 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Next Layer: Augmenting Foundation Models with Structure-Preserving and Attention-Guided Learning for Local Patches to Global Context Awareness in Computational Pathology
Aug 27, 2025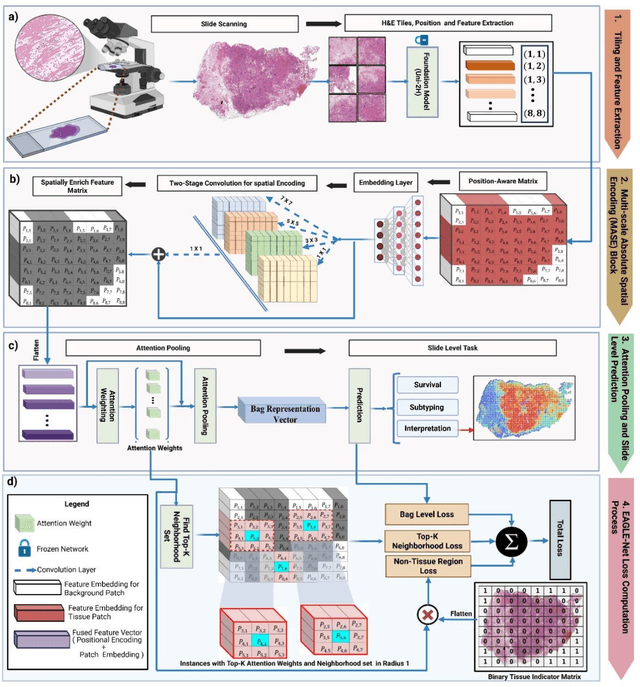
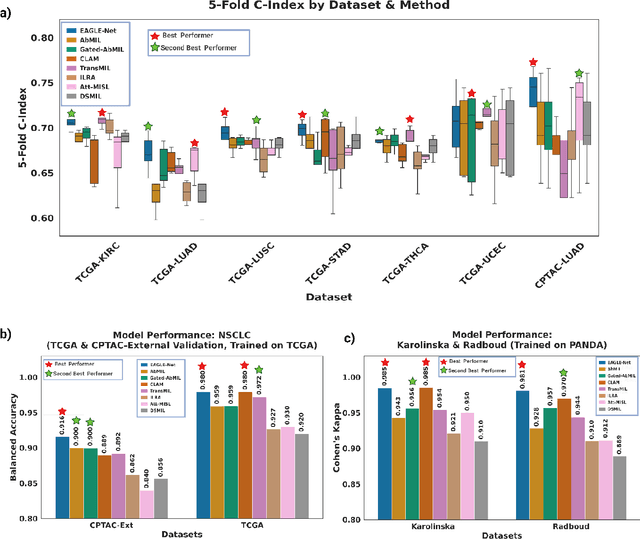
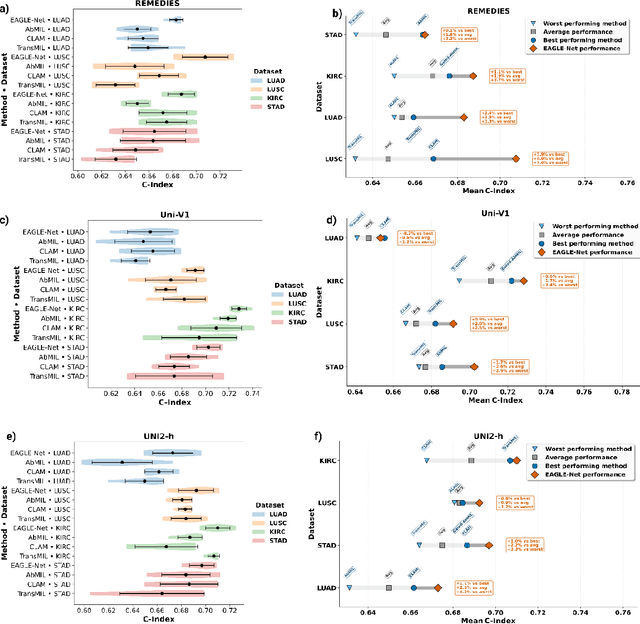
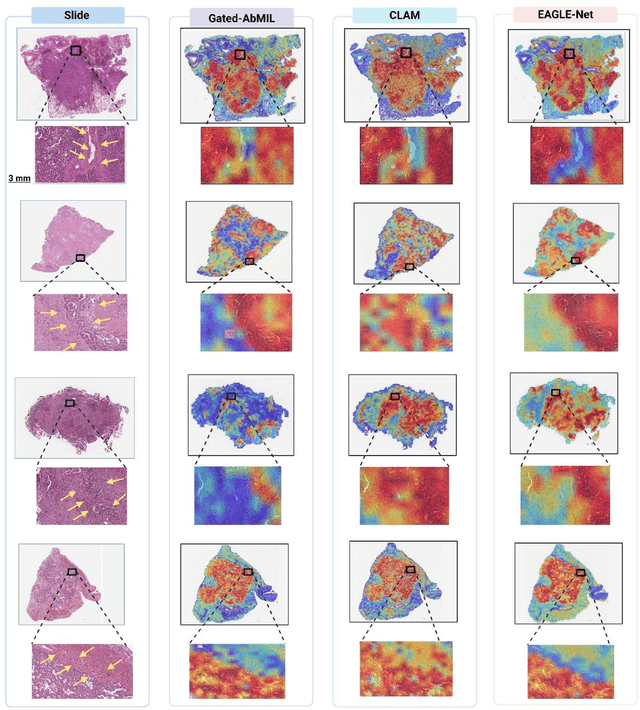
Foundation models have recently emerged as powerful feature extractors in computational pathology, yet they typically omit mechanisms for leveraging the global spatial structure of tissues and the local contextual relationships among diagnostically relevant regions - key elements for understanding the tumor microenvironment. Multiple instance learning (MIL) remains an essential next step following foundation model, designing a framework to aggregate patch-level features into slide-level predictions. We present EAGLE-Net, a structure-preserving, attention-guided MIL architecture designed to augment prediction and interpretability. EAGLE-Net integrates multi-scale absolute spatial encoding to capture global tissue architecture, a top-K neighborhood-aware loss to focus attention on local microenvironments, and background suppression loss to minimize false positives. We benchmarked EAGLE-Net on large pan-cancer datasets, including three cancer types for classification (10,260 slides) and seven cancer types for survival prediction (4,172 slides), using three distinct histology foundation backbones (REMEDIES, Uni-V1, Uni2-h). Across tasks, EAGLE-Net achieved up to 3% higher classification accuracy and the top concordance indices in 6 of 7 cancer types, producing smooth, biologically coherent attention maps that aligned with expert annotations and highlighted invasive fronts, necrosis, and immune infiltration. These results position EAGLE-Net as a generalizable, interpretable framework that complements foundation models, enabling improved biomarker discovery, prognostic modeling, and clinical decision support
Deep learning based infrared small object segmentation: Challenges and future directions
