 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeClass-Partitioned VQ-VAE and Latent Flow Matching for Point Cloud Scene Generation
Jan 18, 2026Most 3D scene generation methods are limited to only generating object bounding box parameters while newer diffusion methods also generate class labels and latent features. Using object size or latent feature, they then retrieve objects from a predefined database. For complex scenes of varied, multi-categorical objects, diffusion-based latents cannot be effectively decoded by current autoencoders into the correct point cloud objects which agree with target classes. We introduce a Class-Partitioned Vector Quantized Variational Autoencoder (CPVQ-VAE) that is trained to effectively decode object latent features, by employing a pioneering $\textit{class-partitioned codebook}$ where codevectors are labeled by class. To address the problem of $\textit{codebook collapse}$, we propose a $\textit{class-aware}$ running average update which reinitializes dead codevectors within each partition. During inference, object features and class labels, both generated by a Latent-space Flow Matching Model (LFMM) designed specifically for scene generation, are consumed by the CPVQ-VAE. The CPVQ-VAE's class-aware inverse look-up then maps generated latents to codebook entries that are decoded to class-specific point cloud shapes. Thereby, we achieve pure point cloud generation without relying on an external objects database for retrieval. Extensive experiments reveal that our method reliably recovers plausible point cloud scenes, with up to 70.4% and 72.3% reduction in Chamfer and Point2Mesh errors on complex living room scenes.
Hybrid Long and Short Range Flows for Point Cloud Filtering
Aug 12, 2025Point cloud capture processes are error-prone and introduce noisy artifacts that necessitate filtering/denoising. Recent filtering methods often suffer from point clustering or noise retaining issues. In this paper, we propose Hybrid Point Cloud Filtering ($\textbf{HybridPF}$) that considers both short-range and long-range filtering trajectories when removing noise. It is well established that short range scores, given by $\nabla_{x}\log p(x_t)$, may provide the necessary displacements to move noisy points to the underlying clean surface. By contrast, long range velocity flows approximate constant displacements directed from a high noise variant patch $x_0$ towards the corresponding clean surface $x_1$. Here, noisy patches $x_t$ are viewed as intermediate states between the high noise variant and the clean patches. Our intuition is that long range information from velocity flow models can guide the short range scores to align more closely with the clean points. In turn, score models generally provide a quicker convergence to the clean surface. Specifically, we devise two parallel modules, the ShortModule and LongModule, each consisting of an Encoder-Decoder pair to respectively account for short-range scores and long-range flows. We find that short-range scores, guided by long-range features, yield filtered point clouds with good point distributions and convergence near the clean surface. We design a joint loss function to simultaneously train the ShortModule and LongModule, in an end-to-end manner. Finally, we identify a key weakness in current displacement based methods, limitations on the decoder architecture, and propose a dynamic graph convolutional decoder to improve the inference process. Comprehensive experiments demonstrate that our HybridPF achieves state-of-the-art results while enabling faster inference speed.
Auto-Regressive Diffusion for Generating 3D Human-Object Interactions
