 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSeeing Clearly, Reasoning Confidently: Plug-and-Play Remedies for Vision Language Model Blindness
Feb 23, 2026Vision language models (VLMs) have achieved remarkable success in broad visual understanding, yet they remain challenged by object-centric reasoning on rare objects due to the scarcity of such instances in pretraining data. While prior efforts alleviate this issue by retrieving additional data or introducing stronger vision encoders, these methods are still computationally intensive during finetuning VLMs and don't fully exploit the original training data. In this paper, we introduce an efficient plug-and-play module that substantially improves VLMs' reasoning over rare objects by refining visual tokens and enriching input text prompts, without VLMs finetuning. Specifically, we propose to learn multi-modal class embeddings for rare objects by leveraging prior knowledge from vision foundation models and synonym-augmented text descriptions, compensating for limited training examples. These embeddings refine the visual tokens in VLMs through a lightweight attention-based enhancement module that improves fine-grained object details. In addition, we use the learned embeddings as object-aware detectors to generate informative hints, which are injected into the text prompts to help guide the VLM's attention toward relevant image regions. Experiments on two benchmarks show consistent and substantial gains for pretrained VLMs in rare object recognition and reasoning. Further analysis reveals how our method strengthens the VLM's ability to focus on and reason about rare objects.
Computer-Aided Layout Generation for Building Design: A Review
Apr 13, 2025
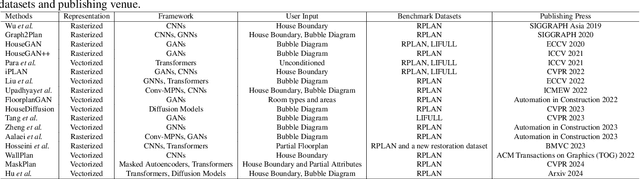

Generating realistic building layouts for automatic building design has been studied in both the computer vision and architecture domains. Traditional approaches from the architecture domain, which are based on optimization techniques or heuristic design guidelines, can synthesize desirable layouts, but usually require post-processing and involve human interaction in the design pipeline, making them costly and timeconsuming. The advent of deep generative models has significantly improved the fidelity and diversity of the generated architecture layouts, reducing the workload by designers and making the process much more efficient. In this paper, we conduct a comprehensive review of three major research topics of architecture layout design and generation: floorplan layout generation, scene layout synthesis, and generation of some other formats of building layouts. For each topic, we present an overview of the leading paradigms, categorized either by research domains (architecture or machine learning) or by user input conditions or constraints. We then introduce the commonly-adopted benchmark datasets that are used to verify the effectiveness of the methods, as well as the corresponding evaluation metrics. Finally, we identify the well-solved problems and limitations of existing approaches, then propose new perspectives as promising directions for future research in this important research area. A project associated with this survey to maintain the resources is available at awesome-building-layout-generation.
TI2V-Zero: Zero-Shot Image Conditioning for Text-to-Video Diffusion Models
Apr 25, 2024



Text-conditioned image-to-video generation (TI2V) aims to synthesize a realistic video starting from a given image (e.g., a woman's photo) and a text description (e.g., "a woman is drinking water."). Existing TI2V frameworks often require costly training on video-text datasets and specific model designs for text and image conditioning. In this paper, we propose TI2V-Zero, a zero-shot, tuning-free method that empowers a pretrained text-to-video (T2V) diffusion model to be conditioned on a provided image, enabling TI2V generation without any optimization, fine-tuning, or introducing external modules. Our approach leverages a pretrained T2V diffusion foundation model as the generative prior. To guide video generation with the additional image input, we propose a "repeat-and-slide" strategy that modulates the reverse denoising process, allowing the frozen diffusion model to synthesize a video frame-by-frame starting from the provided image. To ensure temporal continuity, we employ a DDPM inversion strategy to initialize Gaussian noise for each newly synthesized frame and a resampling technique to help preserve visual details. We conduct comprehensive experiments on both domain-specific and open-domain datasets, where TI2V-Zero consistently outperforms a recent open-domain TI2V model. Furthermore, we show that TI2V-Zero can seamlessly extend to other tasks such as video infilling and prediction when provided with more images. Its autoregressive design also supports long video generation.
