 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMIRAM: Masked Image Reconstruction Across Multiple Scales for Breast Lesion Risk Prediction
Mar 10, 2025Self-supervised learning (SSL) has garnered substantial interest within the machine learning and computer vision communities. Two prominent approaches in SSL include contrastive-based learning and self-distillation utilizing cropping augmentation. Lately, masked image modeling (MIM) has emerged as a more potent SSL technique, employing image inpainting as a pretext task. MIM creates a strong inductive bias toward meaningful spatial and semantic understanding. This has opened up new opportunities for SSL to contribute not only to classification tasks but also to more complex applications like object detection and image segmentation. Building upon this progress, our research paper introduces a scalable and practical SSL approach centered around more challenging pretext tasks that facilitate the acquisition of robust features. Specifically, we leverage multi-scale image reconstruction from randomly masked input images as the foundation for feature learning. Our hypothesis posits that reconstructing high-resolution images enables the model to attend to finer spatial details, particularly beneficial for discerning subtle intricacies within medical images. The proposed SSL features help improve classification performance on the Curated Breast Imaging Subset of Digital Database for Screening Mammography (CBIS-DDSM) dataset. In pathology classification, our method demonstrates a 3\% increase in average precision (AP) and a 1\% increase in the area under the receiver operating characteristic curve (AUC) when compared to state-of-the-art (SOTA) algorithms. Moreover, in mass margins classification, our approach achieves a 4\% increase in AP and a 2\% increase in AUC.
Revisiting Invariant Learning for Out-of-Domain Generalization on Multi-Site Mammogram Datasets
Mar 09, 2025Despite significant progress in robust deep learning techniques for mammogram breast cancer classification, their reliability in real-world clinical development settings remains uncertain. The translation of these models to clinical practice faces challenges due to variations in medical centers, imaging protocols, and patient populations. To enhance their robustness, invariant learning methods have been proposed, prioritizing causal factors over misleading features. However, their effectiveness in clinical development and impact on mammogram classification require investigation. This paper reassesses the application of invariant learning for breast cancer risk estimation based on mammograms. Utilizing diverse multi-site public datasets, it represents the first study in this area. The objective is to evaluate invariant learning's benefits in developing robust models. Invariant learning methods, including Invariant Risk Minimization and Variance Risk Extrapolation, are compared quantitatively against Empirical Risk Minimization. Evaluation metrics include accuracy, average precision, and area under the curve. Additionally, interpretability is examined through class activation maps and visualization of learned representations. This research examines the advantages, limitations, and challenges of invariant learning for mammogram classification, guiding future studies to develop generalized methods for breast cancer prediction on whole mammograms in out-of-domain scenarios.
