 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStacked Universal Successor Feature Approximators for Safety in Reinforcement Learning
Sep 06, 2024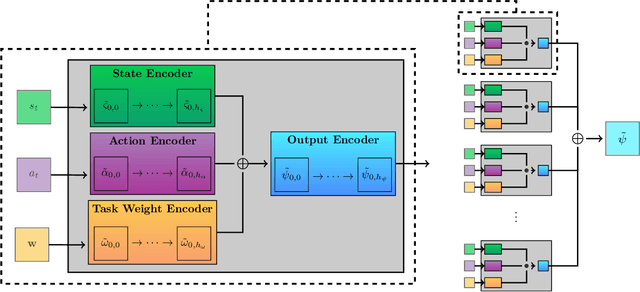
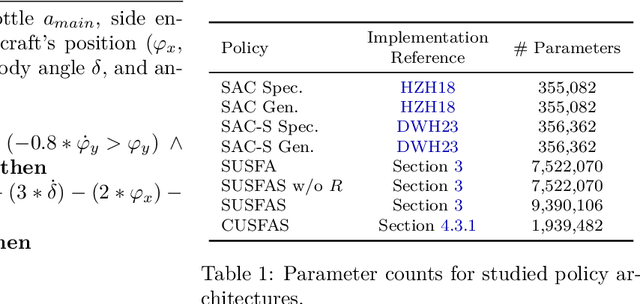
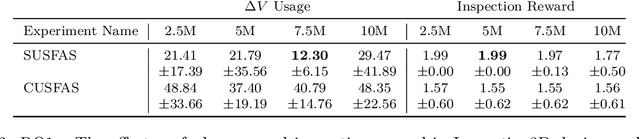
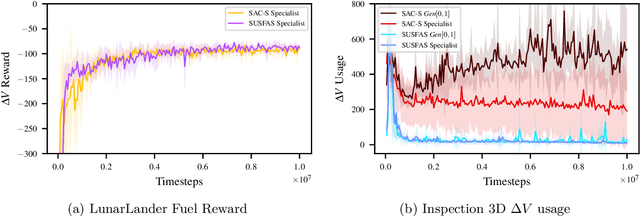
Real-world problems often involve complex objective structures that resist distillation into reinforcement learning environments with a single objective. Operation costs must be balanced with multi-dimensional task performance and end-states' effects on future availability, all while ensuring safety for other agents in the environment and the reinforcement learning agent itself. System redundancy through secondary backup controllers has proven to be an effective method to ensure safety in real-world applications where the risk of violating constraints is extremely high. In this work, we investigate the utility of a stacked, continuous-control variation of universal successor feature approximation (USFA) adapted for soft actor-critic (SAC) and coupled with a suite of secondary safety controllers, which we call stacked USFA for safety (SUSFAS). Our method improves performance on secondary objectives compared to SAC baselines using an intervening secondary controller such as a runtime assurance (RTA) controller.
Beyond $L_p$ clipping: Equalization-based Psychoacoustic Attacks against ASRs
Oct 25, 2021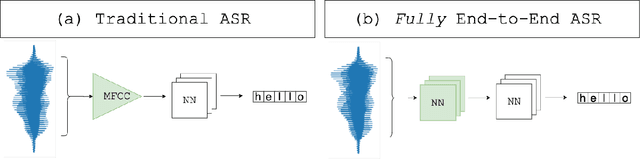

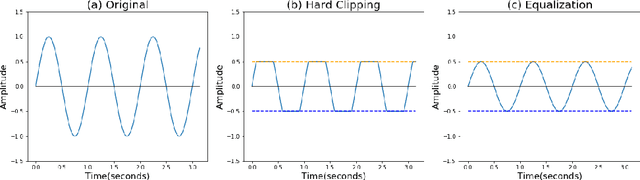
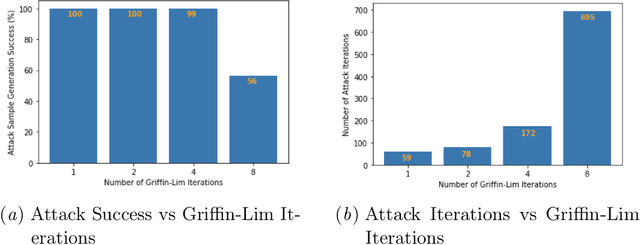
Automatic Speech Recognition (ASR) systems convert speech into text and can be placed into two broad categories: traditional and fully end-to-end. Both types have been shown to be vulnerable to adversarial audio examples that sound benign to the human ear but force the ASR to produce malicious transcriptions. Of these attacks, only the "psychoacoustic" attacks can create examples with relatively imperceptible perturbations, as they leverage the knowledge of the human auditory system. Unfortunately, existing psychoacoustic attacks can only be applied against traditional models, and are obsolete against the newer, fully end-to-end ASRs. In this paper, we propose an equalization-based psychoacoustic attack that can exploit both traditional and fully end-to-end ASRs. We successfully demonstrate our attack against real-world ASRs that include DeepSpeech and Wav2Letter. Moreover, we employ a user study to verify that our method creates low audible distortion. Specifically, 80 of the 100 participants voted in favor of all our attack audio samples as less noisier than the existing state-of-the-art attack. Through this, we demonstrate both types of existing ASR pipelines can be exploited with minimum degradation to attack audio quality.