Feb 20, 2025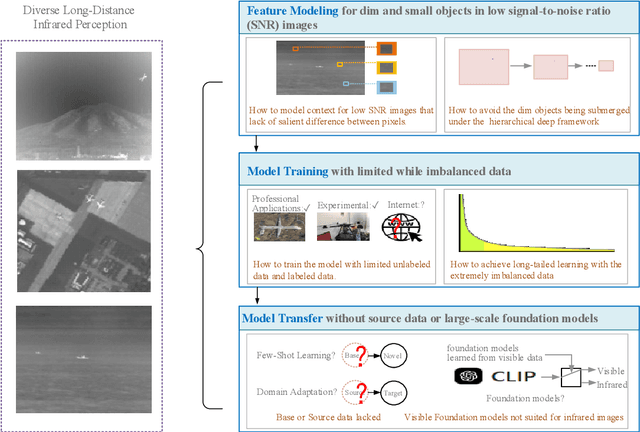

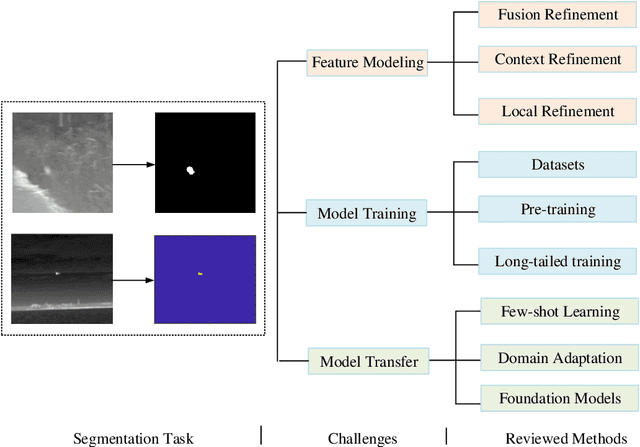

Infrared sensing is a core method for supporting unmanned systems, such as autonomous vehicles and drones. Recently, infrared sensors have been widely deployed on mobile and stationary platforms for detection and classification of objects from long distances and in wide field of views. Given its success in the vision image analysis domain, deep learning has also been applied for object recognition in infrared images. However, techniques that have proven successful in visible light perception face new challenges in the infrared domain. These challenges include extremely low signal-to-noise ratios in infrared images, very small and blurred objects of interest, and limited availability of labeled/unlabeled training data due to the specialized nature of infrared sensors. Numerous methods have been proposed in the literature for the detection and classification of small objects in infrared images achieving varied levels of success. There is a need for a survey paper that critically analyzes existing techniques in this domain, identifies unsolved challenges and provides future research directions. This paper fills the gap and offers a concise and insightful review of deep learning-based methods. It also identifies the challenges faced by existing infrared object segmentation methods and provides a structured review of existing infrared perception methods from the perspective of these challenges and highlights the motivations behind the various approaches. Finally, this review suggests promising future directions based on recent advancements within this domain.
A practical generalization metric for deep networks benchmarking
Sep 02, 2024There is an ongoing and dedicated effort to estimate bounds on the generalization error of deep learning models, coupled with an increasing interest with practical metrics that can be used to experimentally evaluate a model's ability to generalize. This interest is not only driven by practical considerations but is also vital for theoretical research, as theoretical estimations require practical validation. However, there