Asymmetry Disentanglement Network for Interpretable Acute Ischemic Stroke Infarct Segmentation in Non-Contrast CT Scans
Jun 30, 2022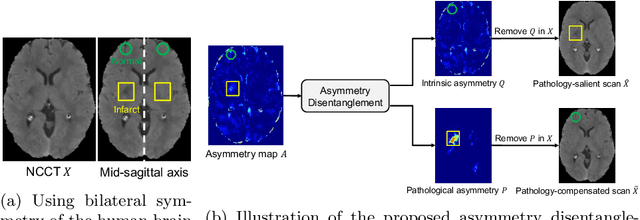
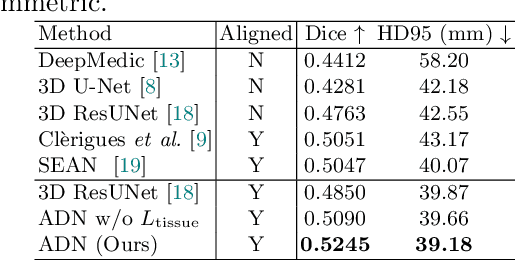
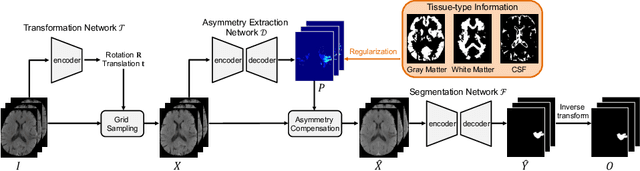
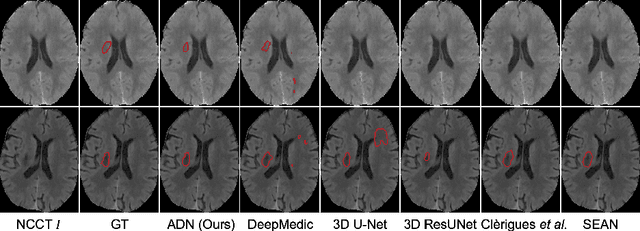
Accurate infarct segmentation in non-contrast CT (NCCT) images is a crucial step toward computer-aided acute ischemic stroke (AIS) assessment. In clinical practice, bilateral symmetric comparison of brain hemispheres is usually used to locate pathological abnormalities. Recent research has explored asymmetries to assist with AIS segmentation. However, most previous symmetry-based work mixed different types of asymmetries when evaluating their contribution to AIS. In this paper, we propose a novel Asymmetry Disentanglement Network (ADN) to automatically separate pathological asymmetries and intrinsic anatomical asymmetries in NCCTs for more effective and interpretable AIS segmentation. ADN first performs asymmetry disentanglement based on input NCCTs, which produces different types of 3D asymmetry maps. Then a synthetic, intrinsic-asymmetry-compensated and pathology-asymmetry-salient NCCT volume is generated and later used as input to a segmentation network. The training of ADN incorporates domain knowledge and adopts a tissue-type aware regularization loss function to encourage clinically-meaningful pathological asymmetry extraction. Coupled with an unsupervised 3D transformation network, ADN achieves state-of-the-art AIS segmentation performance on a public NCCT dataset. In addition to the superior performance, we believe the learned clinically-interpretable asymmetry maps can also provide insights towards a better understanding of AIS assessment. Our code is available at https://github.com/nihaomiao/MICCAI22_ADN.
Patcher: Patch Transformers with Mixture of Experts for Precise Medical Image Segmentation
Jun 03, 2022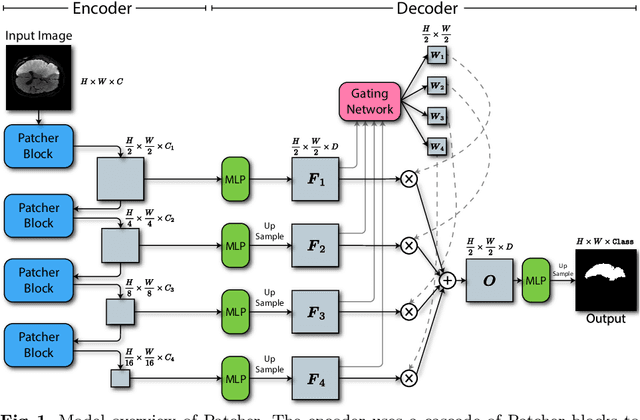
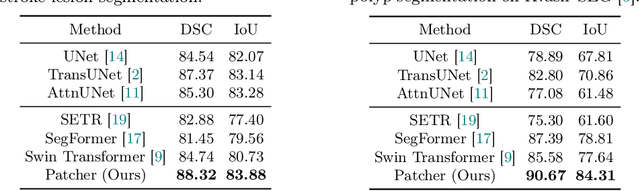


We present a new encoder-decoder Vision Transformer architecture, Patcher, for medical image segmentation. Unlike standard Vision Transformers, it employs Patcher blocks that segment an image into large patches, each of which is further divided into small patches. Transformers are applied to the small patches within a large patch, which constrains the receptive field of each pixel. We intentionally make the large patches overlap to enhance intra-patch communication. The encoder employs a cascade of Patcher blocks with increasing receptive fields to extract features from local to global levels. This design allows Patcher to benefit from both the coarse-to-fine feature extraction common in CNNs and the superior spatial relationship modeling of Transformers. We also propose a new mixture-of-experts (MoE) based decoder, which treats the feature maps from the encoder as experts and selects a suitable set of expert features to predict the label for each pixel. The use of MoE enables better specializations of the expert features and reduces interference between them during inference. Extensive experiments demonstrate that Patcher outperforms state-of-the-art Transformer- and CNN-based approaches significantly on stroke lesion segmentation and polyp segmentation. Code for Patcher will be released with publication to facilitate future research.