3D-Aware Talking-Head Video Motion Transfer
Nov 05, 2023Motion transfer of talking-head videos involves generating a new video with the appearance of a subject video and the motion pattern of a driving video. Current methodologies primarily depend on a limited number of subject images and 2D representations, thereby neglecting to fully utilize the multi-view appearance features inherent in the subject video. In this paper, we propose a novel 3D-aware talking-head video motion transfer network, Head3D, which fully exploits the subject appearance information by generating a visually-interpretable 3D canonical head from the 2D subject frames with a recurrent network. A key component of our approach is a self-supervised 3D head geometry learning module, designed to predict head poses and depth maps from 2D subject video frames. This module facilitates the estimation of a 3D head in canonical space, which can then be transformed to align with driving video frames. Additionally, we employ an attention-based fusion network to combine the background and other details from subject frames with the 3D subject head to produce the synthetic target video. Our extensive experiments on two public talking-head video datasets demonstrate that Head3D outperforms both 2D and 3D prior arts in the practical cross-identity setting, with evidence showing it can be readily adapted to the pose-controllable novel view synthesis task.
Synthetic Augmentation with Large-scale Unconditional Pre-training
Aug 08, 2023



Deep learning based medical image recognition systems often require a substantial amount of training data with expert annotations, which can be expensive and time-consuming to obtain. Recently, synthetic augmentation techniques have been proposed to mitigate the issue by generating realistic images conditioned on class labels. However, the effectiveness of these methods heavily depends on the representation capability of the trained generative model, which cannot be guaranteed without sufficient labeled training data. To further reduce the dependency on annotated data, we propose a synthetic augmentation method called HistoDiffusion, which can be pre-trained on large-scale unlabeled datasets and later applied to a small-scale labeled dataset for augmented training. In particular, we train a latent diffusion model (LDM) on diverse unlabeled datasets to learn common features and generate realistic images without conditional inputs. Then, we fine-tune the model with classifier guidance in latent space on an unseen labeled dataset so that the model can synthesize images of specific categories. Additionally, we adopt a selective mechanism to only add synthetic samples with high confidence of matching to target labels. We evaluate our proposed method by pre-training on three histopathology datasets and testing on a histopathology dataset of colorectal cancer (CRC) excluded from the pre-training datasets. With HistoDiffusion augmentation, the classification accuracy of a backbone classifier is remarkably improved by 6.4% using a small set of the original labels. Our code is available at https://github.com/karenyyy/HistoDiffAug.
Exploring Compositional Visual Generation with Latent Classifier Guidance
Apr 25, 2023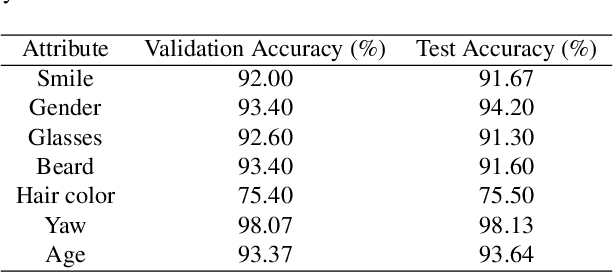



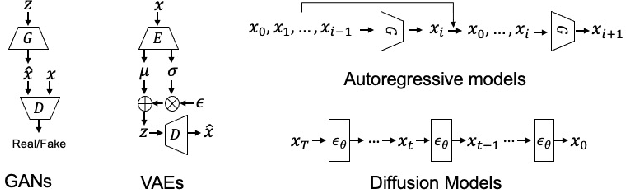
Diffusion probabilistic models have achieved enormous success in the field of image generation and manipulation. In this paper, we explore a novel paradigm of using the diffusion model and classifier guidance in the latent semantic space for compositional visual tasks. linear fashion. Specifically, we train latent diffusion models and auxiliary latent classifiers to facilitate non-linear navigation of latent representation generation for any pre-trained generative model with a semantic latent space. We demonstrate that such conditional generation achieved by latent classifier guidance provably maximizes a lower bound of the conditional log probability during training. To maintain the original semantics during manipulation, we introduce a new guidance term, which we show is crucial for achieving compositionality. With additional assumptions, we show that the non-linear manipulation reduces to a simple latent arithmetic approach. We show that this paradigm based on latent classifier guidance is agnostic to pre-trained generative models, and present competitive results for both image generation and sequential manipulation of real and synthetic images. Our findings suggest that latent classifier guidance is a promising approach that merits further exploration, even in the presence of other strong competing methods.