Hard-label Manifolds: Unexpected Advantages of Query Efficiency for Finding On-manifold Adversarial Examples
Mar 04, 2021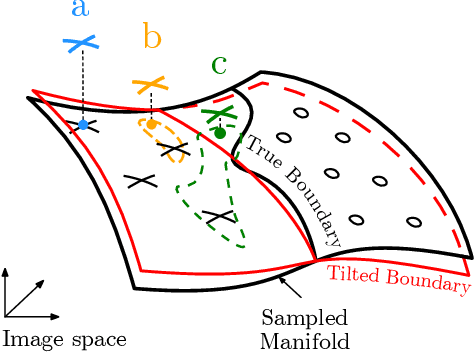
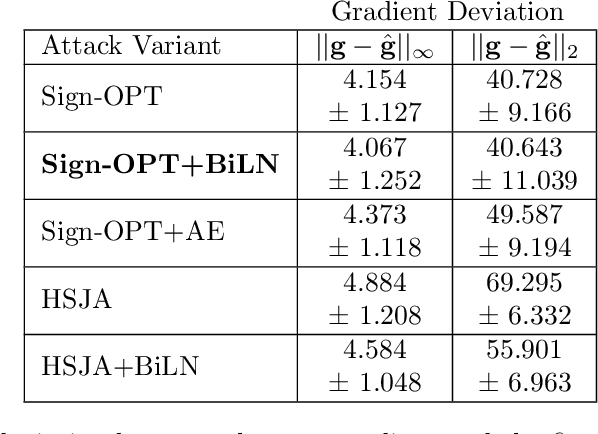
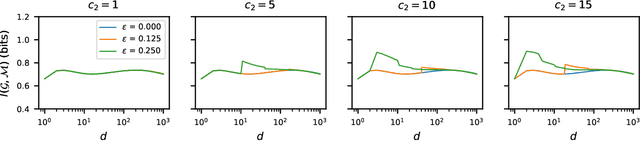
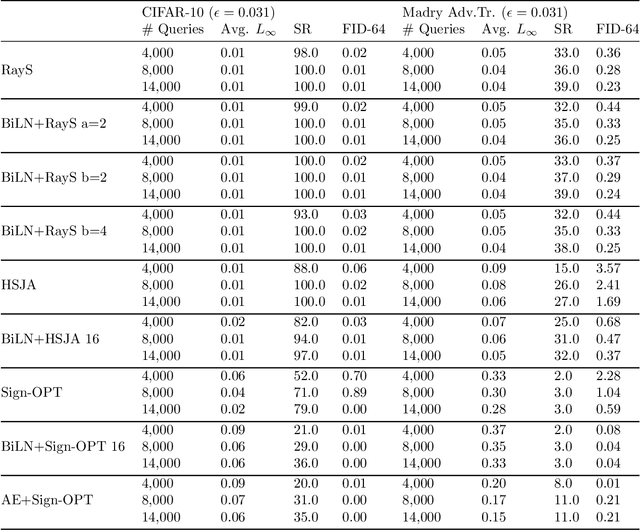
Designing deep networks robust to adversarial examples remains an open problem. Likewise, recent zeroth order hard-label attacks on image classification models have shown comparable performance to their first-order, gradient-level alternatives. It was recently shown in the gradient-level setting that regular adversarial examples leave the data manifold, while their on-manifold counterparts are in fact generalization errors. In this paper, we argue that query efficiency in the zeroth-order setting is connected to an adversary's traversal through the data manifold. To explain this behavior, we propose an information-theoretic argument based on a noisy manifold distance oracle, which leaks manifold information through the adversary's gradient estimate. Through numerical experiments of manifold-gradient mutual information, we show this behavior acts as a function of the effective problem dimensionality and number of training points. On real-world datasets and multiple zeroth-order attacks using dimension-reduction, we observe the same universal behavior to produce samples closer to the data manifold. This results in up to two-fold decrease in the manifold distance measure, regardless of the model robustness. Our results suggest that taking the manifold-gradient mutual information into account can thus inform better robust model design in the future, and avoid leakage of the sensitive data manifold.
