 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeViC-Bench: Benchmarking Visual-Interleaved Chain-of-Thought Capability in MLLMs with Free-Style Intermediate State Representations
May 20, 2025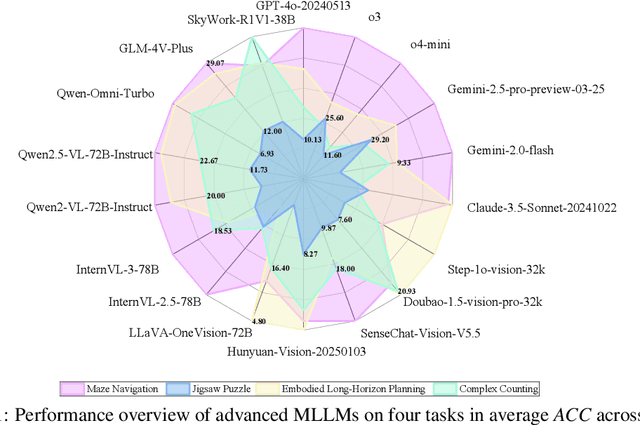

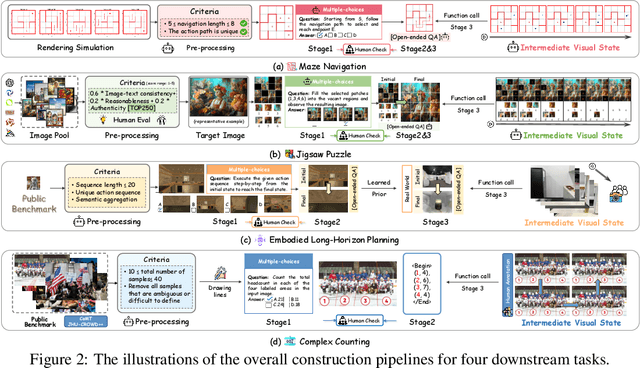
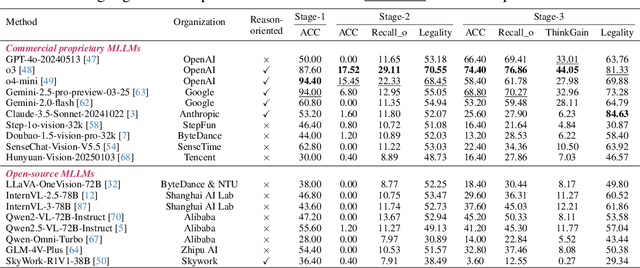
Visual-Interleaved Chain-of-Thought (VI-CoT) enables MLLMs to continually update their understanding and decisions based on step-wise intermediate visual states (IVS), much like a human would, which demonstrates impressive success in various tasks, thereby leading to emerged advancements in related benchmarks. Despite promising progress, current benchmarks provide models with relatively fixed IVS, rather than free-style IVS, whch might forcibly distort the original thinking trajectories, failing to evaluate their intrinsic reasoning capabilities. More importantly, existing benchmarks neglect to systematically explore the impact factors that IVS would impart to untamed reasoning performance. To tackle above gaps, we introduce a specialized benchmark termed ViC-Bench, consisting of four representive tasks: maze navigation, jigsaw puzzle, embodied long-horizon planning, and complex counting, where each task has dedicated free-style IVS generation pipeline supporting function calls. To systematically examine VI-CoT capability, we propose a thorough evaluation suite incorporating a progressive three-stage strategy with targeted new metrics. Besides, we establish Incremental Prompting Information Injection (IPII) strategy to ablatively explore the prompting factors for VI-CoT. We extensively conduct evaluations for 18 advanced MLLMs, revealing key insights into their VI-CoT capability. Our proposed benchmark is publicly open at Huggingface.
