 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRevisiting Invariant Learning for Out-of-Domain Generalization on Multi-Site Mammogram Datasets
Mar 09, 2025



Despite significant progress in robust deep learning techniques for mammogram breast cancer classification, their reliability in real-world clinical development settings remains uncertain. The translation of these models to clinical practice faces challenges due to variations in medical centers, imaging protocols, and patient populations. To enhance their robustness, invariant learning methods have been proposed, prioritizing causal factors over misleading features. However, their effectiveness in clinical development and impact on mammogram classification require investigation. This paper reassesses the application of invariant learning for breast cancer risk estimation based on mammograms. Utilizing diverse multi-site public datasets, it represents the first study in this area. The objective is to evaluate invariant learning's benefits in developing robust models. Invariant learning methods, including Invariant Risk Minimization and Variance Risk Extrapolation, are compared quantitatively against Empirical Risk Minimization. Evaluation metrics include accuracy, average precision, and area under the curve. Additionally, interpretability is examined through class activation maps and visualization of learned representations. This research examines the advantages, limitations, and challenges of invariant learning for mammogram classification, guiding future studies to develop generalized methods for breast cancer prediction on whole mammograms in out-of-domain scenarios.
Modular Self-Lock Origami: design, modeling, and simulation to improve the performance of a rotational joint
Jul 31, 2023


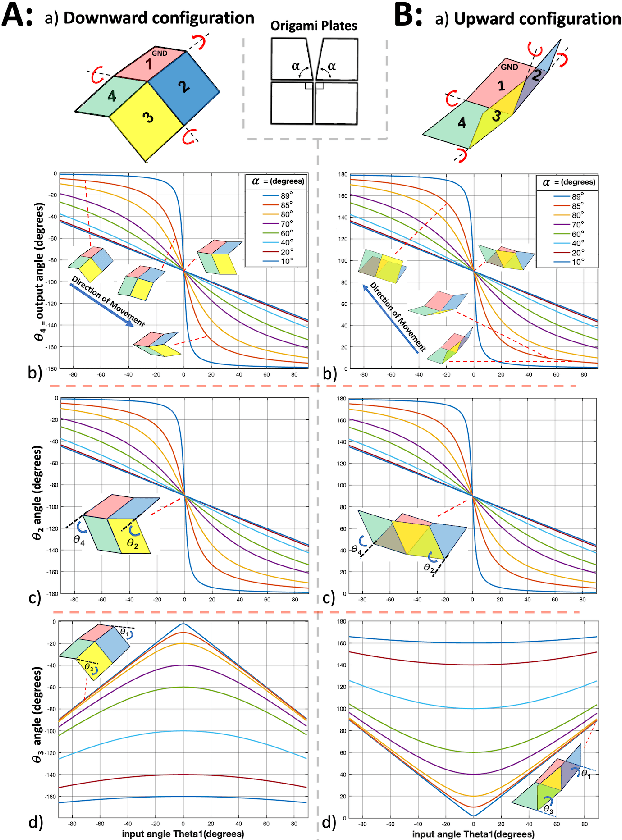
Origami structures have been widely explored in robotics due to their many potential advantages. Origami robots can be very compact, as well as cheap and efficient to produce. In particular, they can be constructed in a flat format using modern manufacturing techniques. Rotational motion is essential for robotics, and a variety of origami rotational joints have been proposed in the literature. However, few of these are even approximately flat-foldable. One potential enabler of flat origami rotational joints is the inclusion of lightweight pneumatic pouches which actuate the origami's folds; however, pouch actuators only enable a relatively small amount of rotational displacement. The previously proposed Four-Vertex Origami is a flat-foldable structure which provides an angular multiplier for a pouch actuator, but suffers from a degenerate state. This paper presents a novel rigid origami, the Self-Lock Origami, which eliminates this degeneracy by slightly relaxing the assumption of flat-foldability. This joint is analysed in terms of a trade-off between the angular multiplier and the mechanical advantage. Furthermore, the Self-Lock Origami is a modular joint which can be connected to similar or different joints to produce complex movements for various applications; three different manipulator designs are introduced as a proof of concept.
Anomaly Detection in Satellite Videos using Diffusion Models
May 25, 2023