Hear "No Evil", See "Kenansville": Efficient and Transferable Black-Box Attacks on Speech Recognition and Voice Identification Systems
Oct 11, 2019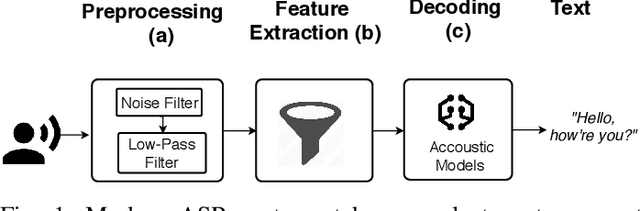
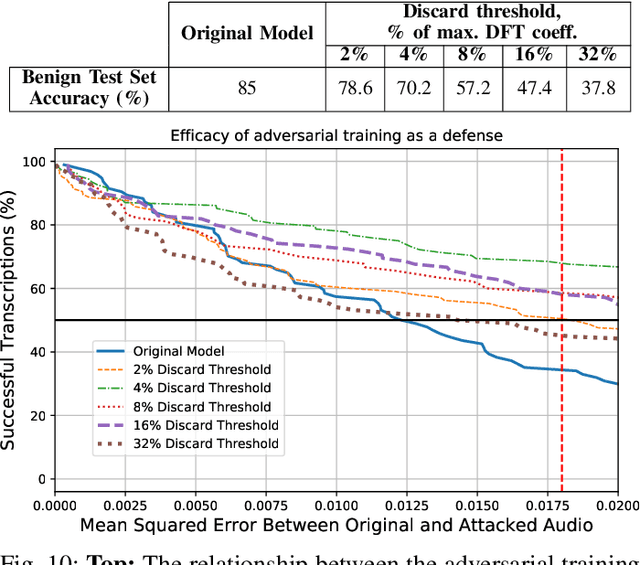
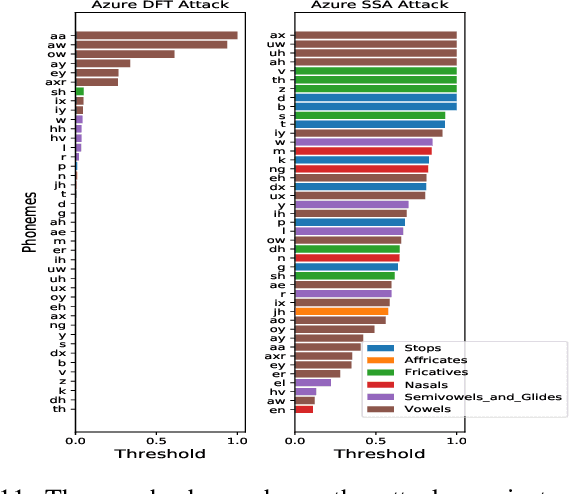
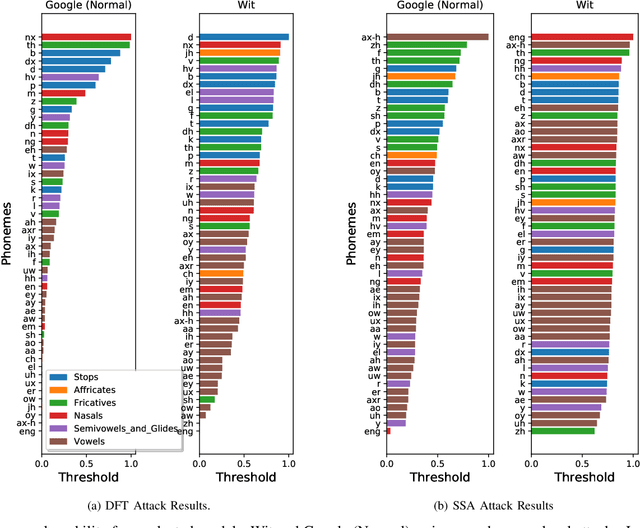
Automatic speech recognition and voice identification systems are being deployed in a wide array of applications, from providing control mechanisms to devices lacking traditional interfaces, to the automatic transcription of conversations and authentication of users. Many of these applications have significant security and privacy considerations. We develop attacks that force mistranscription and misidentification in state of the art systems, with minimal impact on human comprehension. Processing pipelines for modern systems are comprised of signal preprocessing and feature extraction steps, whose output is fed to a machine-learned model. Prior work has focused on the models, using white-box knowledge to tailor model-specific attacks. We focus on the pipeline stages before the models, which (unlike the models) are quite similar across systems. As such, our attacks are black-box and transferable, and demonstrably achieve mistranscription and misidentification rates as high as 100% by modifying only a few frames of audio. We perform a study via Amazon Mechanical Turk demonstrating that there is no statistically significant difference between human perception of regular and perturbed audio. Our findings suggest that models may learn aspects of speech that are generally not perceived by human subjects, but that are crucial for model accuracy. We also find that certain English language phonemes (in particular, vowels) are significantly more susceptible to our attack. We show that the attacks are effective when mounted over cellular networks, where signals are subject to degradation due to transcoding, jitter, and packet loss.
