 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMIRAM: Masked Image Reconstruction Across Multiple Scales for Breast Lesion Risk Prediction
Mar 10, 2025
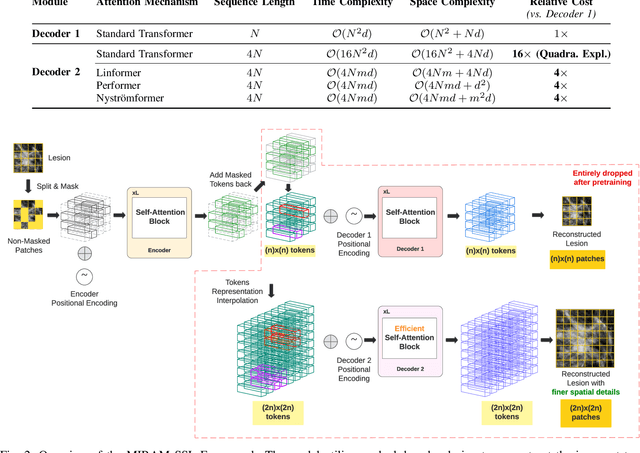
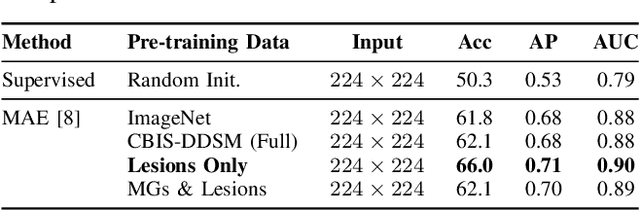
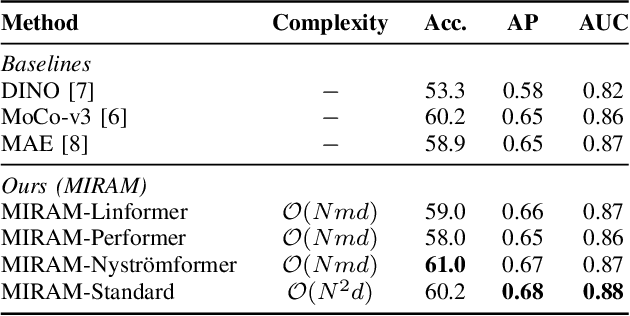
Self-supervised learning (SSL) has garnered substantial interest within the machine learning and computer vision communities. Two prominent approaches in SSL include contrastive-based learning and self-distillation utilizing cropping augmentation. Lately, masked image modeling (MIM) has emerged as a more potent SSL technique, employing image inpainting as a pretext task. MIM creates a strong inductive bias toward meaningful spatial and semantic understanding. This has opened up new opportunities for SSL to contribute not only to classification tasks but also to more complex applications like object detection and image segmentation. Building upon this progress, our research paper introduces a scalable and practical SSL approach centered around more challenging pretext tasks that facilitate the acquisition of robust features. Specifically, we leverage multi-scale image reconstruction from randomly masked input images as the foundation for feature learning. Our hypothesis posits that reconstructing high-resolution images enables the model to attend to finer spatial details, particularly beneficial for discerning subtle intricacies within medical images. The proposed SSL features help improve classification performance on the Curated Breast Imaging Subset of Digital Database for Screening Mammography (CBIS-DDSM) dataset. In pathology classification, our method demonstrates a 3\% increase in average precision (AP) and a 1\% increase in the area under the receiver operating characteristic curve (AUC) when compared to state-of-the-art (SOTA) algorithms. Moreover, in mass margins classification, our approach achieves a 4\% increase in AP and a 2\% increase in AUC.
