 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMagicAnime: A Hierarchically Annotated, Multimodal and Multitasking Dataset with Benchmarks for Cartoon Animation Generation
Jul 27, 2025Generating high-quality cartoon animations multimodal control is challenging due to the complexity of non-human characters, stylistically diverse motions and fine-grained emotions. There is a huge domain gap between real-world videos and cartoon animation, as cartoon animation is usually abstract and has exaggerated motion. Meanwhile, public multimodal cartoon data are extremely scarce due to the difficulty of large-scale automatic annotation processes compared with real-life scenarios. To bridge this gap, We propose the MagicAnime dataset, a large-scale, hierarchically annotated, and multimodal dataset designed to support multiple video generation tasks, along with the benchmarks it includes. Containing 400k video clips for image-to-video generation, 50k pairs of video clips and keypoints for whole-body annotation, 12k pairs of video clips for video-to-video face animation, and 2.9k pairs of video and audio clips for audio-driven face animation. Meanwhile, we also build a set of multi-modal cartoon animation benchmarks, called MagicAnime-Bench, to support the comparisons of different methods in the tasks above. Comprehensive experiments on four tasks, including video-driven face animation, audio-driven face animation, image-to-video animation, and pose-driven character animation, validate its effectiveness in supporting high-fidelity, fine-grained, and controllable generation.
A practical generalization metric for deep networks benchmarking
Sep 02, 2024There is an ongoing and dedicated effort to estimate bounds on the generalization error of deep learning models, coupled with an increasing interest with practical metrics that can be used to experimentally evaluate a model's ability to generalize. This interest is not only driven by practical considerations but is also vital for theoretical research, as theoretical estimations require practical validation. However, there is currently a lack of research on benchmarking the generalization capacity of various deep networks and verifying these theoretical estimations. This paper aims to introduce a practical generalization metric for benchmarking different deep networks and proposes a novel testbed for the verification of theoretical estimations. Our findings indicate that a deep network's generalization capacity in classification tasks is contingent upon both classification accuracy and the diversity of unseen data. The proposed metric system is capable of quantifying the accuracy of deep learning models and the diversity of data, providing an intuitive and quantitative evaluation method, a trade-off point. Furthermore, we compare our practical metric with existing generalization theoretical estimations using our benchmarking testbed. It is discouraging to note that most of the available generalization estimations do not correlate with the practical measurements obtained using our proposed practical metric. On the other hand, this finding is significant as it exposes the shortcomings of theoretical estimations and inspires new exploration.
GSDeformer: Direct Cage-based Deformation for 3D Gaussian Splatting
May 24, 2024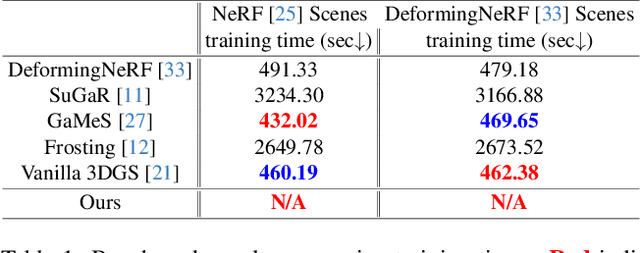
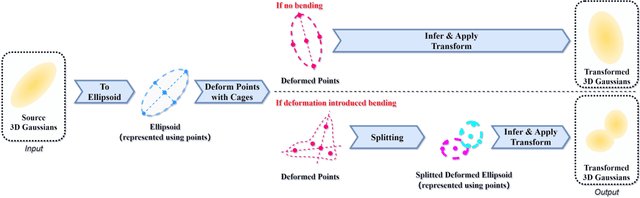

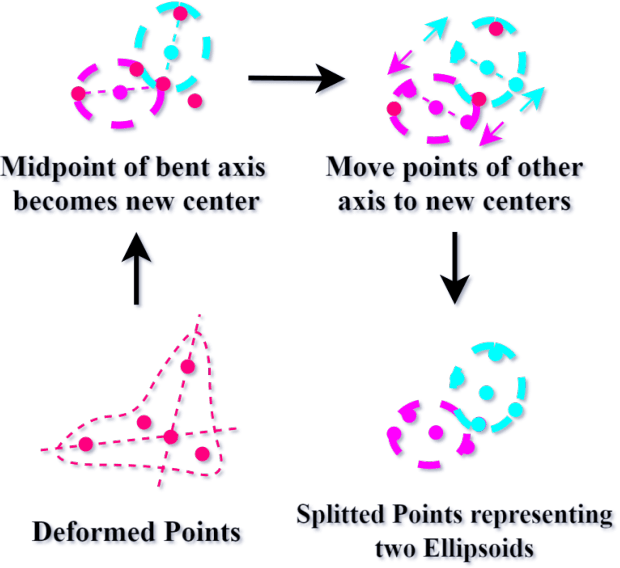
We present GSDeformer, a method that achieves free-form deformation on 3D Gaussian Splatting(3DGS) without requiring any architectural changes. Our method extends cage-based deformation, a traditional mesh deformation method, to 3DGS. This is done by converting 3DGS into a novel proxy point cloud representation, where its deformation can be used to infer the transformations to apply on the 3D gaussians making up 3DGS. We also propose an automatic cage construction algorithm for 3DGS to minimize manual work. Our method does not modify the underlying architecture of 3DGS. Therefore, any existing trained vanilla 3DGS can be easily edited by our method. We compare the deformation capability of our method against other existing methods, demonstrating the ease of use and comparable quality of our method, despite being more direct and thus easier to integrate with other concurrent developments on 3DGS.
A Novel Implicit Neural Representation for Volume Data
Mar 13, 2024The storage of medical images is one of the challenges in the medical imaging field. There are variable works that use implicit neural representation (INR) to compress volumetric medical images. However, there is room to improve the compression rate for volumetric medical images. Most of the INR techniques need a huge amount of GPU memory and a long training time for high-quality medical volume rendering. In this paper, we present a novel implicit neural representation to compress volume data using our proposed architecture, that is, the Lanczos downsampling scheme, SIREN deep network, and SRDenseNet high-resolution scheme. Our architecture can effectively reduce training time, and gain a high compression rate while retaining the final rendering quality. Moreover, it can save GPU memory in comparison with the existing works. The experiments show that the quality of reconstructed images and training speed using our architecture is higher than current works which use the SIREN only. Besides, the GPU memory cost is evidently decreased
Point'n Move: Interactive Scene Object Manipulation on Gaussian Splatting Radiance Fields
Nov 28, 2023



We propose Point'n Move, a method that achieves interactive scene object manipulation with exposed region inpainting. Interactivity here further comes from intuitive object selection and real-time editing. To achieve this, we adopt Gaussian Splatting Radiance Field as the scene representation and fully leverage its explicit nature and speed advantage. Its explicit representation formulation allows us to devise a 2D prompt points to 3D mask dual-stage self-prompting segmentation algorithm, perform mask refinement and merging, minimize change as well as provide good initialization for scene inpainting and perform editing in real-time without per-editing training, all leads to superior quality and performance. We test our method by performing editing on both forward-facing and 360 scenes. We also compare our method against existing scene object removal methods, showing superior quality despite being more capable and having a speed advantage.