 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Point Cloud Processing with High-Dimensional Positional Encoding and Non-Local MLPs
Mar 04, 2026Multi-Layer Perceptron (MLP) models are the foundation of contemporary point cloud processing. However, their complex network architectures obscure the source of their strength and limit the application of these models. In this article, we develop a two-stage abstraction and refinement (ABS-REF) view for modular feature extraction in point cloud processing. This view elucidates that whereas the early models focused on ABS stages, the more recent techniques devise sophisticated REF stages to attain performance advantages. Then, we propose a High-dimensional Positional Encoding (HPE) module to explicitly utilize intrinsic positional information, extending the ``positional encoding'' concept from Transformer literature. HPE can be readily deployed in MLP-based architectures and is compatible with transformer-based methods. Within our ABS-REF view, we rethink local aggregation in MLP-based methods and propose replacing time-consuming local MLP operations, which are used to capture local relationships among neighbors. Instead, we use non-local MLPs for efficient non-local information updates, combined with the proposed HPE for effective local information representation. We leverage our modules to develop HPENets, a suite of MLP networks that follow the ABS-REF paradigm, incorporating a scalable HPE-based REF stage. Extensive experiments on seven public datasets across four different tasks show that HPENets deliver a strong balance between efficiency and effectiveness. Notably, HPENet surpasses PointNeXt, a strong MLP-based counterpart, by 1.1% mAcc, 4.0% mIoU, 1.8% mIoU, and 0.2% Cls. mIoU, with only 50.0%, 21.5%, 23.1%, 44.4% of FLOPs on ScanObjectNN, S3DIS, ScanNet, and ShapeNetPart, respectively. Source code is available at https://github.com/zouyanmei/HPENet_v2.git.
GO-N3RDet: Geometry Optimized NeRF-enhanced 3D Object Detector
Mar 19, 2025We propose GO-N3RDet, a scene-geometry optimized multi-view 3D object detector enhanced by neural radiance fields. The key to accurate 3D object detection is in effective voxel representation. However, due to occlusion and lack of 3D information, constructing 3D features from multi-view 2D images is challenging. Addressing that, we introduce a unique 3D positional information embedded voxel optimization mechanism to fuse multi-view features. To prioritize neural field reconstruction in object regions, we also devise a double importance sampling scheme for the NeRF branch of our detector. We additionally propose an opacity optimization module for precise voxel opacity prediction by enforcing multi-view consistency constraints. Moreover, to further improve voxel density consistency across multiple perspectives, we incorporate ray distance as a weighting factor to minimize cumulative ray errors. Our unique modules synergetically form an end-to-end neural model that establishes new state-of-the-art in NeRF-based multi-view 3D detection, verified with extensive experiments on ScanNet and ARKITScenes. Code will be available at https://github.com/ZechuanLi/GO-N3RDet.
PointDiffuse: A Dual-Conditional Diffusion Model for Enhanced Point Cloud Semantic Segmentation
Mar 11, 2025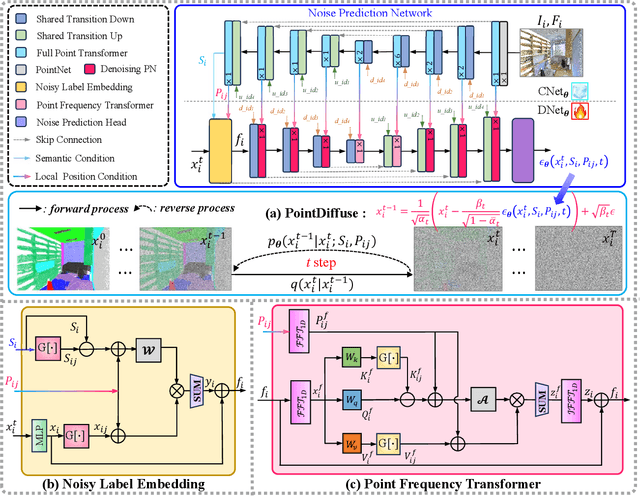



Diffusion probabilistic models are traditionally used to generate colors at fixed pixel positions in 2D images. Building on this, we extend diffusion models to point cloud semantic segmentation, where point positions also remain fixed, and the diffusion model generates point labels instead of colors. To accelerate the denoising process in reverse diffusion, we introduce a noisy label embedding mechanism. This approach integrates semantic information into the noisy label, providing an initial semantic reference that improves the reverse diffusion efficiency. Additionally, we propose a point frequency transformer that enhances the adjustment of high-level context in point clouds. To reduce computational complexity, we introduce the position condition into MLP and propose denoising PointNet to process the high-resolution point cloud without sacrificing geometric details. Finally, we integrate the proposed noisy label embedding, point frequency transformer and denoising PointNet in our proposed dual conditional diffusion model-based network (PointDiffuse) to perform large-scale point cloud semantic segmentation. Extensive experiments on five benchmarks demonstrate the superiority of PointDiffuse, achieving the state-of-the-art mIoU of 74.2\% on S3DIS Area 5, 81.2\% on S3DIS 6-fold and 64.8\% on SWAN dataset.