Towards Automatic Evaluation for LLMs' Clinical Capabilities: Metric, Data, and Algorithm
Mar 25, 2024



Large language models (LLMs) are gaining increasing interests to improve clinical efficiency for medical diagnosis, owing to their unprecedented performance in modelling natural language. Ensuring the safe and reliable clinical applications, the evaluation of LLMs indeed becomes critical for better mitigating the potential risks, e.g., hallucinations. However, current evaluation methods heavily rely on labor-intensive human participation to achieve human-preferred judgements. To overcome this challenge, we propose an automatic evaluation paradigm tailored to assess the LLMs' capabilities in delivering clinical services, e.g., disease diagnosis and treatment. The evaluation paradigm contains three basic elements: metric, data, and algorithm. Specifically, inspired by professional clinical practice pathways, we formulate a LLM-specific clinical pathway (LCP) to define the clinical capabilities that a doctor agent should possess. Then, Standardized Patients (SPs) from the medical education are introduced as the guideline for collecting medical data for evaluation, which can well ensure the completeness of the evaluation procedure. Leveraging these steps, we develop a multi-agent framework to simulate the interactive environment between SPs and a doctor agent, which is equipped with a Retrieval-Augmented Evaluation (RAE) to determine whether the behaviors of a doctor agent are in accordance with LCP. The above paradigm can be extended to any similar clinical scenarios to automatically evaluate the LLMs' medical capabilities. Applying such paradigm, we construct an evaluation benchmark in the field of urology, including a LCP, a SPs dataset, and an automated RAE. Extensive experiments are conducted to demonstrate the effectiveness of the proposed approach, providing more insights for LLMs' safe and reliable deployments in clinical practice.
Semi-supervised Body Parsing and Pose Estimation for Enhancing Infant General Movement Assessment
Oct 14, 2022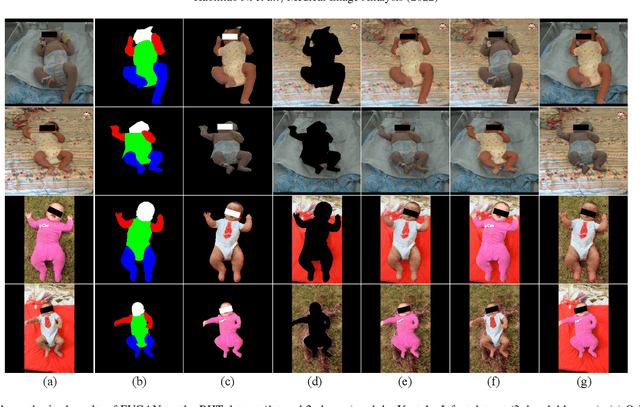
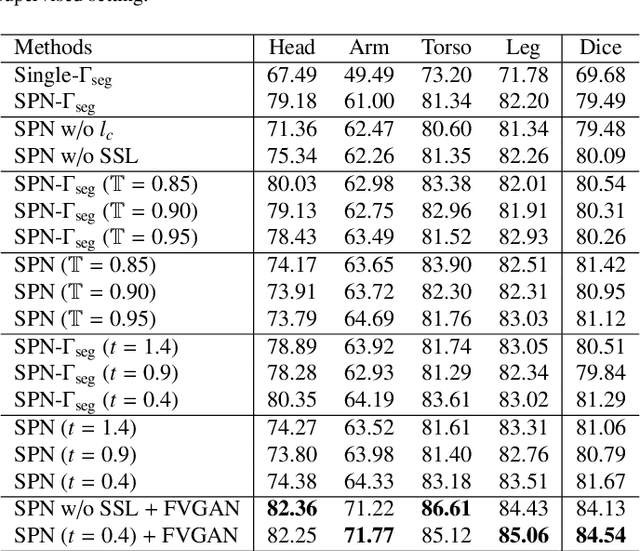
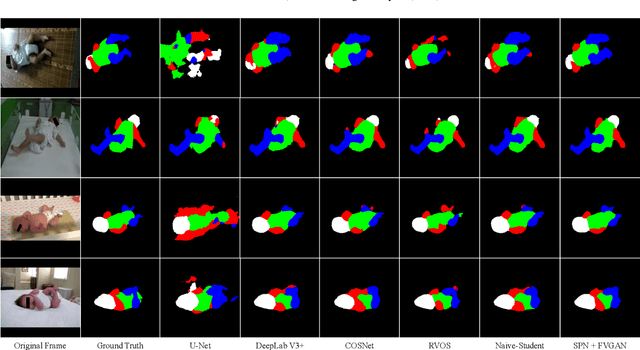
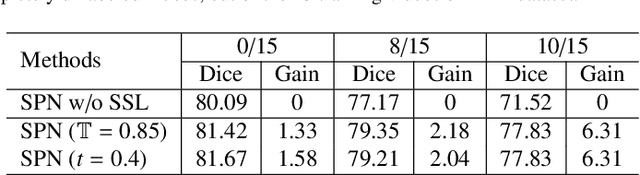
General movement assessment (GMA) of infant movement videos (IMVs) is an effective method for early detection of cerebral palsy (CP) in infants. We demonstrate in this paper that end-to-end trainable neural networks for image sequence recognition can be applied to achieve good results in GMA, and more importantly, augmenting raw video with infant body parsing and pose estimation information can significantly improve performance. To solve the problem of efficiently utilizing partially labeled IMVs for body parsing, we propose a semi-supervised