 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAttacks as Defenses: Designing Robust Audio CAPTCHAs Using Attacks on Automatic Speech Recognition Systems
Mar 10, 2022
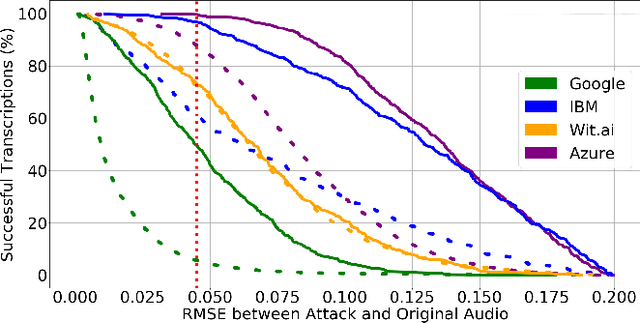

Audio CAPTCHAs are supposed to provide a strong defense for online resources; however, advances in speech-to-text mechanisms have rendered these defenses ineffective. Audio CAPTCHAs cannot simply be abandoned, as they are specifically named by the W3C as important enablers of accessibility. Accordingly, demonstrably more robust audio CAPTCHAs are important to the future of a secure and accessible Web. We look to recent literature on attacks on speech-to-text systems for inspiration for the construction of robust, principle-driven audio defenses. We begin by comparing 20 recent attack papers, classifying and measuring their suitability to serve as the basis of new "robust to transcription" but "easy for humans to understand" CAPTCHAs. After showing that none of these attacks alone are sufficient, we propose a new mechanism that is both comparatively intelligible (evaluated through a user study) and hard to automatically transcribe (i.e., $P({\rm transcription}) = 4 \times 10^{-5}$). Finally, we demonstrate that our audio samples have a high probability of being detected as CAPTCHAs when given to speech-to-text systems ($P({\rm evasion}) = 1.77 \times 10^{-4}$). In so doing, we not only demonstrate a CAPTCHA that is approximately four orders of magnitude more difficult to crack, but that such systems can be designed based on the insights gained from attack papers using the differences between the ways that humans and computers process audio.
Beyond $L_p$ clipping: Equalization-based Psychoacoustic Attacks against ASRs
Oct 25, 2021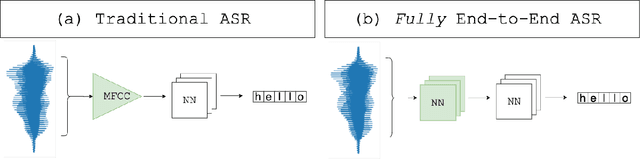

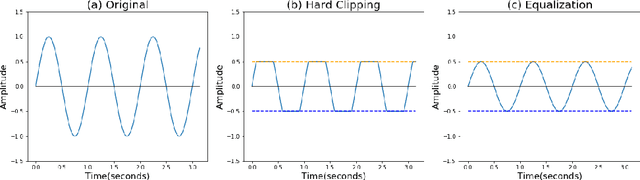
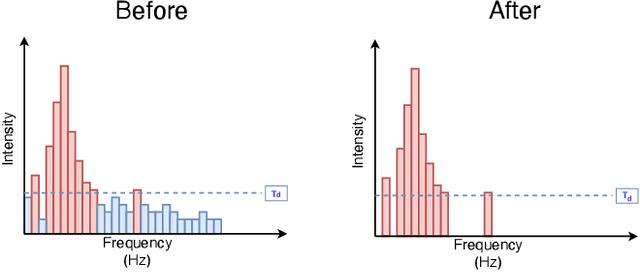
Automatic Speech Recognition (ASR) systems convert speech into text and can be placed into two broad categories: traditional and fully end-to-end. Both types have been shown to be vulnerable to adversarial audio examples that sound benign to the human ear but force the ASR to produce malicious transcriptions. Of these attacks, only the "psychoacoustic" attacks can create examples with relatively imperceptible perturbations, as they leverage the knowledge of the human auditory system. Unfortunately, existing psychoacoustic attacks can only be applied against traditional models, and are obsolete against the newer, fully end-to-end ASRs. In this paper, we propose an equalization-based psychoacoustic attack that can exploit both traditional and fully end-to-end ASRs. We successfully demonstrate our attack against real-world ASRs that include DeepSpeech and Wav2Letter. Moreover, we employ a user study to verify that our method creates low audible distortion. Specifically, 80 of the 100 participants voted in favor of all our attack audio samples as less noisier than the existing state-of-the-art attack. Through this, we demonstrate both types of existing ASR pipelines can be exploited with minimum degradation to attack audio quality.