Deep learning based infrared small object segmentation: Challenges and future directions
Feb 20, 2025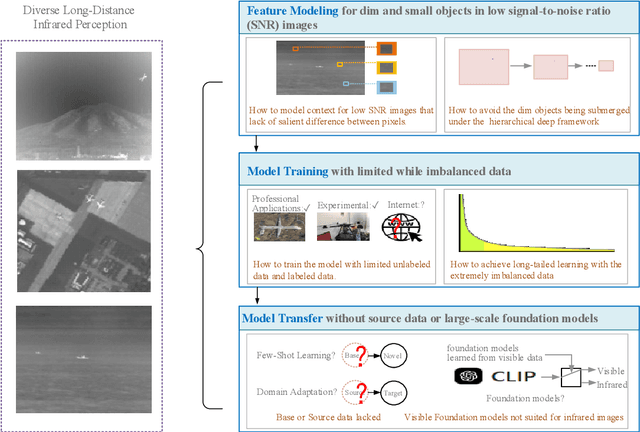

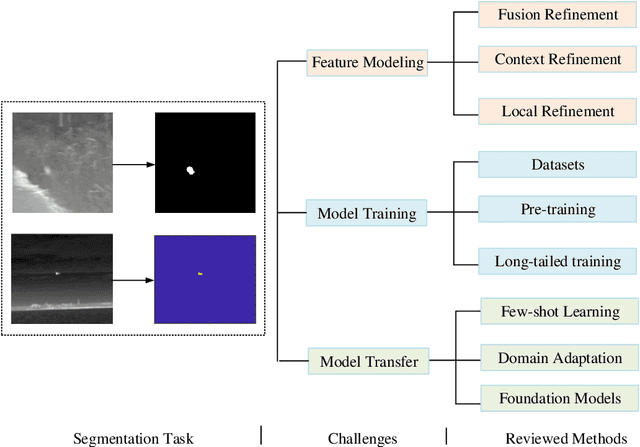

Infrared sensing is a core method for supporting unmanned systems, such as autonomous vehicles and drones. Recently, infrared sensors have been widely deployed on mobile and stationary platforms for detection and classification of objects from long distances and in wide field of views. Given its success in the vision image analysis domain, deep learning has also been applied for object recognition in infrared images. However, techniques that have proven successful in visible light perception face new challenges in the infrared domain. These challenges include extremely low signal-to-noise ratios in infrared images, very small and blurred objects of interest, and limited availability of labeled/unlabeled training data due to the specialized nature of infrared sensors. Numerous methods have been proposed in the literature for the detection and classification of small objects in infrared images achieving varied levels of success. There is a need for a survey paper that critically analyzes existing techniques in this domain, identifies unsolved challenges and provides future research directions. This paper fills the gap and offers a concise and insightful review of deep learning-based methods. It also identifies the challenges faced by existing infrared object segmentation methods and provides a structured review of existing infrared perception methods from the perspective of these challenges and highlights the motivations behind the various approaches. Finally, this review suggests promising future directions based on recent advancements within this domain.