Multimodal Breast Lesion Classification Using Cross-Attention Deep Networks
Aug 21, 2021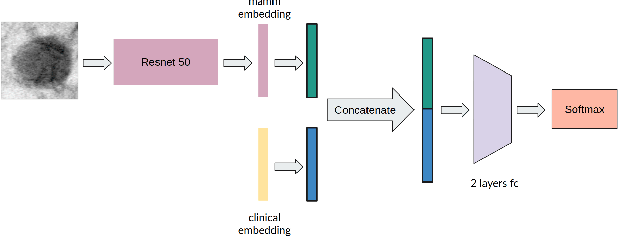
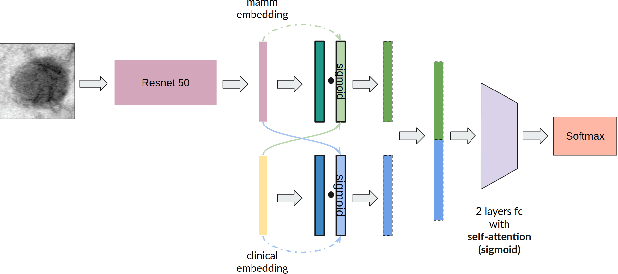
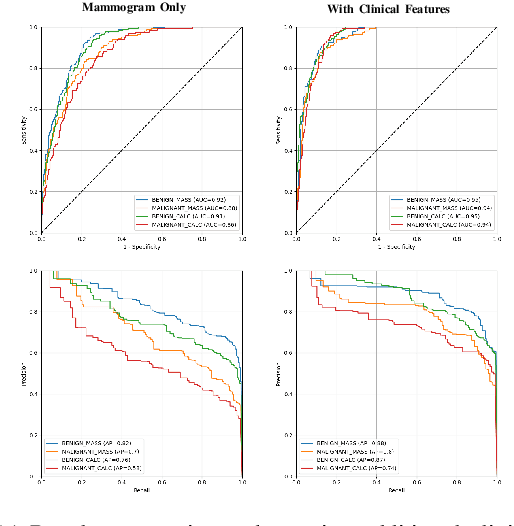

Accurate breast lesion risk estimation can significantly reduce unnecessary biopsies and help doctors decide optimal treatment plans. Most existing computer-aided systems rely solely on mammogram features to classify breast lesions. While this approach is convenient, it does not fully exploit useful information in clinical reports to achieve the optimal performance. Would clinical features significantly improve breast lesion classification compared to using mammograms alone? How to handle missing clinical information caused by variation in medical practice? What is the best way to combine mammograms and clinical features? There is a compelling need for a systematic study to address these fundamental questions. This paper investigates several multimodal deep networks based on feature concatenation, cross-attention, and co-attention to combine mammograms and categorical clinical variables. We show that the proposed architectures significantly increase the lesion classification performance (average area under ROC curves from 0.89 to 0.94). We also evaluate the model when clinical variables are missing.
First arrival picking using U-net with Lovasz loss and nearest point picking method
Apr 06, 2021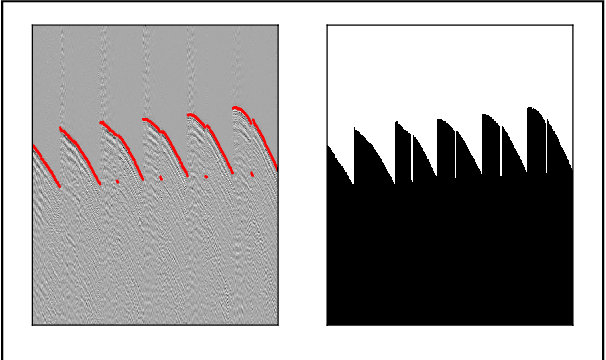
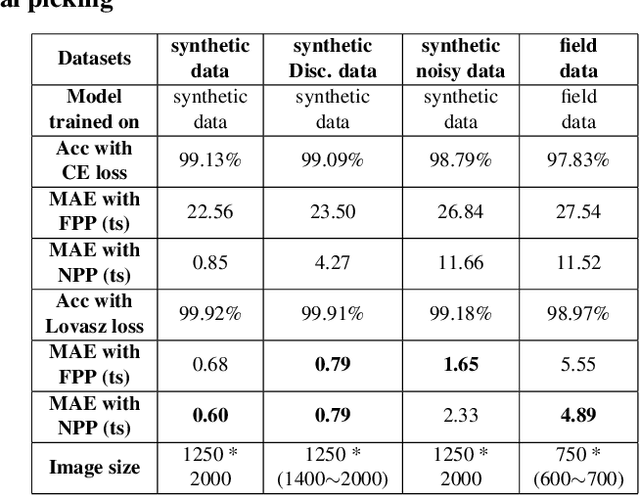
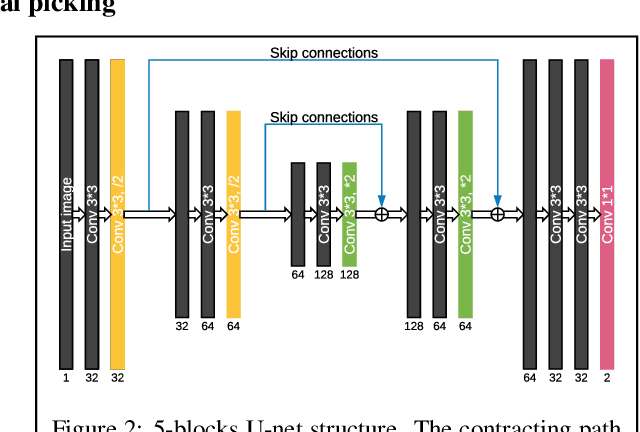
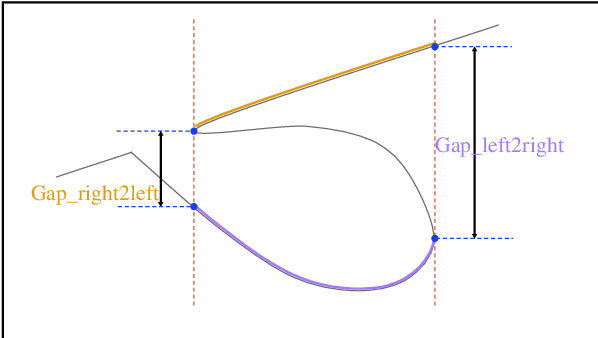