Conditional Image-to-Video Generation with Latent Flow Diffusion Models
Mar 24, 2023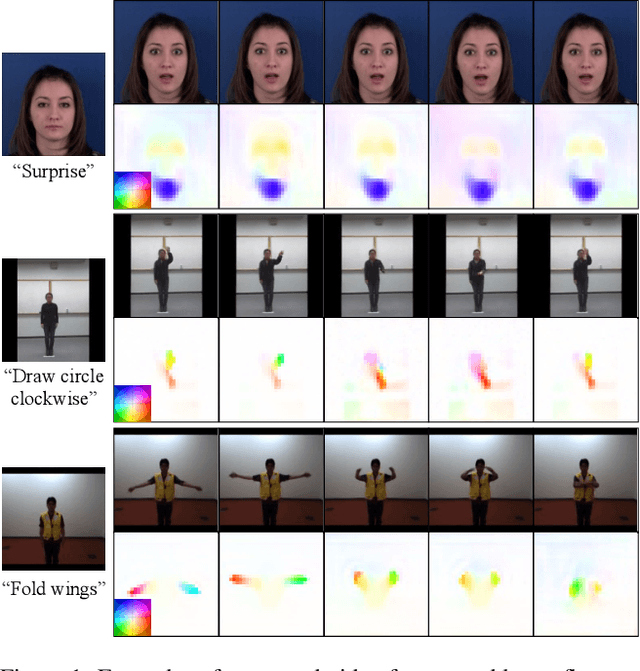

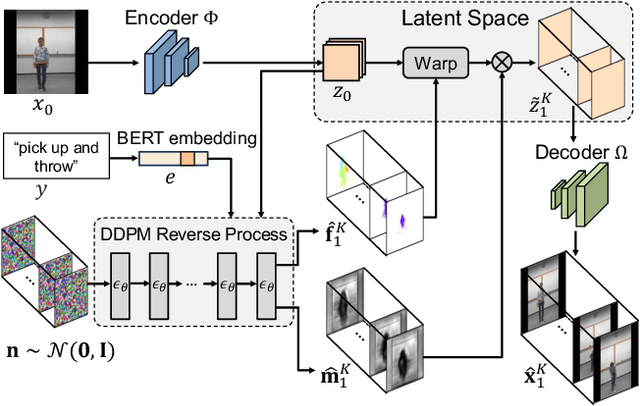

Conditional image-to-video (cI2V) generation aims to synthesize a new plausible video starting from an image (e.g., a person's face) and a condition (e.g., an action class label like smile). The key challenge of the cI2V task lies in the simultaneous generation of realistic spatial appearance and temporal dynamics corresponding to the given image and condition. In this paper, we propose an approach for cI2V using novel latent flow diffusion models (LFDM) that synthesize an optical flow sequence in the latent space based on the given condition to warp the given image. Compared to previous direct-synthesis-based works, our proposed LFDM can better synthesize spatial details and temporal motion by fully utilizing the spatial content of the given image and warping it in the latent space according to the generated temporally-coherent flow. The training of LFDM consists of two separate stages: (1) an unsupervised learning stage to train a latent flow auto-encoder for spatial content generation, including a flow predictor to estimate latent flow between pairs of video frames, and (2) a conditional learning stage to train a 3D-UNet-based diffusion model (DM) for temporal latent flow generation. Unlike previous DMs operating in pixel space or latent feature space that couples spatial and temporal information, the DM in our LFDM only needs to learn a low-dimensional latent flow space for motion generation, thus being more computationally efficient. We conduct comprehensive experiments on multiple datasets, where LFDM consistently outperforms prior arts. Furthermore, we show that LFDM can be easily adapted to new domains by simply finetuning the image decoder. Our code is available at https://github.com/nihaomiao/CVPR23_LFDM.