SGLC: Semantic Graph-Guided Coarse-Fine-Refine Full Loop Closing for LiDAR SLAM
Jul 11, 2024



Loop closing is a crucial component in SLAM that helps eliminate accumulated errors through two main steps: loop detection and loop pose correction. The first step determines whether loop closing should be performed, while the second estimates the 6-DoF pose to correct odometry drift. Current methods mostly focus on developing robust descriptors for loop closure detection, often neglecting loop pose estimation. A few methods that do include pose estimation either suffer from low accuracy or incur high computational costs. To tackle this problem, we introduce SGLC, a real-time semantic graph-guided full loop closing method, with robust loop closure detection and 6-DoF pose estimation capabilities. SGLC takes into account the distinct characteristics of foreground and background points. For foreground instances, it builds a semantic graph that not only abstracts point cloud representation for fast descriptor generation and matching but also guides the subsequent loop verification and initial pose estimation. Background points, meanwhile, are exploited to provide more geometric features for scan-wise descriptor construction and stable planar information for further pose refinement. Loop pose estimation employs a coarse-fine-refine registration scheme that considers the alignment of both instance points and background points, offering high efficiency and accuracy. We evaluate the loop closing performance of SGLC through extensive experiments on the KITTI and KITTI-360 datasets, demonstrating its superiority over existing state-of-the-art methods. Additionally, we integrate SGLC into a SLAM system, eliminating accumulated errors and improving overall SLAM performance. The implementation of SGLC will be released at https://github.com/nubot-nudt/SGLC.
Soft Masked Transformer for Point Cloud Processing with Skip Attention-Based Upsampling
Mar 21, 2024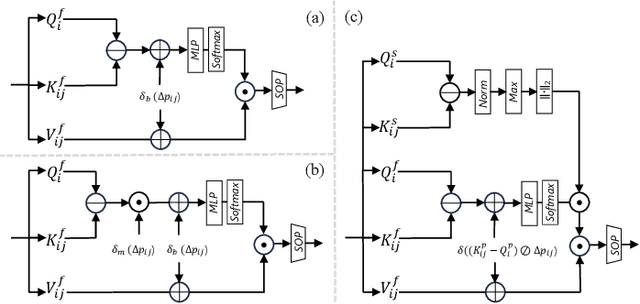
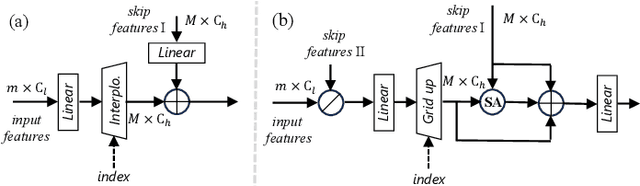
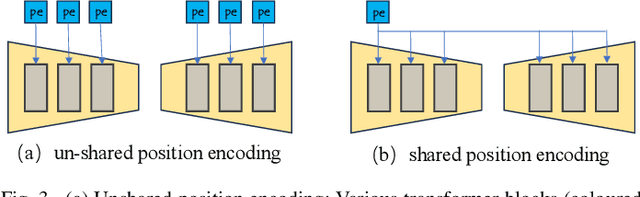
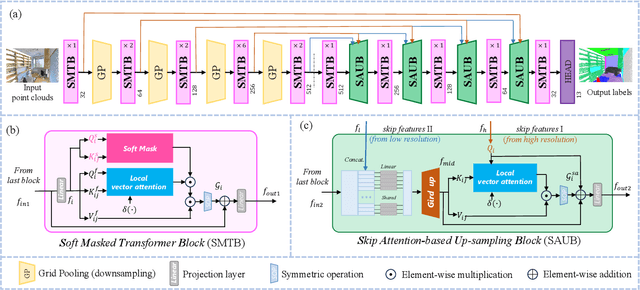
Point cloud processing methods leverage local and global point features %at the feature level to cater to downstream tasks, yet they often overlook the task-level context inherent in point clouds during the encoding stage. We argue that integrating task-level information into the encoding stage significantly enhances performance. To that end, we propose SMTransformer which incorporates task-level information into a vector-based transformer by utilizing a soft mask generated from task-level queries and keys to learn the attention