 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSeq2Time: Sequential Knowledge Transfer for Video LLM Temporal Grounding
Paper and Code
Nov 25, 2024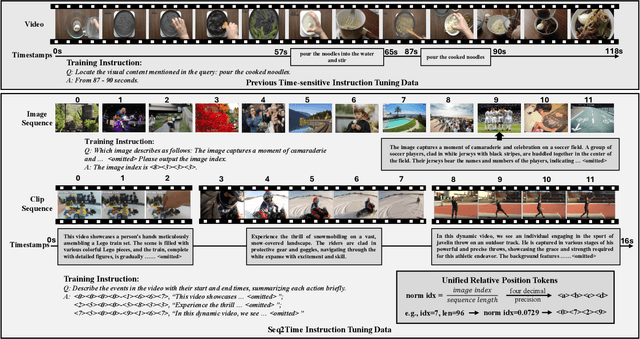



Temporal awareness is essential for video large language models (LLMs) to understand and reason about events within long videos, enabling applications like dense video captioning and temporal video grounding in a unified system. However, the scarcity of long videos with detailed captions and precise temporal annotations limits their temporal awareness. In this paper, we propose Seq2Time, a data-oriented training paradigm that leverages sequences of images and short video clips to enhance temporal awareness in long videos. By converting sequence positions into temporal annotations, we transform large-scale image and clip captioning datasets into sequences that mimic the temporal structure of long videos, enabling self-supervised training with abundant time-sensitive data. To enable sequence-to-time knowledge transfer, we introduce a novel time representation that unifies positional information across image sequences, clip sequences, and long videos. Experiments demonstrate the effectiveness of our method, achieving a 27.6% improvement in F1 score and 44.8% in CIDEr on the YouCook2 benchmark and a 14.7% increase in recall on the Charades-STA benchmark compared to the baseline.