model, termed SiamParseNet (SPN), which consists of two branches, one for intra-frame body parts segmentation and another for inter-frame label propagation. During training, the two branches are jointly trained by alternating between using input pairs of only labeled frames and input of both labeled and unlabeled frames. We also investigate training data augmentation by proposing a factorized video generative adversarial network (FVGAN) to synthesize novel labeled frames for training. When testing, we employ a multi-source inference mechanism, where the final result for a test frame is either obtained via the segmentation branch or via propagation from a nearby key frame. We conduct extensive experiments for body parsing using SPN on two infant movement video datasets, where SPN coupled with FVGAN achieves state-of-the-art performance. We further demonstrate that SPN can be easily adapted to the infant pose estimation task with superior performance. Last but not least, we explore the clinical application of our method for GMA. We collected a new clinical IMV dataset with GMA annotations, and our experiments show that SPN models for body parsing and pose estimation trained on the first two datasets generalize well to the new clinical dataset and their results can significantly boost the CRNN-based GMA prediction performance.
AggPose: Deep Aggregation Vision Transformer for Infant Pose Estimation
May 11, 2022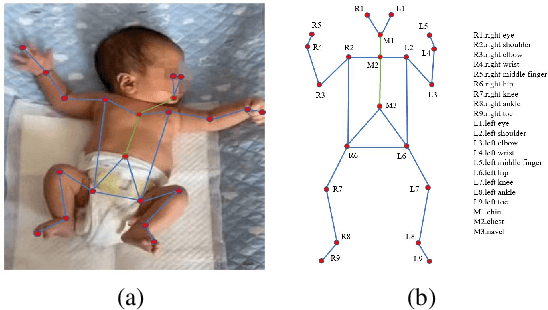

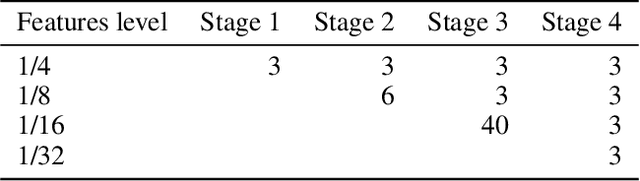

Movement and pose assessment of newborns lets experienced pediatricians predict neurodevelopmental disorders, allowing early intervention for related diseases. However, most of the newest AI approaches for human pose estimation methods focus on adults, lacking publicly benchmark for infant pose estimation. In this paper, we fill this gap by proposing infant pose dataset and Deep Aggregation Vision Transformer for human pose estimation, which introduces a fast trained full transformer framework without using convolution operations to extract features in the early stages. It generalizes Transformer + MLP to high-resolution deep layer aggregation within feature maps, thus enabling information fusion between different vision levels. We pre-train AggPose on COCO pose dataset and apply it on our newly released large-scale infant pose estimation dataset. The results show that AggPose could effectively learn the multi-scale features among different resolutions and significantly improve the performance of infant pose estimation. We show that AggPose outperforms hybrid model HRFormer and TokenPose in the infant pose estimation dataset. Moreover, our AggPose outperforms HRFormer by 0.7% AP on COCO val pose estimation on average. Our code is available at github.com/SZAR-LAB/AggPose.