weights. Additionally, to facilitate effective communication between features from the encoding and decoding layers in high-level tasks such as segmentation, we introduce a skip-attention-based up-sampling block. This block dynamically fuses features from various resolution points across the encoding and decoding layers. To mitigate the increase in network parameters and training time resulting from the complexity of the aforementioned blocks, we propose a novel shared position encoding strategy. This strategy allows various transformer blocks to share the same position information over the same resolution points, thereby reducing network parameters and training time without compromising accuracy.Experimental comparisons with existing methods on multiple datasets demonstrate the efficacy of SMTransformer and skip-attention-based up-sampling for point cloud processing tasks, including semantic segmentation and classification. In particular, we achieve state-of-the-art semantic segmentation results of 73.4% mIoU on S3DIS Area 5 and 62.4% mIoU on SWAN dataset
OST: Refining Text Knowledge with Optimal Spatio-Temporal Descriptor for General Video Recognition
Nov 30, 2023Due to the resource-intensive nature of training vision-language models on expansive video data, a majority of studies have centered on adapting pre-trained image-language models to the video domain. Dominant pipelines propose to tackle the visual discrepancies with additional temporal learners while overlooking the substantial discrepancy for web-scaled descriptive narratives and concise action category names, leading to less distinct semantic space and potential performance limitations. In this work, we prioritize the refinement of text knowledge to facilitate generalizable video recognition. To address the limitations of the less distinct semantic space of category names, we prompt a large language model (LLM) to augment action class names into Spatio-Temporal Descriptors thus bridging the textual discrepancy and serving as a knowledge base for general recognition. Moreover, to assign the best descriptors with different video instances, we propose Optimal Descriptor Solver, forming the video recognition problem as solving the optimal matching flow across frame-level representations and descriptors. Comprehensive evaluations in zero-shot, few-shot, and fully supervised video recognition highlight the effectiveness of our approach. Our best model achieves a state-of-the-art zero-shot accuracy of 75.1% on Kinetics-600.
First Place Solution to the CVPR'2023 AQTC Challenge: A Function-Interaction Centric Approach with Spatiotemporal Visual-Language Alignment