We proposed a robust segmentation and picking workflow to solve the first arrival picking problem for seismic signal processing. Unlike traditional classification algorithm, image segmentation method can utilize the location information by outputting a prediction map which has the same size of the input image. A parameter-free nearest point picking algorithm is proposed to further improve the accuracy of the first arrival picking. The algorithm is test on synthetic clean data, synthetic noisy data, synthetic picking-disconnected data and field data. It performs well on all of them and the picking deviation reaches as low as 4.8ms per receiver. The first arrival picking problem is formulated as the contour detection problem. Similar to \cite{wu2019semi}, we use U-net to perform the segmentation as it is proven to be state-of-the-art in many image segmentation tasks. Particularly, a Lovasz loss instead of the traditional cross-entropy loss is used to train the network for a better segmentation performance. Lovasz loss is a surrogate loss for Jaccard index or the so-called intersection-over-union (IoU) score, which is often one of the most used metrics for segmentation tasks. In the picking part, we use a novel nearest point picking (NPP) method to take the advantage of the coherence of the first arrival picking among adjacent receivers. Our model is tested and validated on both synthetic and field data with harmonic noises. The main contributions of this paper are as follows: 1. Used Lovasz loss to directly optimize the IoU for segmentation task. Improvement over the cross-entropy loss with regard to the segmentation accuracy is verified by the test result. 2. Proposed a nearest point picking post processing method to overcome any defects left by the segmentation output. 3. Conducted noise analysis and verified the model with both noisy synthetic and field datasets.