is currently a lack of research on benchmarking the generalization capacity of various deep networks and verifying these theoretical estimations. This paper aims to introduce a practical generalization metric for benchmarking different deep networks and proposes a novel testbed for the verification of theoretical estimations. Our findings indicate that a deep network's generalization capacity in classification tasks is contingent upon both classification accuracy and the diversity of unseen data. The proposed metric system is capable of quantifying the accuracy of deep learning models and the diversity of data, providing an intuitive and quantitative evaluation method, a trade-off point. Furthermore, we compare our practical metric with existing generalization theoretical estimations using our benchmarking testbed. It is discouraging to note that most of the available generalization estimations do not correlate with the practical measurements obtained using our proposed practical metric. On the other hand, this finding is significant as it exposes the shortcomings of theoretical estimations and inspires new exploration.
Advancing COVID-19 Diagnosis with Privacy-Preserving Collaboration in Artificial Intelligence
Nov 18, 2021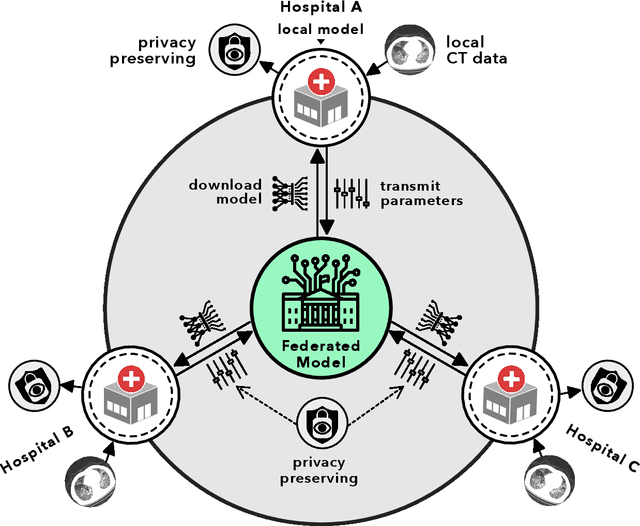
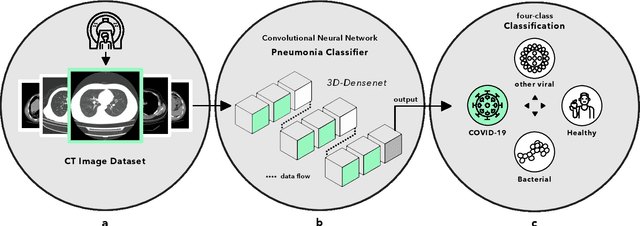
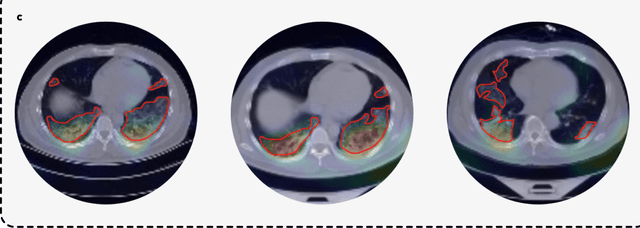
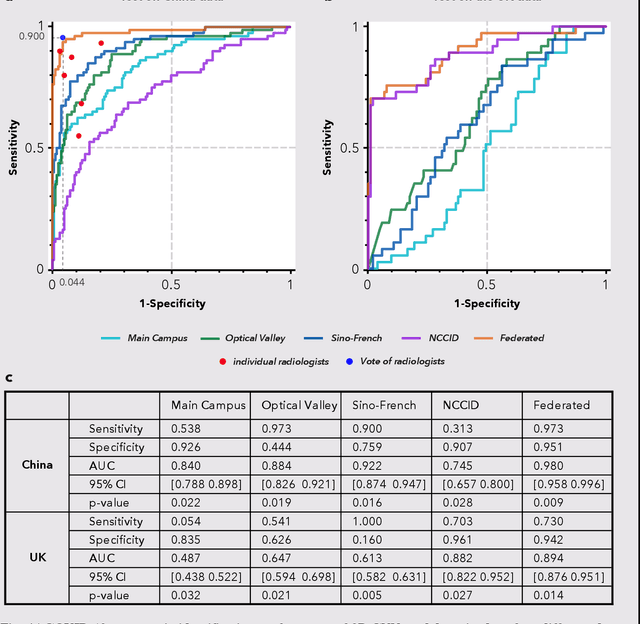
Artificial intelligence (AI) provides a promising substitution for streamlining COVID-19 diagnoses. However, concerns surrounding security and trustworthiness impede the collection of large-scale representative medical data, posing a considerable challenge for training a well-generalised model in clinical practices. To address this, we launch the Unified CT-COVID AI Diagnostic Initiative (UCADI), where the AI model can be distributedly trained and independently executed at each host institution under a federated learning framework (FL) without data sharing. Here we show that our FL model outperformed all the local models by a large yield (test sensitivity /specificity in China: 0.973/0.951, in the UK: 0.730/0.942), achieving