DeepStroke: An Efficient Stroke Screening Framework for Emergency Rooms with Multimodal Adversarial Deep Learning
Sep 24, 2021
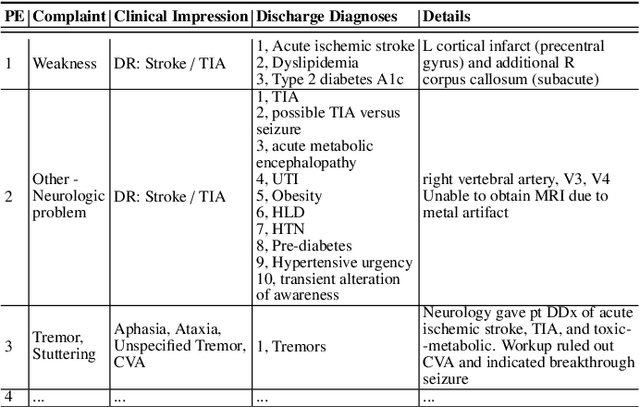
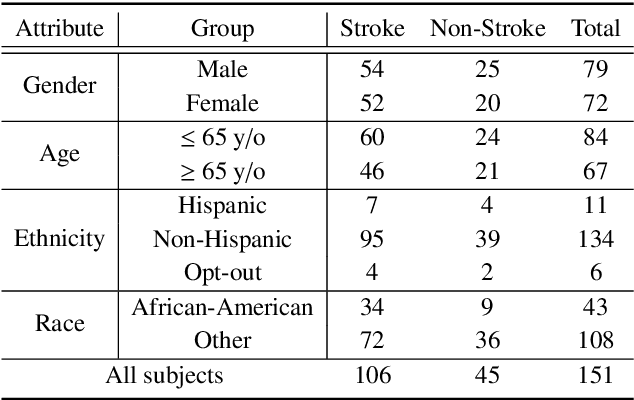
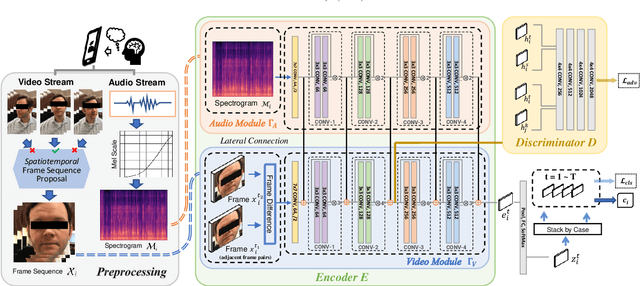
In an emergency room (ER) setting, the diagnosis of stroke is a common challenge. Due to excessive execution time and cost, an MRI scan is usually not available in the ER. Clinical tests are commonly referred to in stroke screening, but neurologists may not be immediately available. We propose a novel multimodal deep learning framework, DeepStroke, to achieve computer-aided stroke presence assessment by recognizing the patterns of facial motion incoordination and speech inability for patients with suspicion of stroke in an acute setting. Our proposed DeepStroke takes video data for local facial paralysis detection and audio data for global speech disorder analysis. It further leverages a multi-modal lateral fusion to combine the low- and high-level features and provides mutual regularization for joint training. A novel adversarial training loss is also introduced to obtain identity-independent and stroke-discriminative features. Experiments on our video-audio dataset with actual ER patients show that the proposed approach outperforms state-of-the-art models and achieves better performance than ER doctors, attaining a 6.60% higher sensitivity and maintaining 4.62% higher accuracy when specificity is aligned. Meanwhile, each assessment can be completed in less than 6 minutes, demonstrating the framework's great potential for clinical implementation.