Semi-supervised Body Parsing and Pose Estimation for Enhancing Infant General Movement Assessment
Oct 14, 2022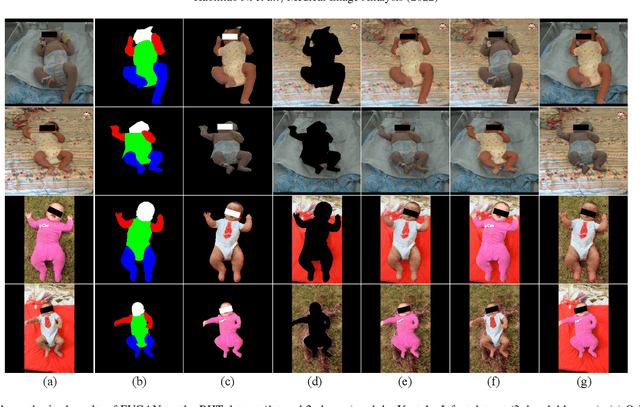
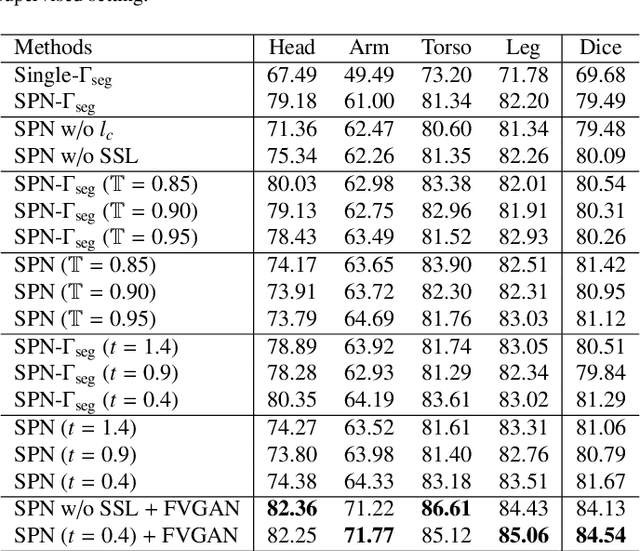
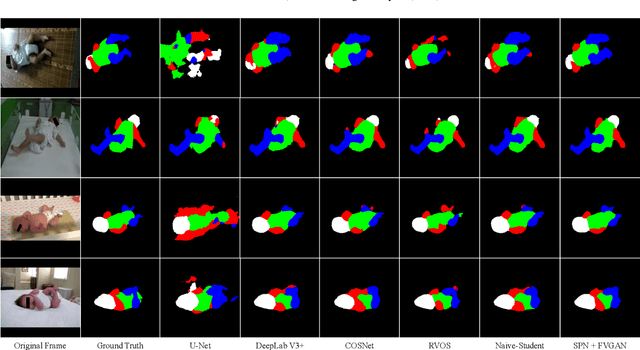
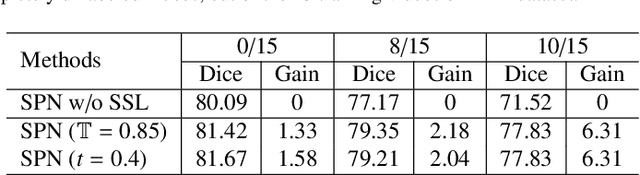
General movement assessment (GMA) of infant movement videos (IMVs) is an effective method for early detection of cerebral palsy (CP) in infants. We demonstrate in this paper that end-to-end trainable neural networks for image sequence recognition can be applied to achieve good results in GMA, and more importantly, augmenting raw video with infant body parsing and pose estimation information can significantly improve performance. To solve the problem of efficiently utilizing partially labeled IMVs for body parsing, we propose a semi-supervised model, termed SiamParseNet (SPN), which consists of two branches, one for intra-frame body parts segmentation and another for inter-frame label propagation. During training, the two branches are jointly trained by alternating between using input pairs of only labeled frames and input of both labeled and unlabeled frames. We also investigate training data augmentation by proposing a factorized video generative adversarial network (FVGAN) to synthesize novel labeled frames for training. When testing, we employ a multi-source inference mechanism, where the final result for a test frame is either obtained via the segmentation branch or via propagation from a nearby key frame. We conduct extensive experiments for body parsing using SPN on two infant movement video datasets, where SPN coupled with FVGAN achieves state-of-the-art performance. We further demonstrate that