Jun 23, 2023



Affordance-Centric Question-driven Task Completion (AQTC) has been proposed to acquire knowledge from videos to furnish users with comprehensive and systematic instructions. However, existing methods have hitherto neglected the necessity of aligning spatiotemporal visual and linguistic signals, as well as the crucial interactional information between humans and objects. To tackle these limitations, we propose to combine large-scale pre-trained vision-language and video-language models, which serve to contribute stable and reliable multimodal data and facilitate effective spatiotemporal visual-textual alignment. Additionally, a novel hand-object-interaction (HOI) aggregation module is proposed which aids in capturing human-object interaction information, thereby further augmenting the capacity to understand the presented scenario. Our method achieved first place in the CVPR'2023 AQTC Challenge, with a Recall@1 score of 78.7\%. The code is available at https://github.com/tomchen-ctj/CVPR23-LOVEU-AQTC.
DANet: Density Adaptive Convolutional Network with Interactive Attention for 3D Point Clouds
Mar 08, 2023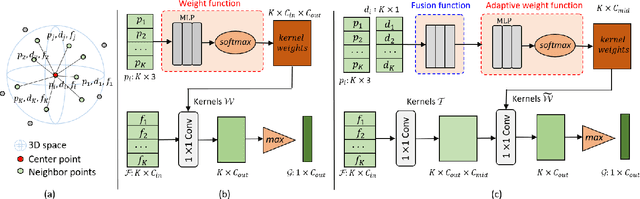
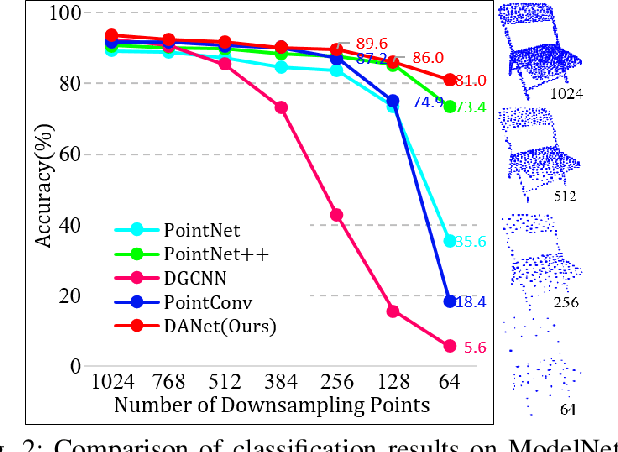
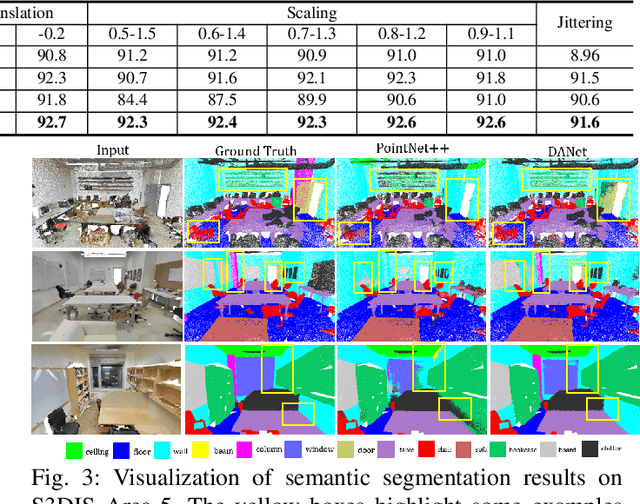
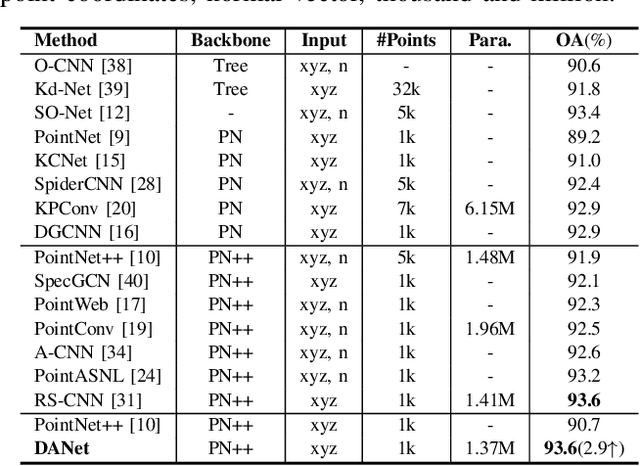
Local features and contextual dependencies are crucial for 3D point cloud analysis. Many works have been devoted to designing better local convolutional kernels that exploit the contextual dependencies. However, current point convolutions lack robustness to varying point cloud density. Moreover, contextual modeling is dominated by non-local or self-attention models which are computationally expensive. To solve these problems, we propose density adaptive convolution, coined DAConv. The key idea is to adaptively learn the convolutional weights from geometric connections obtained from the point density and position. To extract precise context dependencies with fewer computations, we propose an interactive attention module (IAM) that embeds spatial information into channel attention along different spatial directions. DAConv and IAM are integrated in a hierarchical network architecture to achieve local density and contextual direction-aware learning for point cloud analysis. Experiments show that DAConv is significantly more robust to point density compared to existing methods and extensive comparisons on challenging 3D point cloud datasets show that our network achieves state-of-the-art classification results of 93.6% on ModelNet40, competitive semantic segmentation results of 68.71% mIoU on S3DIS and part segmentation results of 86.7% mIoU on ShapeNet.