Few Is Enough: Task-Augmented Active Meta-Learning for Brain Cell Classification
Jul 09, 2020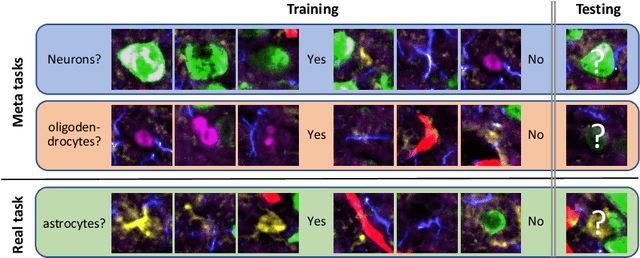
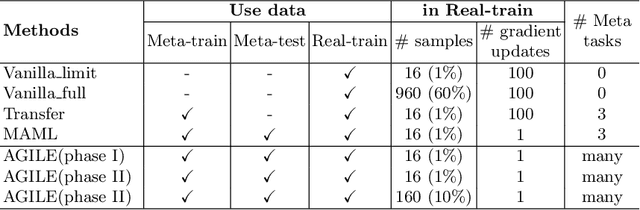
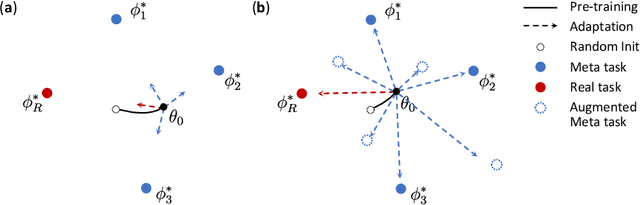
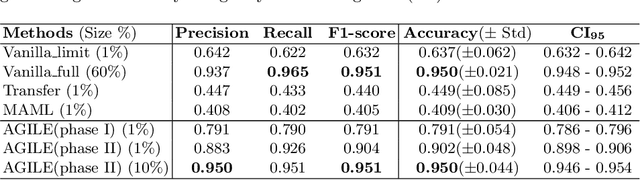
Deep Neural Networks (or DNNs) must constantly cope with distribution changes in the input data when the task of interest or the data collection protocol changes. Retraining a network from scratch to combat this issue poses a significant cost. Meta-learning aims to deliver an adaptive model that is sensitive to these underlying distribution changes, but requires many tasks during the meta-training process. In this paper, we propose a tAsk-auGmented actIve meta-LEarning (AGILE) method to efficiently adapt DNNs to new tasks by using a small number of training examples. AGILE combines a meta-learning algorithm with a novel task augmentation technique which we use to generate an initial adaptive model. It then uses Bayesian dropout uncertainty estimates to actively select the most difficult samples when updating the model to a new task. This allows AGILE to learn with fewer tasks and a few informative samples, achieving high performance with a limited dataset. We perform our experiments using the brain cell classification task and compare the results to a plain meta-learning model trained from scratch. We show that the proposed task-augmented meta-learning framework can learn to classify new cell types after a single gradient step with a limited number of training samples. We show that active learning with Bayesian uncertainty can further improve the performance when the number of training samples is extremely small. Using only 1% of the training data and a single update step, we achieved 90% accuracy on the new cell type classification task, a 50% points improvement over a state-of-the-art meta-learning algorithm.
StyPath: Style-Transfer Data Augmentation For Robust Histology Image Classification
Jul 09, 2020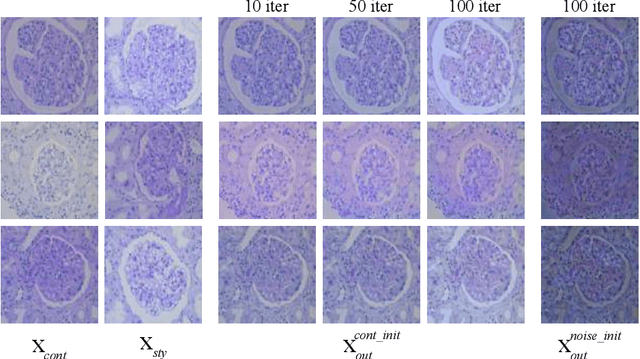
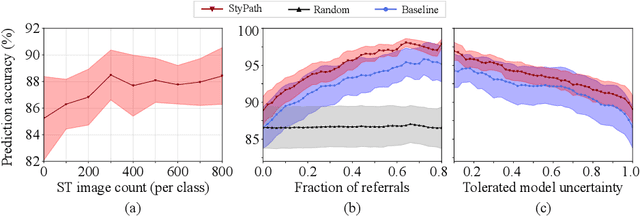
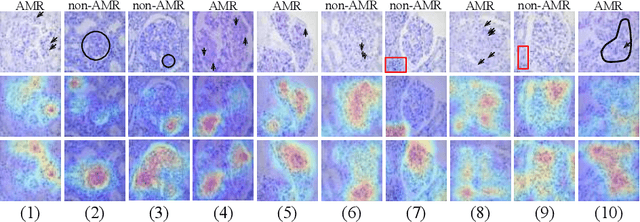
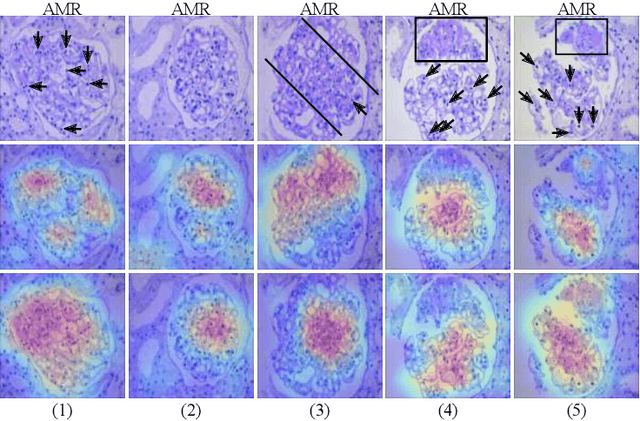
The classification of Antibody Mediated Rejection (AMR) in kidney transplant remains challenging even for experienced nephropathologists; this is partly because histological tissue stain analysis is often characterized by low inter-observer agreement and poor reproducibility. One of the implicated causes for inter-observer disagreement is the variability of tissue stain quality between (and within) pathology labs, coupled with the gradual fading of archival sections. Variations in stain colors and intensities can make tissue evaluation difficult for pathologists, ultimately affecting their