Advancing COVID-19 Diagnosis with Privacy-Preserving Collaboration in Artificial Intelligence
Nov 18, 2021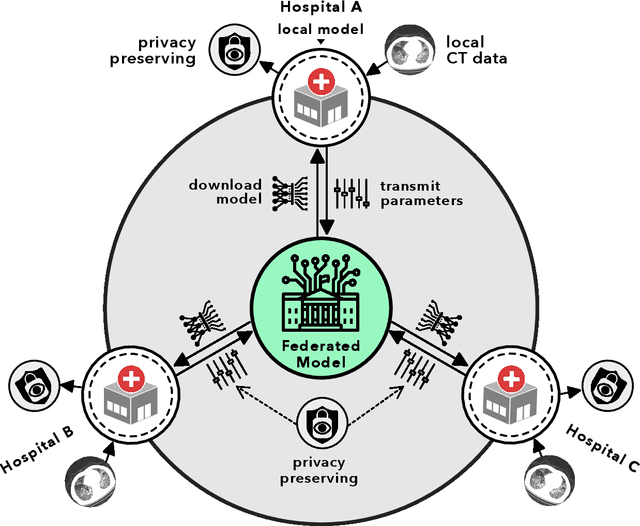
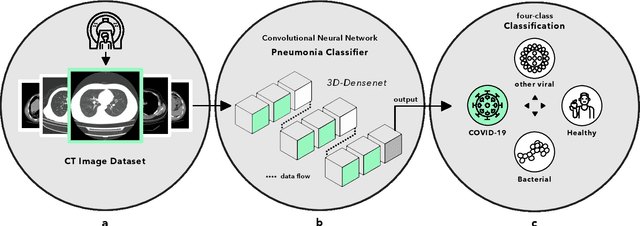
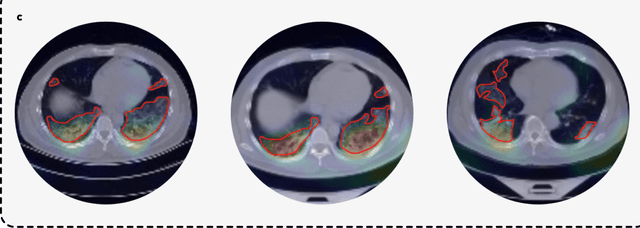
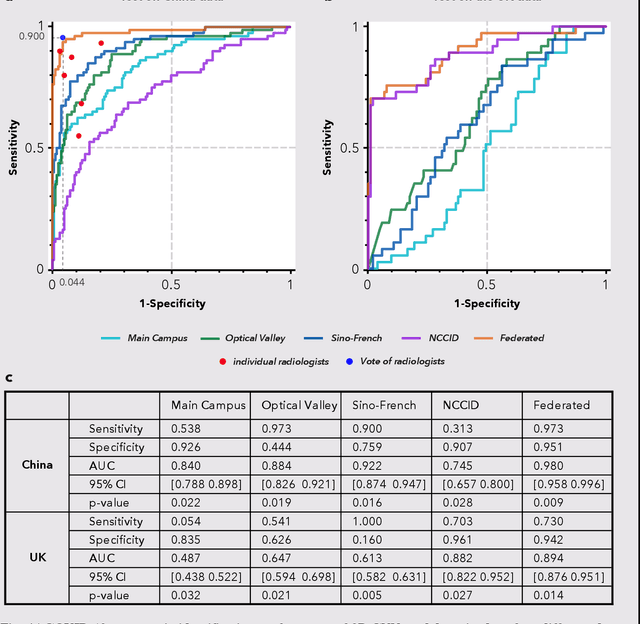
Artificial intelligence (AI) provides a promising substitution for streamlining COVID-19 diagnoses. However, concerns surrounding security and trustworthiness impede the collection of large-scale representative medical data, posing a considerable challenge for training a well-generalised model in clinical practices. To address this, we launch the Unified CT-COVID AI Diagnostic Initiative (UCADI), where the AI model can be distributedly trained and independently executed at each host institution under a federated learning framework (FL) without data sharing. Here we show that our FL model outperformed all the local models by a large yield (test sensitivity /specificity in China: 0.973/0.951, in the UK: 0.730/0.942), achieving comparable performance with a panel of professional radiologists. We further evaluated the model on the hold-out (collected from another two hospitals leaving out the FL) and heterogeneous (acquired with contrast materials) data, provided visual explanations for decisions made by the model, and analysed the trade-offs between the model performance and the communication costs in the federated training process. Our study is based on 9,573 chest computed tomography scans (CTs) from 3,336 patients collected from 23 hospitals located in China and the UK. Collectively, our work advanced the prospects of utilising federated learning for privacy-preserving AI in digital health.