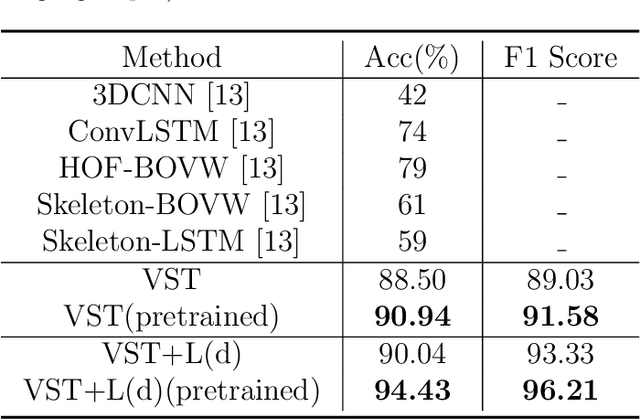
Correctly recognizing the behaviors of children with Autism Spectrum Disorder (ASD) is of vital importance for the diagnosis of Autism and timely early intervention. However, the observation and recording during the treatment from the parents of autistic children may not be accurate and objective. In such cases, automatic recognition systems based on computer vision and machine learning (in particular deep learning) technology can alleviate this issue to a large extent. Existing human action recognition models can now achieve persuasive performance on challenging activity datasets, e.g. daily activity, and sports activity. However, problem behaviors in children with ASD are very different from these general activities, and recognizing these problem behaviors via computer vision is less studied. In this paper, we first evaluate a strong baseline for action recognition, i.e. Video Swin Transformer, on two autism behaviors datasets (SSBD and ESBD) and show that it can achieve high accuracy and outperform the previous methods by a large margin, demonstrating the feasibility of vision-based problem behaviors recognition. Moreover, we propose language-assisted training to further enhance the action recognition performance. Specifically, we develop a two-branch multimodal deep learning framework by incorporating the "freely available" language description for each type of problem behavior. Experimental results demonstrate that incorporating additional language supervision can bring an obvious performance boost for the autism problem behaviors recognition task as compared to using the video information only (i.e. 3.49% improvement on ESBD and 1.46% on SSBD).