 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBCI-Based Assessment of Ocular Response Time Using Dynamic Time Warping Leveraging an RDWT-Driven Deep Neural Framework
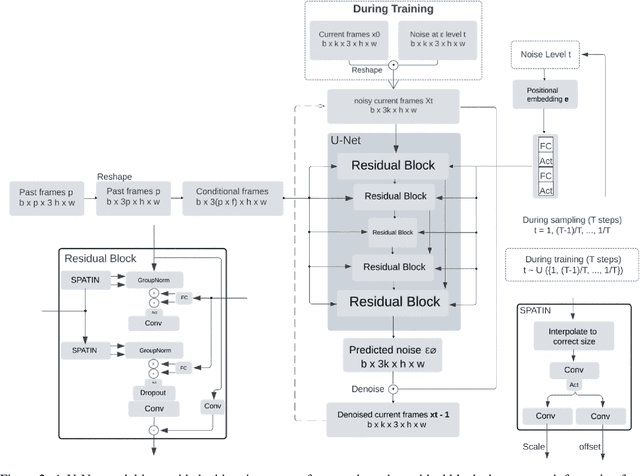
May 14, 2026Mild traumatic brain injury (mTBI) is a prevalent condition that remains difficult to diagnose in its early stages. Oculomotor dysfunction is a well-established marker of mTBI, motivating the development of portable tools that capture both eye-movement behavior and underlying neurophysiology. In this work, we present an initial framework that integrates electroencephalogram (EEG) with augmented-reality (AR)-based Vestibular/Ocular Motor Screening (VOMS) tasks to estimate subject-specific ocular response times. Pre-processed EEG signals, obtained through band-pass filtering and average referencing, are analyzed using a Redundant Discrete Wavelet Transform (RDWT)-driven deep neural framework. The RDWT coefficients are subjected to trainable zero-phase convolutional filtering and reconstructed into the time domain via inverse RDWT, followed by channel-wise temporal and spatial filtering using 2D convolution layers and convolutional-LSTM-based decoding. An ablation study demonstrates that wavelet-domain filtering serves as an effective denoising strategy, improving prediction performance. Sliding-window predictions were validated using Pearson correlation (>= 0.5), and Dynamic Time Warping (DTW) was subsequently used to estimate ocular response times. DTW-derived metrics revealed significant inter-subject differences across all VOM tasks, supported by Mann-Whitney U tests. Cross-correlation analysis further revealed task-dependent temporal behaviors: pursuit tasks exhibited reactive tracking, whereas saccades showed anticipatory responses. Overall, the results highlight pursuit tasks as particularly informative for distinguishing timing differences and demonstrate the potential of RDWT-based EEG features combined with DTW metrics for multimodal mTBI assessment.
DINO Soars: DINOv3 for Open-Vocabulary Semantic Segmentation of Remote Sensing Imagery
May 04, 2026The remote sensing (RS) domain suffers from a lack of densely labeled datasets, which are costly to obtain. Thus, models that can segment RS imagery well without supervised fine-tuning are valuable, but existing solutions fall behind supervised methods. Recently, DINOv3 surpassed SOTA RS foundation models on the GEO-bench segmentation benchmark without pre-training on RS data. Additionally, DINO.txt has enabled open vocabulary semantic segmentation (OVSS) with the DINOv3 backbone. We leverage these developments to form an OVSS model for RS imagery, free of RS-domain fine-tuning. Our model, CAFe-DINO (Cost Aggregation + Feature Upsampling with DINO) exploits the strong OVSS performance of DINOv3 for RS imagery via cost aggregation and training-free upsampling of text-image similarity scores. The robust latent of the DINOv3 backbone eliminates the need for fine-tuning on RS imagery; we instead fine-tune our model on a RS-targeted subset of COCO-Stuff. CAFe-DINO achieves state-of-the-art performance on key RS segmentation datasets, outperforming OVSS methods fine-tuned on RS data. Our code and data are publicly available at https://github.com/rfaulk/DINO_Soars.
Weak-to-Strong Generalization Enables Fully Automated De Novo Training of Multi-head Mask-RCNN Model for Segmenting Densely Overlapping Cell Nuclei in Multiplex Whole-slice Brain Images
Dec 12, 2025We present a weak to strong generalization methodology for fully automated training of a multi-head extension of the Mask-RCNN method with efficient channel attention for reliable segmentation of overlapping cell nuclei in multiplex cyclic immunofluorescent (IF) whole-slide images (WSI), and present evidence for pseudo-label correction and coverage expansion, the key phenomena underlying weak to strong generalization. This method can learn to segment de novo a new class of images from a new instrument and/or a new imaging protocol without the need for human annotations. We also present metrics for automated self-diagnosis of segmentation quality in production environments, where human visual proofreading of massive WSI images is unaffordable. Our method was benchmarked against five current widely used methods and showed a significant improvement. The code, sample WSI images, and high-resolution segmentation results are provided in open form for community adoption and adaptation.