The definition of anomaly detection is the identification of an unexpected event. Real-time detection of extreme events such as wildfires, cyclones, or floods using satellite data has become crucial for disaster management. Although several earth-observing satellites provide information about disasters, satellites in the geostationary orbit provide data at intervals as frequent as every minute, effectively creating a video from space. There are many techniques that have been proposed to identify anomalies in surveillance videos; however, the available datasets do not have dynamic behavior, so we discuss an anomaly framework that can work on very high-frequency datasets to find very fast-moving anomalies. In this work, we present a diffusion model which does not need any motion component to capture the fast-moving anomalies and outperforms the other baseline methods.
PICASO: Permutation-Invariant Cascaded Attentional Set Operator
Jul 17, 2021
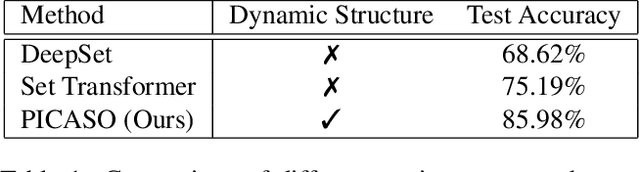


Set-input deep networks have recently drawn much interest in computer vision and machine learning. This is in part due to the increasing number of important tasks such as meta-learning, clustering, and anomaly detection that are defined on set inputs. These networks must take an arbitrary number of input samples and produce the output invariant to the input set permutation. Several algorithms have been recently developed to address this urgent need. Our paper analyzes these algorithms using both synthetic and real-world datasets, and shows that they are not effective in dealing with common data variations such as image translation or viewpoint change. To address this limitation, we propose a permutation-invariant cascaded attentional set operator (PICASO). The gist of PICASO is a cascade of multihead attention blocks with dynamic templates. The proposed operator is a stand-alone module that can be adapted and extended to serve different machine learning tasks. We demonstrate the utilities of PICASO in four diverse scenarios: (i) clustering, (ii) image classification under novel viewpoints, (iii) image anomaly detection, and (iv) state prediction. PICASO increases the SmallNORB image classification accuracy with novel viewpoints by about 10% points. For set anomaly detection on CelebA dataset, our model improves the areas under ROC and PR curves dataset by about 22% and 10%, respectively. For the state prediction on CLEVR dataset, it improves the AP by about 40%.
Quarantine Deceiving Yelp's Users by Detecting Unreliable Rating Reviews
Apr 21, 2020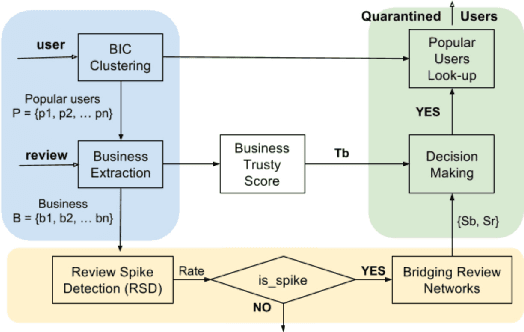
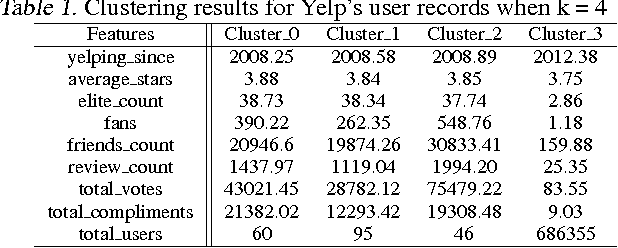
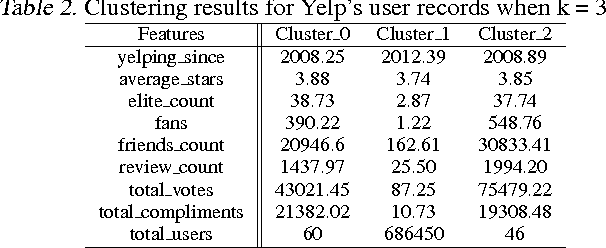
Online reviews have become a valuable and significant resource, for not only consumers but companies, in decision making. In the absence of a trusted system, highly popular and trustworthy internet users will be assumed as members of the trusted circle. In this paper, we describe our focus on quarantining deceiving Yelp's users that employ both review spike detection (RSD) algorithm and spam detection technique in bridging review networks (BRN), on extracted key features. We found that more than 80% of Yelp's accounts are unreliable, and more than 80% of highly-rated businesses are subject to spamming.
Radiologist-Level COVID-19 Detection Using CT Scans with Detail-Oriented Capsule Networks
Apr 16, 2020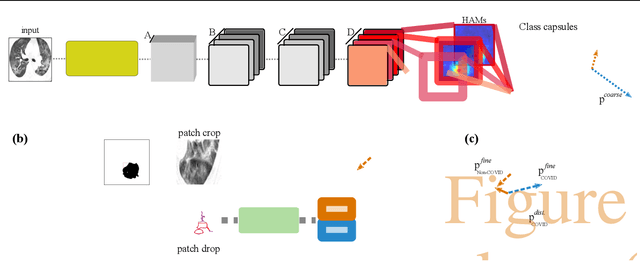