Practical Hidden Voice Attacks against Speech and Speaker Recognition Systems
Mar 18, 2019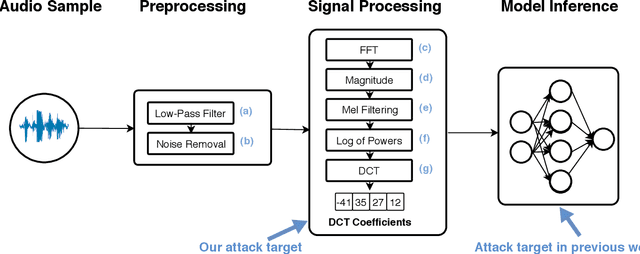
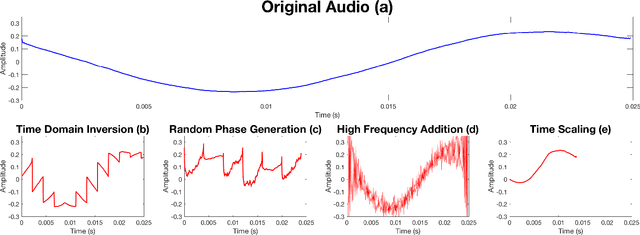
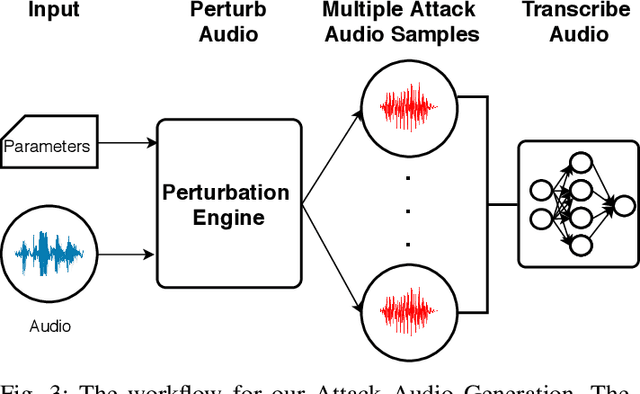
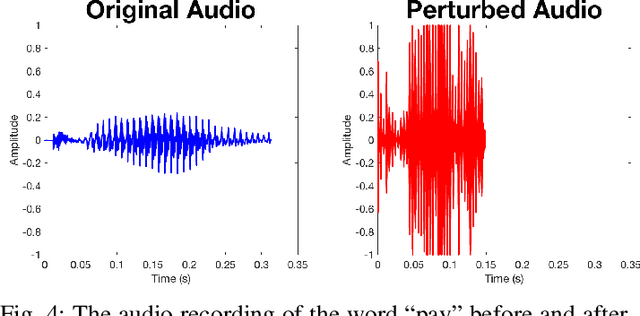
Voice Processing Systems (VPSes), now widely deployed, have been made significantly more accurate through the application of recent advances in machine learning. However, adversarial machine learning has similarly advanced and has been used to demonstrate that VPSes are vulnerable to the injection of hidden commands - audio obscured by noise that is correctly recognized by a VPS but not by human beings. Such attacks, though, are often highly dependent on white-box knowledge of a specific machine learning model and limited to specific microphones and speakers, making their use across different acoustic hardware platforms (and thus their practicality) limited. In this paper, we break these dependencies and make hidden command attacks more practical through model-agnostic (blackbox) attacks, which exploit knowledge of the signal processing algorithms commonly used by VPSes to generate the data fed into machine learning systems. Specifically, we exploit the fact that multiple source audio samples have similar feature vectors when transformed by acoustic feature extraction algorithms (e.g., FFTs). We develop four classes of perturbations that create unintelligible audio and test them against 12 machine learning models, including 7 proprietary models (e.g., Google Speech API, Bing Speech API, IBM Speech API, Azure Speaker API, etc), and demonstrate successful attacks against all targets. Moreover, we