mViSE: A Visual Search Engine for Analyzing Multiplex IHC Brain Tissue Images
Dec 12, 2025Whole-slide multiplex imaging of brain tissue generates massive information-dense images that are challenging to analyze and require custom software. We present an alternative query-driven programming-free strategy using a multiplex visual search engine (mViSE) that learns the multifaceted brain tissue chemoarchitecture, cytoarchitecture, and myeloarchitecture. Our divide-and-conquer strategy organizes the data into panels of related molecular markers and uses self-supervised learning to train a multiplex encoder for each panel with explicit visual confirmation of successful learning. Multiple panels can be combined to process visual queries for retrieving similar communities of individual cells or multicellular niches using information-theoretic methods. The retrievals can be used for diverse purposes including tissue exploration, delineating brain regions and cortical cell layers, profiling and comparing brain regions without computer programming. We validated mViSE's ability to retrieve single cells, proximal cell pairs, tissue patches, delineate cortical layers, brain regions and sub-regions. mViSE is provided as an open-source QuPath plug-in.
A Sensor Agnostic Domain Generalization Framework for Leveraging Geospatial Foundation Models: Enhancing Semantic Segmentation viaSynergistic Pseudo-Labeling and Generative Learning
May 02, 2025Remote sensing enables a wide range of critical applications such as land cover and land use mapping, crop yield prediction, and environmental monitoring. Advances in satellite technology have expanded remote sensing datasets, yet high-performance segmentation models remain dependent on extensive labeled data, challenged by annotation scarcity and variability across sensors, illumination, and geography. Domain adaptation offers a promising solution to improve model generalization. This paper introduces a domain generalization approach to leveraging emerging geospatial foundation models by combining soft-alignment pseudo-labeling with source-to-target generative pre-training. We further provide new mathematical insights into MAE-based generative learning for domain-invariant feature learning. Experiments with hyperspectral and multispectral remote sensing datasets confirm our method's effectiveness in enhancing adaptability and segmentation.
Foundation Models and Adaptive Feature Selection: A Synergistic Approach to Video Question Answering
Dec 12, 2024
This paper tackles the intricate challenge of video question-answering (VideoQA). Despite notable progress, current methods fall short of effectively integrating questions with video frames and semantic object-level abstractions to create question-aware video representations. We introduce Local-Global Question Aware Video Embedding (LGQAVE), which incorporates three major innovations to integrate multi-modal knowledge better and emphasize semantic visual concepts relevant to specific questions. LGQAVE moves beyond traditional ad-hoc frame sampling by utilizing a cross-attention mechanism that precisely identifies the most relevant frames concerning the questions. It captures the dynamics of objects within these frames using distinct graphs, grounding them in question semantics with the miniGPT model. These graphs are processed by a question-aware dynamic graph transformer (Q-DGT), which refines the outputs to develop nuanced global and local video representations. An additional cross-attention module integrates these local and global embeddings to generate the final video embeddings, which a language model uses to generate answers. Extensive evaluations across multiple benchmarks demonstrate that LGQAVE significantly outperforms existing models in delivering accurate multi-choice and open-ended answers.
Investigation of Hierarchical Spectral Vision Transformer Architecture for Classification of Hyperspectral Imagery
Sep 14, 2024In the past three years, there has been significant interest in hyperspectral imagery (HSI) classification using vision Transformers for analysis of remotely sensed data. Previous research predominantly focused on the empirical integration of convolutional neural networks (CNNs) to augment the network's capability to extract local feature information. Yet, the theoretical justification for vision Transformers out-performing CNN architectures in HSI classification remains a question. To address this issue, a unified hierarchical spectral vision Transformer architecture, specifically tailored for HSI classification, is investigated. In this streamlined yet effective vision Transformer architecture, multiple mixer modules are strategically integrated separately. These include the CNN-mixer, which executes convolution operations; the spatial self-attention (SSA)-mixer and channel self-attention (CSA)-mixer, both of which are adaptations of classical self-attention blocks; and hybrid models such as the SSA+CNN-mixer and CSA+CNN-mixer, which merge convolution with self-attention operations. This integration facilitates the development of a broad spectrum of vision Transformer-based models tailored for HSI classification. In terms of the training process, a comprehensive analysis is performed, contrasting classical CNN models and vision Transformer-based counterparts, with particular attention to disturbance robustness and the distribution of the largest eigenvalue of the Hessian. From the evaluations conducted on various mixer models rooted in the unified architecture, it is concluded that the unique strength of vision Transformers can be attributed to their overarching architecture, rather than being exclusively reliant on individual multi-head self-attention (MSA) components.