SPN can be easily adapted to the infant pose estimation task with superior performance. Last but not least, we explore the clinical application of our method for GMA. We collected a new clinical IMV dataset with GMA annotations, and our experiments show that SPN models for body parsing and pose estimation trained on the first two datasets generalize well to the new clinical dataset and their results can significantly boost the CRNN-based GMA prediction performance.
Cross-identity Video Motion Retargeting with Joint Transformation and Synthesis
Oct 02, 2022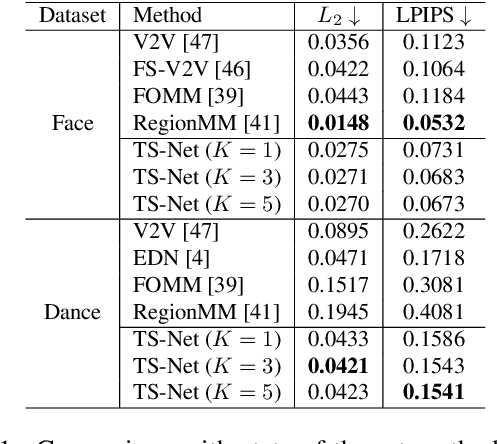
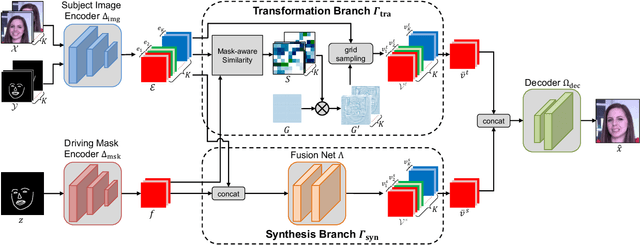
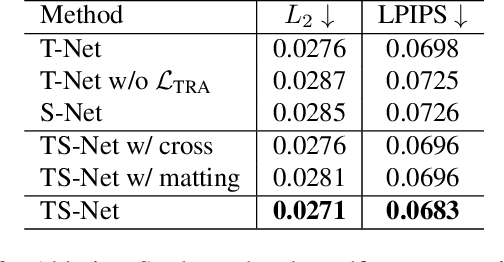
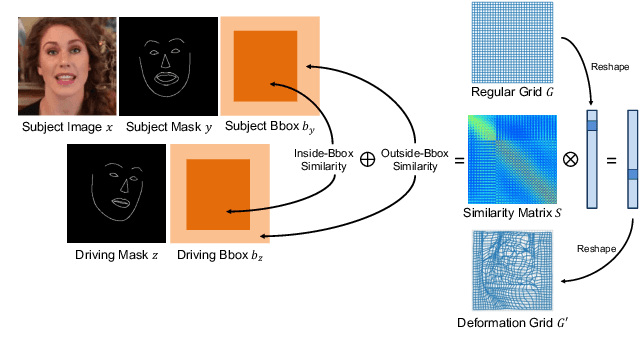
In this paper, we propose a novel dual-branch Transformation-Synthesis network (TS-Net), for video motion retargeting. Given one subject video and one driving video, TS-Net can produce a new plausible video with the subject appearance of the subject video and motion pattern of the driving video. TS-Net consists of a warp-based transformation branch and a warp-free synthesis branch. The novel design of dual branches combines the strengths of deformation-grid-based transformation and warp-free generation for better identity preservation and robustness to occlusion in the synthesized videos. A mask-aware similarity module is further introduced to the transformation branch to reduce computational overhead. Experimental results on face and dance datasets show that TS-Net achieves better performance in video motion retargeting than several state-of-the-art models as well as its single-branch variants. Our code is available at https://github.com/nihaomiao/WACV23_TSNet.