comparable performance with a panel of professional radiologists. We further evaluated the model on the hold-out (collected from another two hospitals leaving out the FL) and heterogeneous (acquired with contrast materials) data, provided visual explanations for decisions made by the model, and analysed the trade-offs between the model performance and the communication costs in the federated training process. Our study is based on 9,573 chest computed tomography scans (CTs) from 3,336 patients collected from 23 hospitals located in China and the UK. Collectively, our work advanced the prospects of utilising federated learning for privacy-preserving AI in digital health.
Harvesting Visual Objects from Internet Images via Deep Learning Based Objectness Assessment
Apr 01, 2019



The collection of internet images has been growing in an astonishing speed. It is undoubted that these images contain rich visual information that can be useful in many applications, such as visual media creation and data-driven image synthesis. In this paper, we focus on the methodologies for building a visual object database from a collection of internet images. Such database is built to contain a large number of high-quality visual objects that can help with various data-driven image applications. Our method is based on dense proposal generation and objectness-based re-ranking. A novel deep convolutional neural network is designed for the inference of proposal objectness, the probability of a proposal containing optimally-located foreground object. In our work, the objectness is quantitatively measured in regard of completeness and fullness, reflecting two complementary features of an optimal proposal: a complete foreground and relatively small background. Our experiments indicate that object proposals re-ranked according to the output of our network generally achieve higher performance than those produced by other state-of-the-art methods. As a concrete example, a database of over 1.2 million visual objects has been built using the proposed method, and has been successfully used in various data-driven image applications.