 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnalyzing the AI Nudification Application Ecosystem
Nov 14, 2024



Given a source image of a clothed person (an image subject), AI-based nudification applications can produce nude (undressed) images of that person. Moreover, not only do such applications exist, but there is ample evidence of the use of such applications in the real world and without the consent of an image subject. Still, despite the growing awareness of the existence of such applications and their potential to violate the rights of image subjects and cause downstream harms, there has been no systematic study of the nudification application ecosystem across multiple applications. We conduct such a study here, focusing on 20 popular and easy-to-find nudification websites. We study the positioning of these web applications (e.g., finding that most sites explicitly target the nudification of women, not all people), the features that they advertise (e.g., ranging from undressing-in-place to the rendering of image subjects in sexual positions, as well as differing user-privacy options), and their underlying monetization infrastructure (e.g., credit cards and cryptocurrencies). We believe this work will empower future, data-informed conversations -- within the scientific, technical, and policy communities -- on how to better protect individuals' rights and minimize harm in the face of modern (and future) AI-based nudification applications. Content warning: This paper includes descriptions of web applications that can be used to create synthetic non-consensual explicit AI-created imagery (SNEACI). This paper also includes an artistic rendering of a user interface for such an application.
Beyond $L_p$ clipping: Equalization-based Psychoacoustic Attacks against ASRs
Oct 25, 2021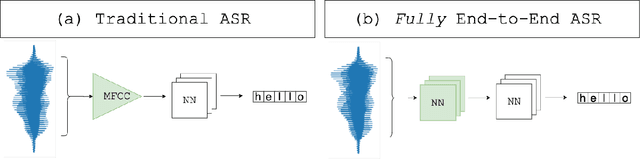

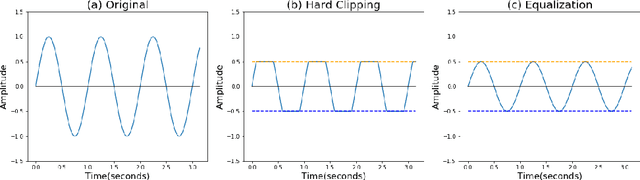
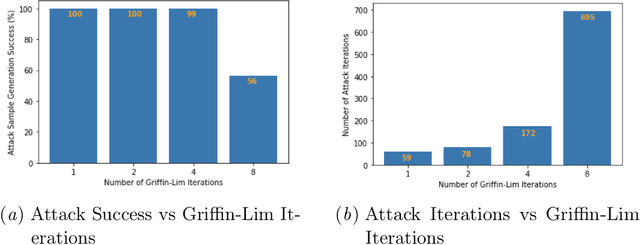
Automatic Speech Recognition (ASR) systems convert speech into text and can be placed into two broad categories: traditional and fully end-to-end. Both types have been shown to be vulnerable to adversarial audio examples that sound benign to the human ear but force the ASR to produce malicious transcriptions. Of these attacks, only the "psychoacoustic" attacks can create examples with relatively imperceptible perturbations, as they leverage the knowledge of the human auditory system. Unfortunately, existing psychoacoustic attacks can only be applied against traditional models, and are obsolete against the newer, fully end-to-end ASRs. In this paper, we propose an equalization-based psychoacoustic attack that can exploit both traditional and fully end-to-end ASRs. We successfully demonstrate our attack against real-world ASRs that include DeepSpeech and Wav2Letter. Moreover, we employ a user study to verify that our method creates low audible distortion. Specifically, 80 of the 100 participants voted in favor of all our attack audio samples as less noisier than the existing state-of-the-art attack. Through this, we demonstrate both types of existing ASR pipelines can be exploited with minimum degradation to attack audio quality.