 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCommunity Detection Using Revised Medoid-Shift Based on KNN
Apr 19, 2023Community detection becomes an important problem with the booming of social networks. As an excellent clustering algorithm, Mean-Shift can not be applied directly to community detection, since Mean-Shift can only handle data with coordinates, while the data in the community detection problem is mostly represented by a graph that can be treated as data with a distance matrix (or similarity matrix). Fortunately, a new clustering algorithm called Medoid-Shift is proposed. The Medoid-Shift algorithm preserves the benefits of Mean-Shift and can be applied to problems based on distance matrix, such as community detection. One drawback of the Medoid-Shift algorithm is that there may be no data points within the neighborhood region defined by a distance parameter. To deal with the community detection problem better, a new algorithm called Revised Medoid-Shift (RMS) in this work is thus proposed. During the process of finding the next medoid, the RMS algorithm is based on a neighborhood defined by KNN, while the original Medoid-Shift is based on a neighborhood defined by a distance parameter. Since the neighborhood defined by KNN is more stable than the one defined by the distance parameter in terms of the number of data points within the neighborhood, the RMS algorithm may converge more smoothly. In the RMS method, each of the data points is shifted towards a medoid within the neighborhood defined by KNN. After the iterative process of shifting, each of the data point converges into a cluster center, and the data points converging into the same center are grouped into the same cluster.
Balanced Multimodal Learning via On-the-fly Gradient Modulation
Mar 29, 2022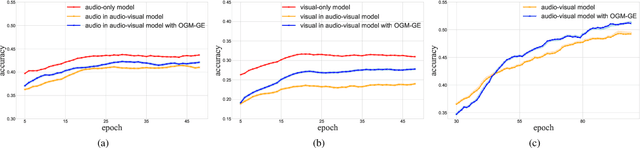
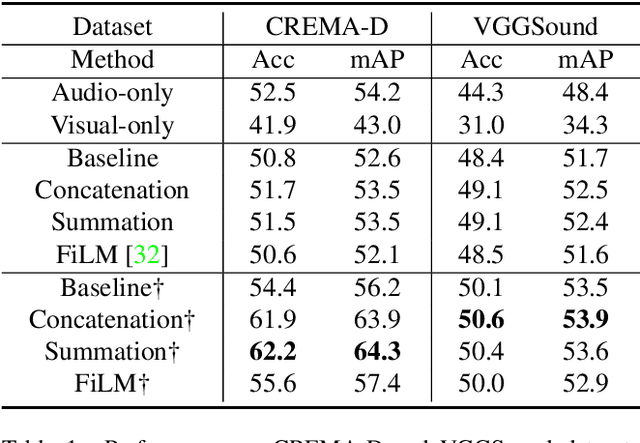
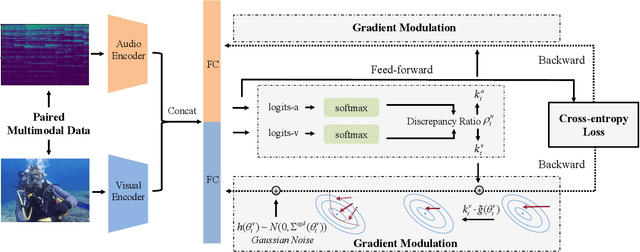
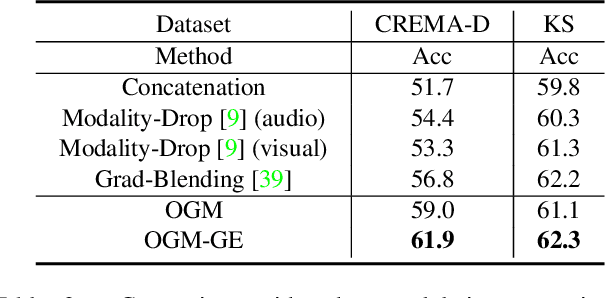
Multimodal learning helps to comprehensively understand the world, by integrating different senses. Accordingly, multiple input modalities are expected to boost model performance, but we actually find that they are not fully exploited even when the multimodal model outperforms its uni-modal counterpart. Specifically, in this paper we point out that existing multimodal discriminative models, in which uniform objective is designed for all modalities, could remain under-optimized uni-modal representations, caused by another dominated modality in some scenarios, e.g., sound in blowing wind event, vision in drawing picture event, etc. To alleviate this optimization imbalance, we propose on-the-fly gradient modulation to adaptively control the optimization of each modality, via monitoring the discrepancy of their contribution towards the learning objective. Further, an extra Gaussian noise that changes dynamically is introduced to avoid possible generalization drop caused by gradient modulation. As a result, we achieve considerable improvement over common fusion methods on different multimodal tasks, and this simple strategy can also boost existing multimodal methods, which illustrates its efficacy and versatility. The source code is available at \url{https://github.com/GeWu-Lab/OGM-GE_CVPR2022}.