ability to describe relevant morphological features. Being able to accurately predict the AMR status based on kidney histology images is crucial for improving patient treatment and care. We propose a novel pipeline to build robust deep neural networks for AMR classification based on StyPath, a histological data augmentation technique that leverages a light weight style-transfer algorithm as a means to reduce sample-specific bias. Each image was generated in 1.84 +- 0.03 seconds using a single GTX TITAN V gpu and pytorch, making it faster than other popular histological data augmentation techniques. We evaluated our model using a Monte Carlo (MC) estimate of Bayesian performance and generate an epistemic measure of uncertainty to compare both the baseline and StyPath augmented models. We also generated Grad-CAM representations of the results which were assessed by an experienced nephropathologist; we used this qualitative analysis to elucidate on the assumptions being made by each model. Our results imply that our style-transfer augmentation technique improves histological classification performance (reducing error from 14.8% to 11.5%) and generalization ability.
DECAPS: Detail-Oriented Capsule Networks
Jul 09, 2020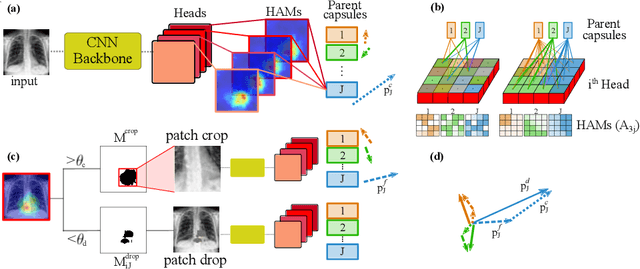

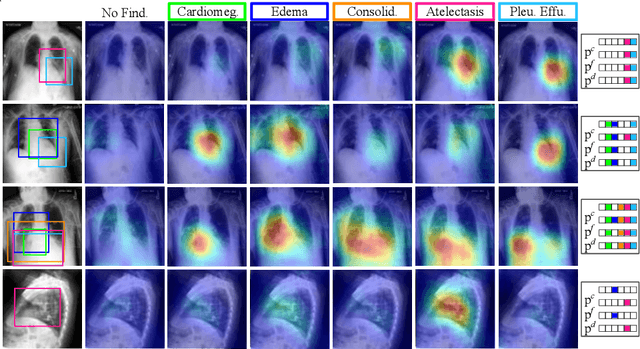

Capsule Networks (CapsNets) have demonstrated to be a promising alternative to Convolutional Neural Networks (CNNs). However, they often fall short of state-of-the-art accuracies on large-scale high-dimensional datasets. We propose a Detail-Oriented Capsule Network (DECAPS) that combines the strength of CapsNets with several novel techniques to boost its classification accuracies. First, DECAPS uses an Inverted Dynamic Routing (IDR) mechanism to group lower-level capsules into heads before sending them to higher-level capsules. This strategy enables capsules to selectively attend to small but informative details within the data which may be lost during pooling operations in CNNs. Second, DECAPS employs a Peekaboo training procedure, which encourages the network to focus on fine-grained information through a second-level attention scheme. Finally, the distillation process improves the robustness of DECAPS by averaging over the original and attended image region predictions. We provide extensive experiments on the CheXpert and RSNA Pneumonia datasets to validate the effectiveness of DECAPS. Our networks achieve state-of-the-art accuracies not only in classification (increasing the average area under ROC curves from 87.24% to 92.82% on the CheXpert dataset) but also in the weakly-supervised localization of diseased areas (increasing average precision from 41.7% to 80% for the RSNA Pneumonia detection dataset).