Mar 21, 2025Text-driven Human-Object Interaction (Text-to-HOI) generation is an emerging field with applications in animation, video games, virtual reality, and robotics. A key challenge in HOI generation is maintaining interaction consistency in long sequences. Existing Text-to-Motion-based approaches, such as discrete motion tokenization, cannot be directly applied to HOI generation due to limited data in this domain and the complexity of the modality. To address the problem of interaction consistency in long sequences, we propose an autoregressive diffusion model (ARDHOI) that predicts the next continuous token. Specifically, we introduce a Contrastive Variational Autoencoder (cVAE) to learn a physically plausible space of continuous HOI tokens, thereby ensuring that generated human-object motions are realistic and natural. For generating sequences autoregressively, we develop a Mamba-based context encoder to capture and maintain consistent sequential actions. Additionally, we implement an MLP-based denoiser to generate the subsequent token conditioned on the encoded context. Our model has been evaluated on the OMOMO and BEHAVE datasets, where it outperforms existing state-of-the-art methods in terms of both performance and inference speed. This makes ARDHOI a robust and efficient solution for text-driven HOI tasks
PointDiffuse: A Dual-Conditional Diffusion Model for Enhanced Point Cloud Semantic Segmentation
Mar 11, 2025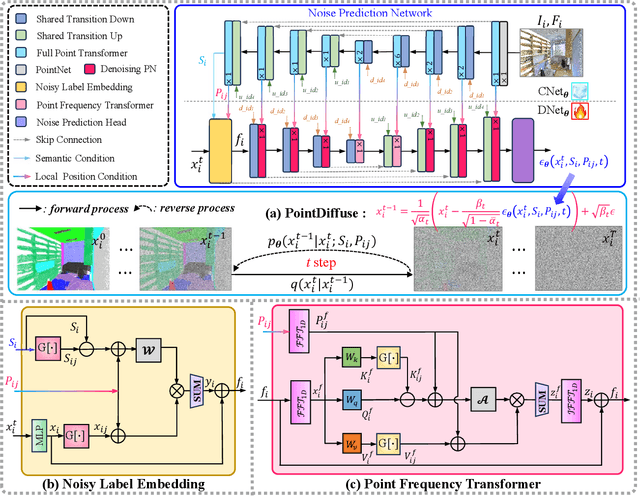



Diffusion probabilistic models are traditionally used to generate colors at fixed pixel positions in 2D images. Building on this, we extend diffusion models to point cloud semantic segmentation, where point positions also remain fixed, and the diffusion model generates point labels instead of colors. To accelerate the denoising process in reverse diffusion, we introduce a noisy label embedding mechanism. This approach integrates semantic information into the noisy label, providing an initial semantic reference that improves the reverse diffusion efficiency. Additionally, we propose a point frequency transformer that enhances the adjustment of high-level context in point clouds. To reduce computational complexity, we introduce the position condition into MLP and propose denoising PointNet to process the high-resolution point cloud without sacrificing geometric details. Finally, we integrate the proposed noisy label embedding, point frequency transformer and denoising PointNet in our proposed dual conditional diffusion model-based network (PointDiffuse) to perform large-scale point cloud semantic segmentation. Extensive experiments on five benchmarks demonstrate the superiority of PointDiffuse, achieving the state-of-the-art mIoU of 74.2\% on S3DIS Area 5, 81.2\% on S3DIS 6-fold and 64.8\% on SWAN dataset.
Skip Mamba Diffusion for Monocular 3D Semantic Scene Completion
Jan 13, 20253D semantic scene completion is critical for multiple downstream tasks in autonomous systems. It estimates missing geometric and semantic information in the acquired scene data. Due to the challenging real-world conditions, this task usually demands complex models that process multi-modal data to achieve acceptable performance. We propose a unique neural model, leveraging advances from the state space and diffusion generative modeling to achieve remarkable 3D semantic scene completion performance with monocular image input. Our technique processes the data in the conditioned latent space of a variational autoencoder where diffusion modeling is carried out with an innovative state space technique. A key component of our neural network is the proposed Skimba (Skip Mamba) denoiser, which is adept at efficiently processing long-sequence data. The Skimba diffusion model is integral to our 3D scene completion network, incorporating a triple Mamba structure, dimensional decomposition residuals and varying dilations along three directions. We also adopt a variant of this network for the subsequent semantic segmentation stage of our method. Extensive evaluation on the standard SemanticKITTI and SSCBench-KITTI360 datasets show that our approach not only outperforms other monocular techniques by a large margin, it also achieves competitive performance against stereo methods. The code is available at https://github.com/xrkong/skimba
Motion-Grounded Video Reasoning: Understanding and Perceiving Motion at Pixel Level
Nov 15, 2024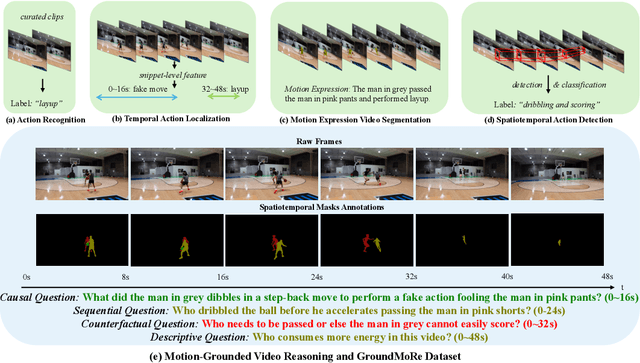

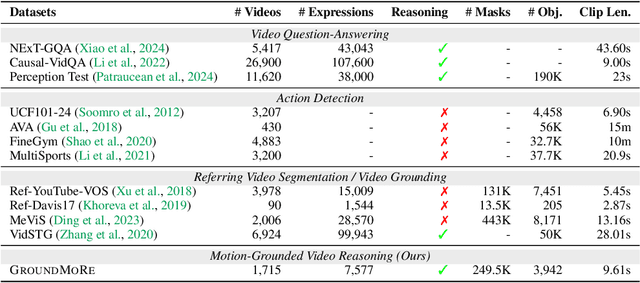