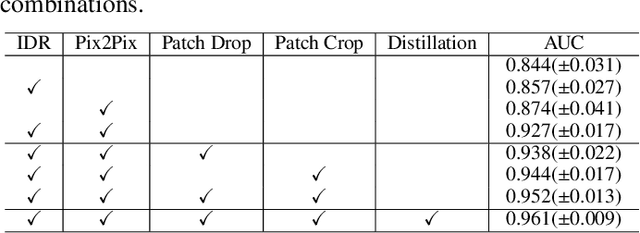
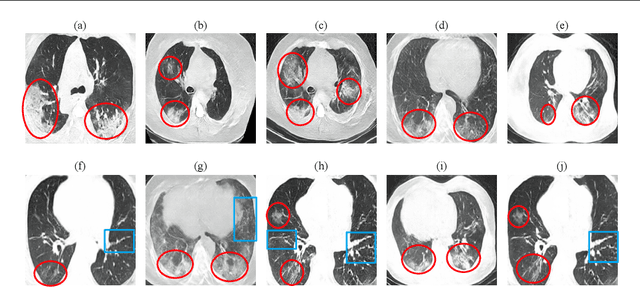
Radiographic images offer an alternative method for the rapid screening and monitoring of Coronavirus Disease 2019 (COVID-19) patients. This approach is limited by the shortage of radiology experts who can provide a timely interpretation of these images. Motivated by this challenge, our paper proposes a novel learning architecture, called Detail-Oriented Capsule Networks (DECAPS), for the automatic diagnosis of COVID-19 from Computed Tomography (CT) scans. Our network combines the strength of Capsule Networks with several architecture improvements meant to boost classification accuracies. First, DECAPS uses an Inverted Dynamic Routing mechanism which increases model stability by preventing the passage of information from non-descriptive regions. Second, DECAPS employs a Peekaboo training procedure which uses a two-stage patch crop and drop strategy to encourage the network to generate activation maps for every target concept. The network then uses the activation maps to focus on regions of interest and combines both coarse and fine-grained representations of the data. Finally, we use a data augmentation method based on conditional generative adversarial networks to deal with the issue of data scarcity. Our model achieves 84.3% precision, 91.5% recall, and 96.1% area under the ROC curve, significantly outperforming state-of-the-art methods. We compare the performance of the DECAPS model with three experienced, well-trained thoracic radiologists and show that the architecture significantly outperforms them. While further studies on larger datasets are required to confirm this finding, our results imply that architectures like DECAPS can be used to assist radiologists in the CT scan mediated diagnosis of COVID-19.