Full Point Encoding for Local Feature Aggregation in 3D Point Clouds
Mar 08, 2023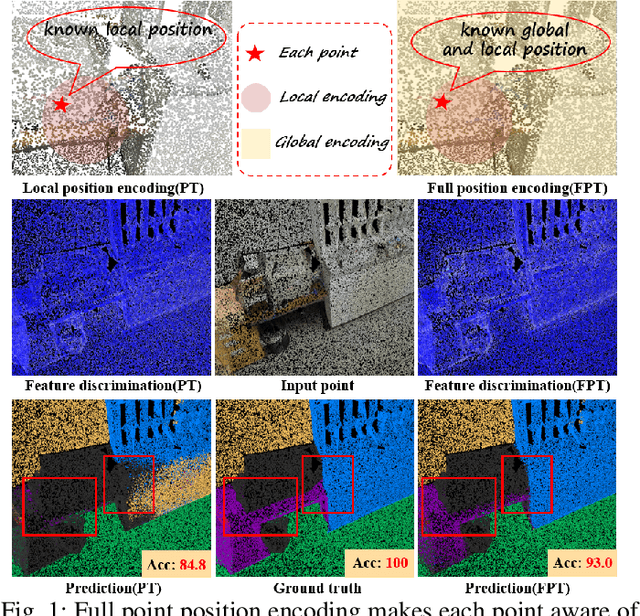
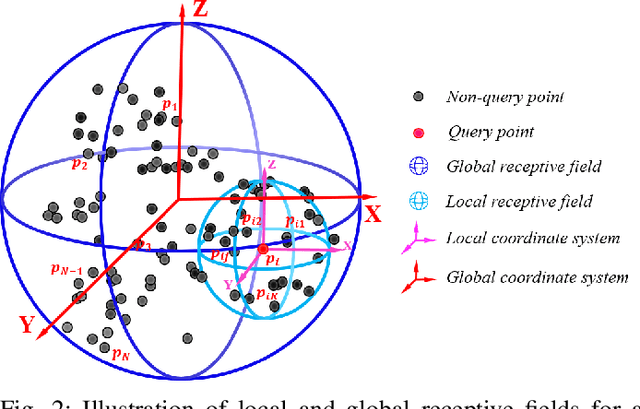
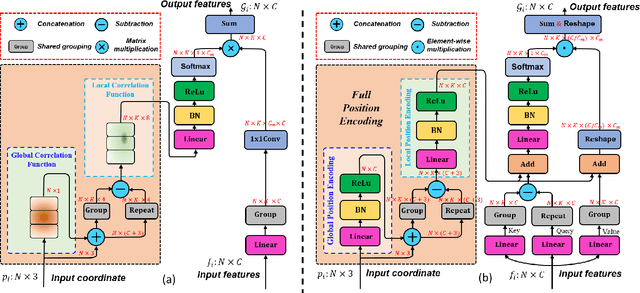
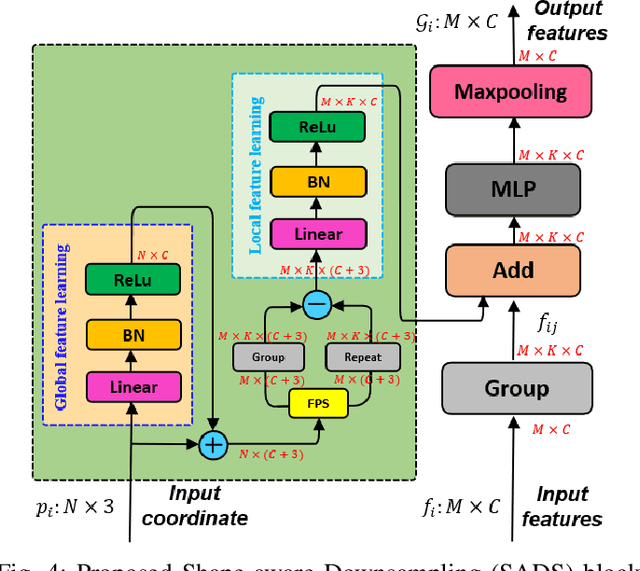
Point cloud processing methods exploit local point features and global context through aggregation which does not explicity model the internal correlations between local and global features. To address this problem, we propose full point encoding which is applicable to convolution and transformer architectures. Specifically, we propose Full Point Convolution (FPConv) and Full Point Transformer (FPTransformer) architectures. The key idea is to adaptively learn the weights from local and global geometric connections, where the connections are established through local and global correlation functions respectively. FPConv and FPTransformer simultaneously model the local and global geometric relationships as well as their internal correlations, demonstrating strong generalization ability and high performance. FPConv is incorporated in classical hierarchical network architectures to achieve local and global shape-aware learning. In FPTransformer, we introduce full point position encoding in self-attention, that hierarchically encodes each point position in the global and local receptive field. We also propose a shape aware downsampling block which takes into account the local shape and the global context. Experimental comparison to existing methods on benchmark datasets show the efficacy of FPConv and FPTransformer for semantic segmentation, object detection, classification, and normal estimation tasks. In particular, we achieve state-of-the-art semantic segmentation results of 76% mIoU on S3DIS 6-fold and 72.2% on S3DIS Area5.