In this paper, we introduce Motion-Grounded Video Reasoning, a new motion understanding task that requires generating visual answers (video segmentation masks) according to the input question, and hence needs implicit spatiotemporal reasoning and grounding. This task extends existing spatiotemporal grounding work focusing on explicit action/motion grounding, to a more general format by enabling implicit reasoning via questions. To facilitate the development of the new task, we collect a large-scale dataset called GROUNDMORE, which comprises 1,715 video clips, 249K object masks that are deliberately designed with 4 question types (Causal, Sequential, Counterfactual, and Descriptive) for benchmarking deep and comprehensive motion reasoning abilities. GROUNDMORE uniquely requires models to generate visual answers, providing a more concrete and visually interpretable response than plain texts. It evaluates models on both spatiotemporal grounding and reasoning, fostering to address complex challenges in motion-related video reasoning, temporal perception, and pixel-level understanding. Furthermore, we introduce a novel baseline model named Motion-Grounded Video Reasoning Assistant (MORA). MORA incorporates the multimodal reasoning ability from the Multimodal LLM, the pixel-level perception capability from the grounding model (SAM), and the temporal perception ability from a lightweight localization head. MORA achieves respectable performance on GROUNDMORE outperforming the best existing visual grounding baseline model by an average of 21.5% relatively. We hope this novel and challenging task will pave the way for future advancements in robust and general motion understanding via video reasoning segmentation
Avatar Concept Slider: Manipulate Concepts In Your Human Avatar With Fine-grained Control
Aug 26, 2024Language based editing of 3D human avatars to precisely match user requirements is challenging due to the inherent ambiguity and limited expressiveness of natural language. To overcome this, we propose the Avatar Concept Slider (ACS), a 3D avatar editing method that allows precise manipulation of semantic concepts in human avatars towards a specified intermediate point between two extremes of concepts, akin to moving a knob along a slider track. To achieve this, our ACS has three designs. 1) A Concept Sliding Loss based on Linear Discriminant Analysis to pinpoint the concept-specific axis for precise editing. 2) An Attribute Preserving Loss based on Principal Component Analysis for improved preservation of avatar identity during editing. 3) A 3D Gaussian Splatting primitive selection mechanism based on concept-sensitivity, which updates only the primitives that are the most sensitive to our target concept, to improve efficiency. Results demonstrate that our ACS enables fine-grained 3D avatar editing with efficient feedback, without harming the avatar quality or compromising the avatar's identifying attributes.
Diffusion-Driven Self-Supervised Learning for Shape Reconstruction and Pose Estimation
Mar 19, 2024



Fully-supervised category-level pose estimation aims to determine the 6-DoF poses of unseen instances from known categories, requiring expensive mannual labeling costs. Recently, various self-supervised category-level pose estimation methods have been proposed to reduce the requirement of the annotated datasets. However, most methods rely on synthetic data or 3D CAD model for self-supervised training, and they are typically limited to addressing single-object pose problems without considering multi-objective tasks or shape reconstruction. To overcome these challenges and limitations, we introduce a diffusion-driven self-supervised network for multi-object shape reconstruction and categorical pose estimation, only leveraging the shape priors. Specifically, to capture the SE(3)-equivariant pose features and 3D scale-invariant shape information, we present a Prior-Aware Pyramid 3D Point Transformer in our network. This module adopts a point convolutional layer with radial-kernels for pose-aware learning and a 3D scale-invariant graph convolution layer for object-level shape representation, respectively. Furthermore, we introduce a pretrain-to-refine self-supervised training paradigm to train our network. It enables proposed network to capture the associations between shape priors and observations, addressing the challenge of intra-class shape variations by utilising the diffusion mechanism. Extensive experiments conducted on four public datasets and a self-built dataset demonstrate that our method significantly outperforms state-of-the-art self-supervised category-level baselines and even surpasses some fully-supervised instance-level and category-level methods.