Anomaly Detection in Satellite Videos using Diffusion Models
May 25, 2023


The definition of anomaly detection is the identification of an unexpected event. Real-time detection of extreme events such as wildfires, cyclones, or floods using satellite data has become crucial for disaster management. Although several earth-observing satellites provide information about disasters, satellites in the geostationary orbit provide data at intervals as frequent as every minute, effectively creating a video from space. There are many techniques that have been proposed to identify anomalies in surveillance videos; however, the available datasets do not have dynamic behavior, so we discuss an anomaly framework that can work on very high-frequency datasets to find very fast-moving anomalies. In this work, we present a diffusion model which does not need any motion component to capture the fast-moving anomalies and outperforms the other baseline methods.
Attacks as Defenses: Designing Robust Audio CAPTCHAs Using Attacks on Automatic Speech Recognition Systems
Mar 10, 2022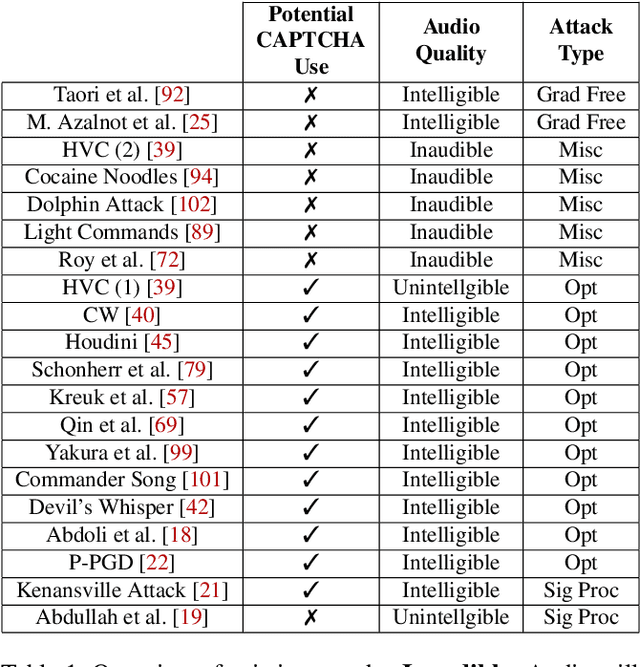
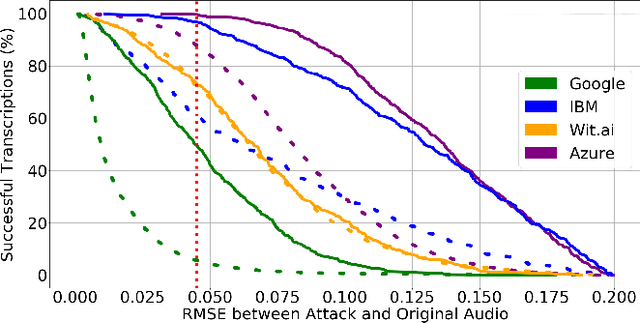

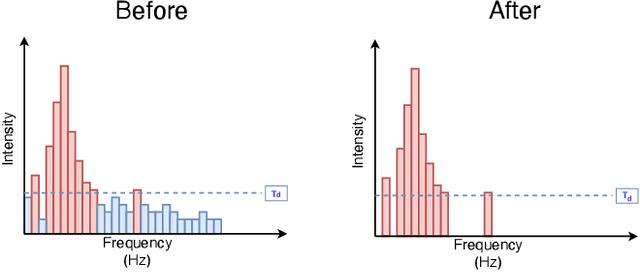
Audio CAPTCHAs are supposed to provide a strong defense for online resources; however, advances in speech-to-text mechanisms have rendered these defenses ineffective. Audio CAPTCHAs cannot simply be abandoned, as they are specifically named by the W3C as important enablers of accessibility. Accordingly, demonstrably more robust audio CAPTCHAs are important to the future of a secure and accessible Web. We look to recent literature on attacks on speech-to-text systems for inspiration for the construction of robust, principle-driven audio defenses. We begin by comparing 20 recent attack papers, classifying and measuring their suitability to serve as the basis of new "robust to transcription" but "easy for humans to understand" CAPTCHAs. After showing that none of these attacks alone are sufficient, we propose a new mechanism that is both comparatively intelligible (evaluated through a user study) and hard to automatically transcribe (i.e., $P({\rm transcription}) = 4 \times 10^{-5}$). Finally, we demonstrate that our audio samples have a high probability of being detected as CAPTCHAs when given to speech-to-text systems ($P({\rm evasion}) = 1.77 \times 10^{-4}$). In so doing, we not only demonstrate a CAPTCHA that is approximately four orders of magnitude more difficult to crack, but that such systems can be designed based on the insights gained from attack papers using the differences between the ways that humans and computers process audio.
