 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSimultaneous Multiple Object Detection and Pose Estimation using 3D Model Infusion with Monocular Vision
Paper and Code
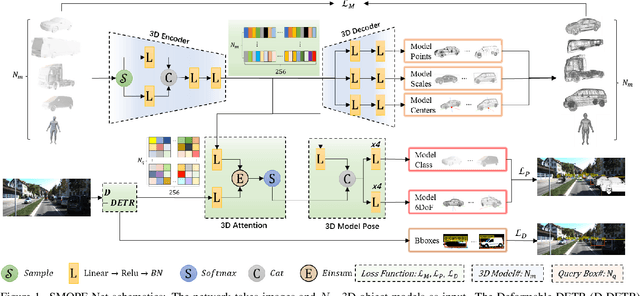

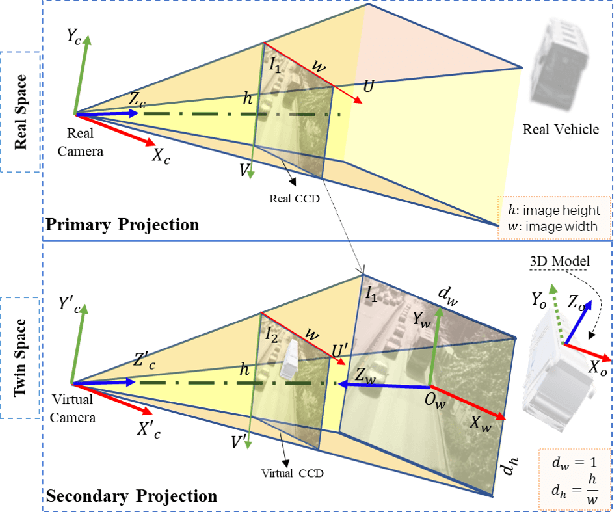
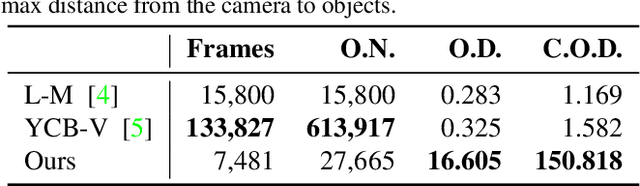
Multiple object detection and pose estimation are vital computer vision tasks. The latter relates to the former as a downstream problem in applications such as robotics and autonomous driving. However, due to the high complexity of both tasks, existing methods generally treat them independently, which is sub-optimal. We propose simultaneous neural modeling of both using monocular vision and 3D model infusion. Our Simultaneous Multiple Object detection and Pose Estimation network (SMOPE-Net) is an end-to-end trainable multitasking network with a composite loss that also provides the advantages of anchor-free detections for efficient downstream pose estimation. To enable the annotation of training data for our learning objective, we develop a Twin-Space object labeling method and demonstrate its correctness analytically and empirically. Using the labeling method, we provide the KITTI-6DoF dataset with $\sim7.5$K annotated frames. Extensive experiments on KITTI-6DoF and the popular LineMod datasets show a consistent performance gain with SMOPE-Net over existing pose estimation methods. Here are links to our proposed SMOPE-Net, KITTI-6DoF dataset, and LabelImg3D labeling tool.