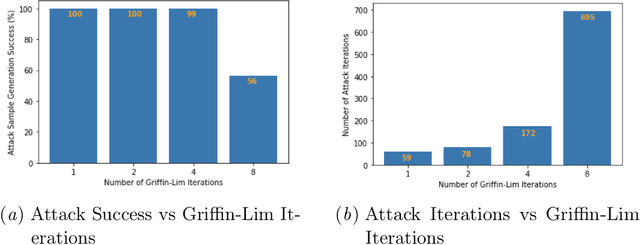
Hear "No Evil", See "Kenansville": Efficient and Transferable Black-Box Attacks on Speech Recognition and Voice Identification Systems
Oct 11, 2019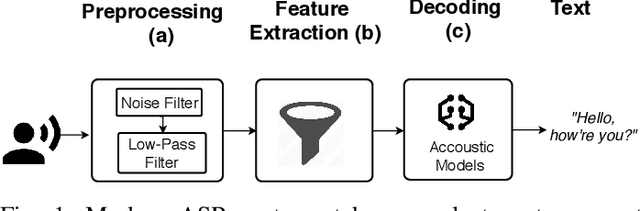
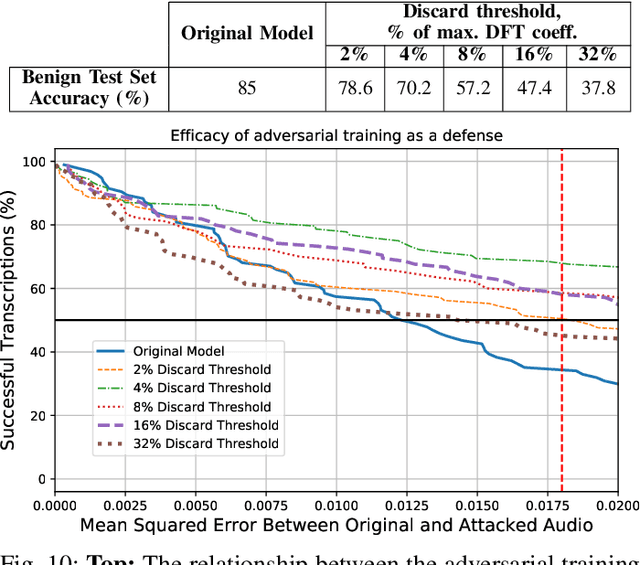
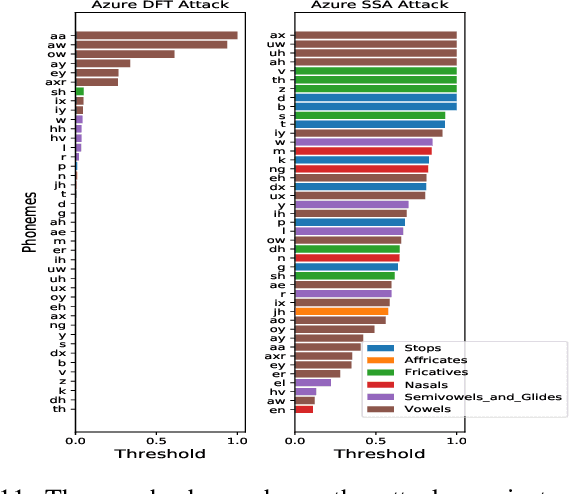
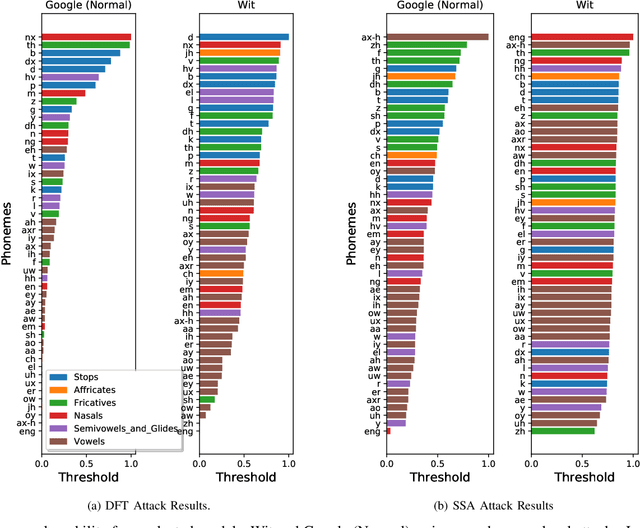
Automatic speech recognition and voice identification systems are being deployed in a wide array of applications, from providing control mechanisms to devices lacking traditional interfaces, to the automatic transcription of conversations and authentication of users. Many of these applications have significant security and privacy considerations. We develop attacks that force mistranscription and misidentification in state of the art systems, with minimal impact on human comprehension. Processing pipelines for modern systems are comprised of signal preprocessing and feature extraction steps, whose output is fed to a machine-learned model. Prior work has focused on the models, using white-box knowledge to tailor model-specific attacks. We focus on the pipeline stages before the models, which (unlike the models) are quite similar across systems. As such, our attacks are black-box and transferable, and demonstrably achieve mistranscription and misidentification rates as high as 100% by modifying only a few frames of audio. We perform a study via Amazon Mechanical Turk demonstrating that there is no statistically significant difference between human perception of regular and perturbed audio. Our findings suggest that models may learn aspects of speech that are generally not perceived by human subjects, but that are crucial for model accuracy. We also find that certain English language phonemes (in particular, vowels) are significantly more susceptible to our attack. We show that the attacks are effective when mounted over cellular networks, where signals are subject to degradation due to transcoding, jitter, and packet loss.