 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Large-scale Study of Spatiotemporal Representation Learning with a New Benchmark on Action Recognition
Paper and Code

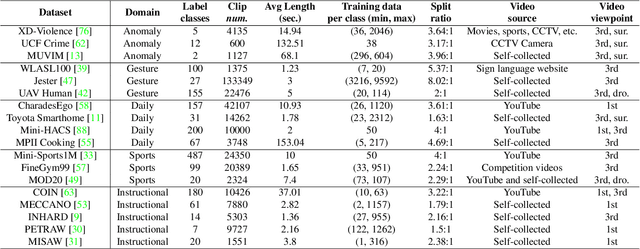
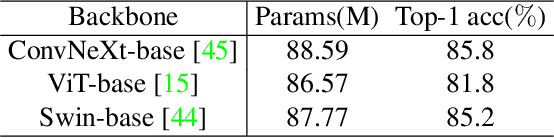
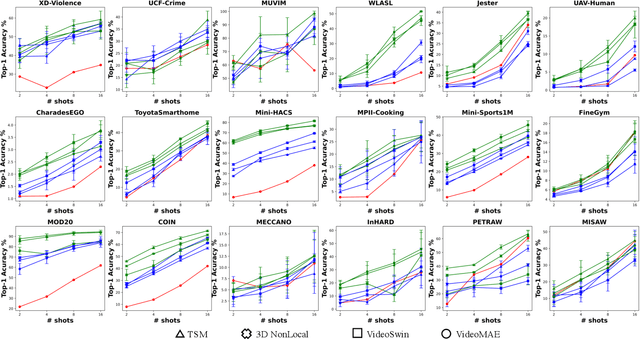
The goal of building a benchmark (suite of datasets) is to provide a unified protocol for fair evaluation and thus facilitate the evolution of a specific area. Nonetheless, we point out that existing protocols of action recognition could yield partial evaluations due to several limitations. To comprehensively probe the effectiveness of spatiotemporal representation learning, we introduce BEAR, a new BEnchmark on video Action Recognition. BEAR is a collection of 18 video datasets grouped into 5 categories (anomaly, gesture, daily, sports, and instructional), which covers a diverse set of real-world applications. With BEAR, we thoroughly evaluate 6 common spatiotemporal models pre-trained by both supervised and self-supervised learning. We also report transfer performance via standard finetuning, few-shot finetuning, and unsupervised domain adaptation. Our observation suggests that current state-of-the-art cannot solidly guarantee high performance on datasets close to real-world applications, and we hope BEAR can serve as a fair and challenging evaluation benchmark to gain insights on building next-generation spatiotemporal learners. Our dataset, code, and models are released at: https://github.com/AndongDeng/BEAR