Radiologist-Level COVID-19 Detection Using CT Scans with Detail-Oriented Capsule Networks
Apr 16, 2020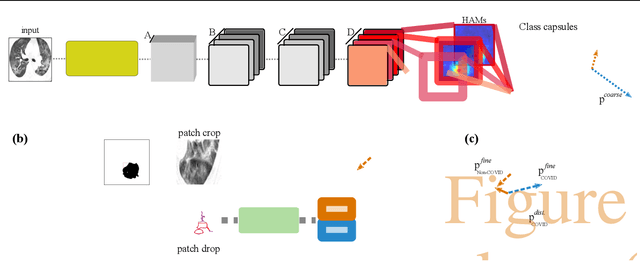

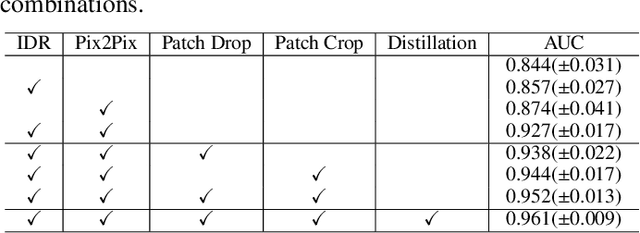
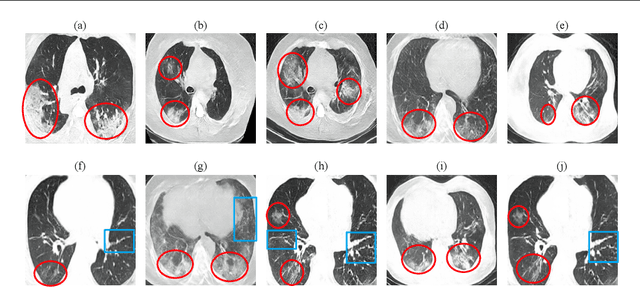
Radiographic images offer an alternative method for the rapid screening and monitoring of Coronavirus Disease 2019 (COVID-19) patients. This approach is limited by the shortage of radiology experts who can provide a timely interpretation of these images. Motivated by this challenge, our paper proposes a novel learning architecture, called Detail-Oriented Capsule Networks (DECAPS), for the automatic diagnosis of COVID-19 from Computed Tomography (CT) scans. Our network combines the strength of Capsule Networks with several architecture improvements meant to boost classification accuracies. First, DECAPS uses an Inverted Dynamic Routing mechanism which increases model stability by preventing the passage of information from non-descriptive regions. Second, DECAPS employs a Peekaboo training procedure which uses a two-stage patch crop and drop strategy to encourage the network to generate activation maps for every target concept. The network then uses the activation maps to focus on regions of interest and combines both coarse and fine-grained representations of the data. Finally, we use a data augmentation method based on conditional generative adversarial networks to deal with the issue of data scarcity. Our model achieves 84.3% precision, 91.5% recall, and 96.1% area under the ROC curve, significantly outperforming state-of-the-art methods. We compare the performance of the DECAPS model with three experienced, well-trained thoracic radiologists and show that the architecture significantly outperforms them. While further studies on larger datasets are required to confirm this finding, our results imply that architectures like DECAPS can be used to assist radiologists in the CT scan mediated diagnosis of COVID-19.