Simultaneous Multiple Object Detection and Pose Estimation using 3D Model Infusion with Monocular Vision
Nov 22, 2022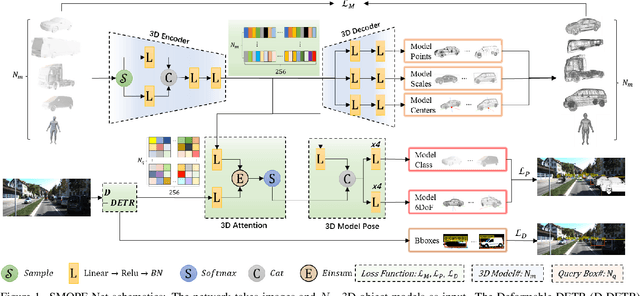

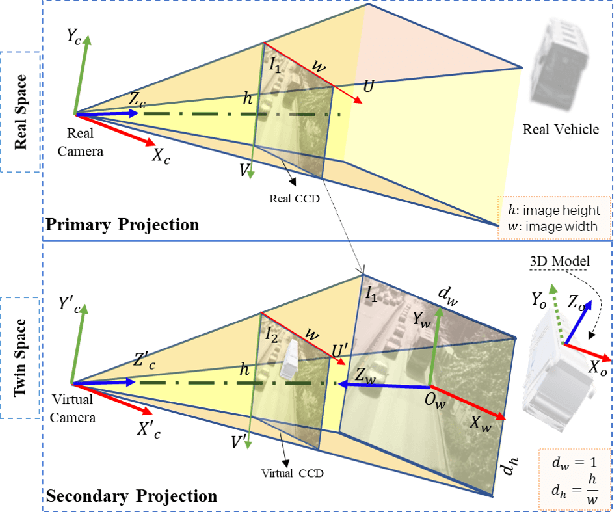
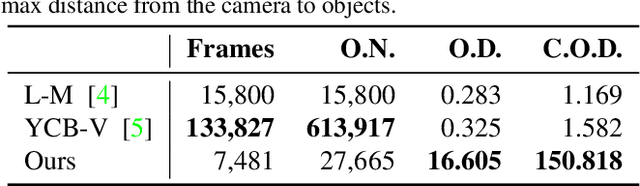
Multiple object detection and pose estimation are vital computer vision tasks. The latter relates to the former as a downstream problem in applications such as robotics and autonomous driving. However, due to the high complexity of both tasks, existing methods generally treat them independently, which is sub-optimal. We propose simultaneous neural modeling of both using monocular vision and 3D model infusion. Our Simultaneous Multiple Object detection and Pose Estimation network (SMOPE-Net) is an end-to-end trainable multitasking network with a composite loss that also provides the advantages of anchor-free detections for efficient downstream pose estimation. To enable the annotation of training data for our learning objective, we develop a Twin-Space object labeling method and demonstrate its correctness analytically and empirically. Using the labeling method, we provide the KITTI-6DoF dataset with $\sim7.5$K annotated frames. Extensive experiments on KITTI-6DoF and the popular LineMod datasets show a consistent performance gain with SMOPE-Net over existing pose estimation methods. Here are links to our proposed SMOPE-Net, KITTI-6DoF dataset, and LabelImg3D labeling tool.
Diversifying Topic-Coherent Response Generation for Natural Multi-turn Conversations
Oct 24, 2019



Although response generation (RG) diversification for single-turn dialogs has been well developed, it is less investigated for natural multi-turn conversations. Besides, past work focused on diversifying responses without considering topic coherence to the context, producing uninformative replies. In this paper, we propose the Topic-coherent Hierarchical Recurrent Encoder-Decoder model (THRED) to diversify the generated responses without deviating the contextual topics for multi-turn conversations. In overall, we build a sequence-to-sequence net (Seq2Seq) to model multi-turn conversations. And then we resort to the latent Variable Hierarchical Recurrent Encoder-Decoder model (VHRED) to learn global contextual distribution of dialogs. Besides, we construct a dense topic matrix which implies word-level correlations of the conversation corpora. The topic matrix is used to learn local topic distribution of the contextual utterances. By incorporating both the global contextual distribution and the local topic distribution, THRED produces both diversified and topic-coherent replies. In addition, we propose an explicit metric (\emph{TopicDiv}) to measure the topic divergence between the post and generated response, and we also propose an overall metric combining the diversification metric (\emph{Distinct}) and \emph{TopicDiv}. We evaluate our model comparing with three baselines (Seq2Seq, HRED and VHRED) on two real-world corpora, respectively, and demonstrate its outstanding performance in both diversification and topic coherence.