Asymmetry Disentanglement Network for Interpretable Acute Ischemic Stroke Infarct Segmentation in Non-Contrast CT Scans
Jun 30, 2022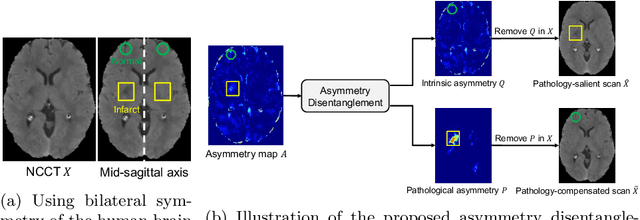
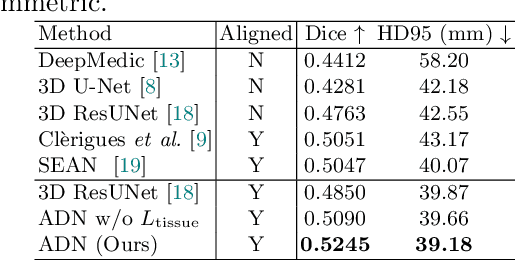
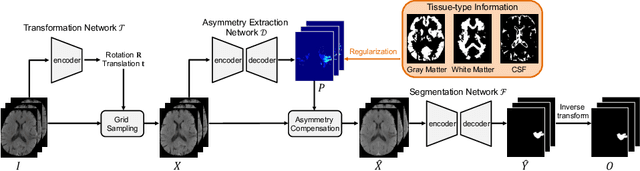
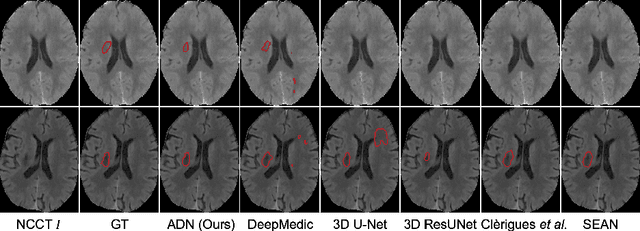
Accurate infarct segmentation in non-contrast CT (NCCT) images is a crucial step toward computer-aided acute ischemic stroke (AIS) assessment. In clinical practice, bilateral symmetric comparison of brain hemispheres is usually used to locate pathological abnormalities. Recent research has explored asymmetries to assist with AIS segmentation. However, most previous symmetry-based work mixed different types of asymmetries when evaluating their contribution to AIS. In this paper, we propose a novel Asymmetry Disentanglement Network (ADN) to automatically separate pathological asymmetries and intrinsic anatomical asymmetries in NCCTs for more effective and interpretable AIS segmentation. ADN first performs asymmetry disentanglement based on input NCCTs, which produces different types of 3D asymmetry maps. Then a synthetic, intrinsic-asymmetry-compensated and pathology-asymmetry-salient NCCT volume is generated and later used as input to a segmentation network. The training of ADN incorporates domain knowledge and adopts a tissue-type aware regularization loss function to encourage clinically-meaningful pathological asymmetry extraction. Coupled with an unsupervised 3D transformation network, ADN achieves state-of-the-art AIS segmentation performance on a public NCCT dataset. In addition to the superior performance, we believe the learned clinically-interpretable asymmetry maps can also provide insights towards a better understanding of AIS assessment. Our code is available at https://github.com/nihaomiao/MICCAI22_ADN.