Advances in Deep Learning for Hyperspectral Image Analysis--Addressing Challenges Arising in Practical Imaging Scenarios
Jul 16, 2020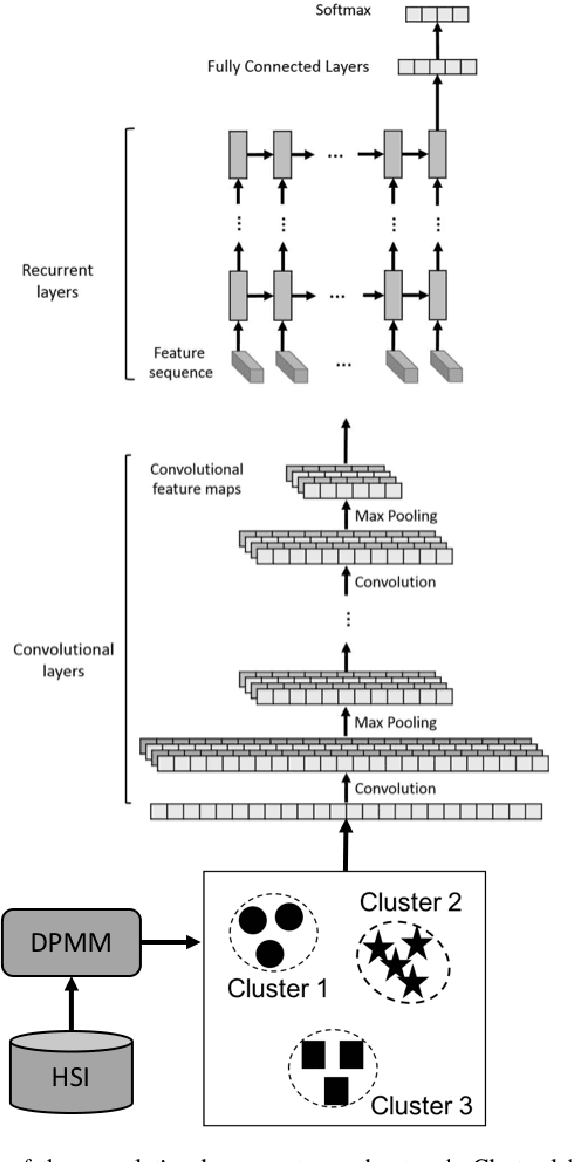

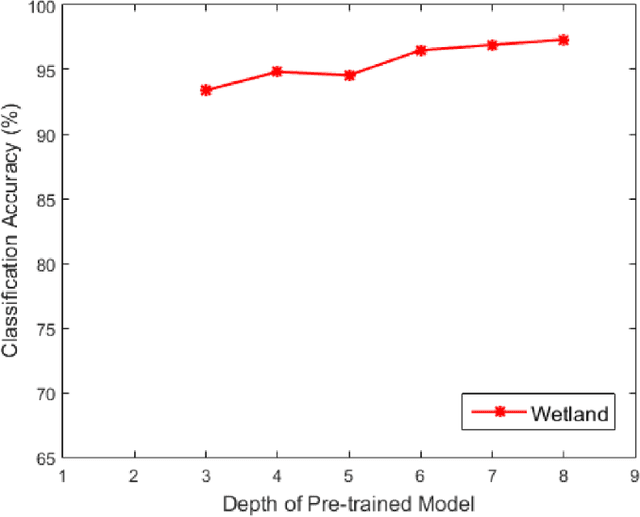

Deep neural networks have proven to be very effective for computer vision tasks, such as image classification, object detection, and semantic segmentation -- these are primarily applied to color imagery and video. In recent years, there has been an emergence of deep learning algorithms being applied to hyperspectral and multispectral imagery for remote sensing and biomedicine tasks. These multi-channel images come with their own unique set of challenges that must be addressed for effective image analysis. Challenges include limited ground truth (annotation is expensive and extensive labeling is often not feasible), and high dimensional nature of the data (each pixel is represented by hundreds of spectral bands), despite being presented by a large amount of unlabeled data and the potential to leverage multiple sensors/sources that observe the same scene. In this chapter, we will review recent advances in the community that leverage deep learning for robust hyperspectral image analysis despite these unique challenges -- specifically, we will review unsupervised, semi-supervised and active learning approaches to image analysis, as well as transfer learning approaches for multi-source (e.g. multi-sensor, or multi-temporal) image analysis.