Multimodal Breast Lesion Classification Using Cross-Attention Deep Networks
Aug 21, 2021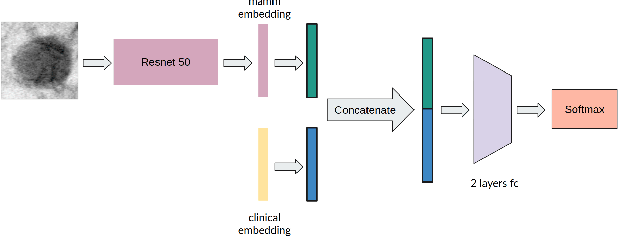
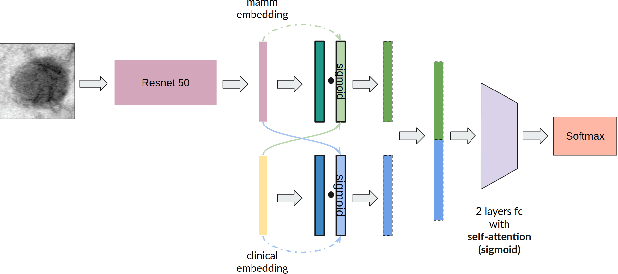
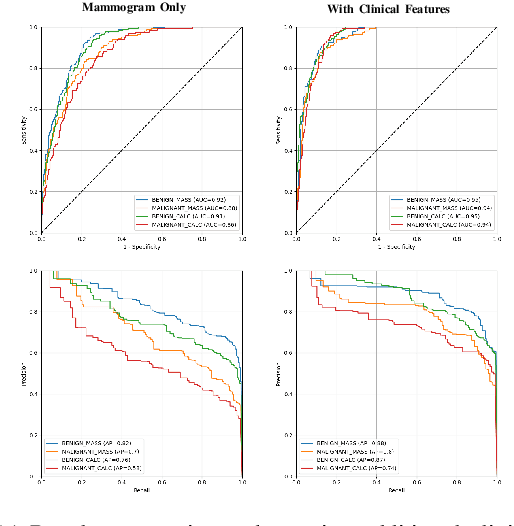

Accurate breast lesion risk estimation can significantly reduce unnecessary biopsies and help doctors decide optimal treatment plans. Most existing computer-aided systems rely solely on mammogram features to classify breast lesions. While this approach is convenient, it does not fully exploit useful information in clinical reports to achieve the optimal performance. Would clinical features significantly improve breast lesion classification compared to using mammograms alone? How to handle missing clinical information caused by variation in medical practice? What is the best way to combine mammograms and clinical features? There is a compelling need for a systematic study to address these fundamental questions. This paper investigates several multimodal deep networks based on feature concatenation, cross-attention, and co-attention to combine mammograms and categorical clinical variables. We show that the proposed architectures significantly increase the lesion classification performance (average area under ROC curves from 0.89 to 0.94). We also evaluate the model when clinical variables are missing.
LambdaUNet: 2.5D Stroke Lesion Segmentation of Diffusion-weighted MR Images
Apr 28, 2021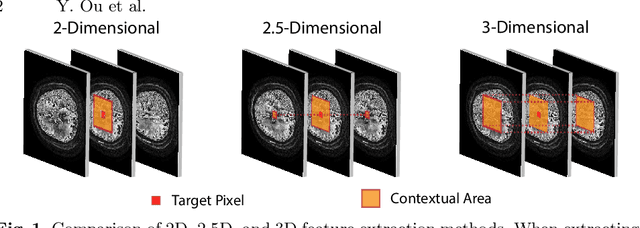
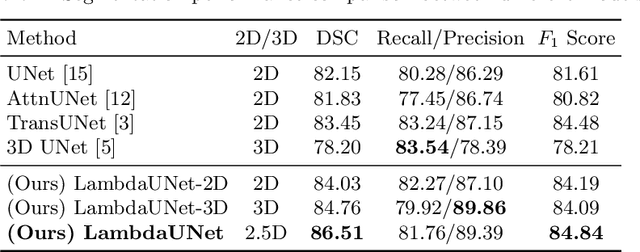


Diffusion-weighted (DW) magnetic resonance imaging is essential for the diagnosis and treatment of ischemic stroke. DW images (DWIs) are usually acquired in multi-slice settings where lesion areas in two consecutive 2D slices are highly discontinuous due to large slice thickness and sometimes even slice gaps. Therefore, although DWIs contain rich 3D information, they cannot be treated as regular 3D or 2D images. Instead, DWIs are somewhere in-between (or 2.5D) due to the volumetric nature but inter-slice discontinuities. Thus, it is not ideal to apply most existing segmentation methods as they are designed for either 2D or 3D images. To tackle this problem, we propose a new neural network architecture tailored for segmenting highly-discontinuous 2.5D data such as DWIs. Our network, termed LambdaUNet, extends UNet by replacing convolutional layers with our proposed Lambda+ layers. In particular, Lambda+ layers transform both intra-slice and inter-slice context around a pixel into linear functions, called lambdas, which are then applied to the pixel to produce informative 2.5D features. LambdaUNet is simple yet effective in combining sparse inter-slice information from adjacent slices while also capturing dense contextual features within a single slice. Experiments on a unique clinical dataset demonstrate that LambdaUNet outperforms existing 3D/2D image segmentation methods including recent variants of UNet. Code for LambdaUNet will be released with the publication to facilitate future research.