successfully use our maliciously generated audio samples in multiple hardware configurations, demonstrating effectiveness across both models and real systems. In so doing, we demonstrate that domain-specific knowledge of audio signal processing represents a practical means of generating successful hidden voice command attacks.
Explainable Black-Box Attacks Against Model-based Authentication
Sep 28, 2018
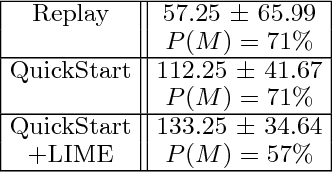
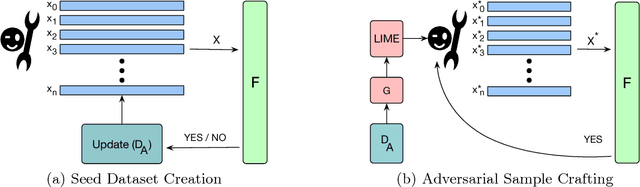
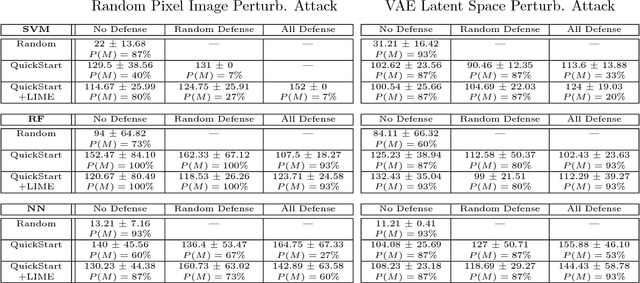
Establishing unique identities for both humans and end systems has been an active research problem in the security community, giving rise to innovative machine learning-based authentication techniques. Although such techniques offer an automated method to establish identity, they have not been vetted against sophisticated attacks that target their core machine learning technique. This paper demonstrates that mimicking the unique signatures generated by host fingerprinting and biometric authentication systems is possible. We expose the ineffectiveness of underlying machine learning classification models by constructing a blind attack based around the query synthesis framework and utilizing Explainable-AI (XAI) techniques. We launch an attack in under 130 queries on a state-of-the-art face authentication system, and under 100 queries on a host authentication system. We examine how these attacks can be defended against and explore their limitations. XAI provides an effective means for adversaries to infer decision boundaries and provides a new way forward in constructing attacks against systems using machine learning models for authentication.
MTLE: A Multitask Learning Encoder of Visual Feature Representations for Video and Movie Description
Sep 19, 2018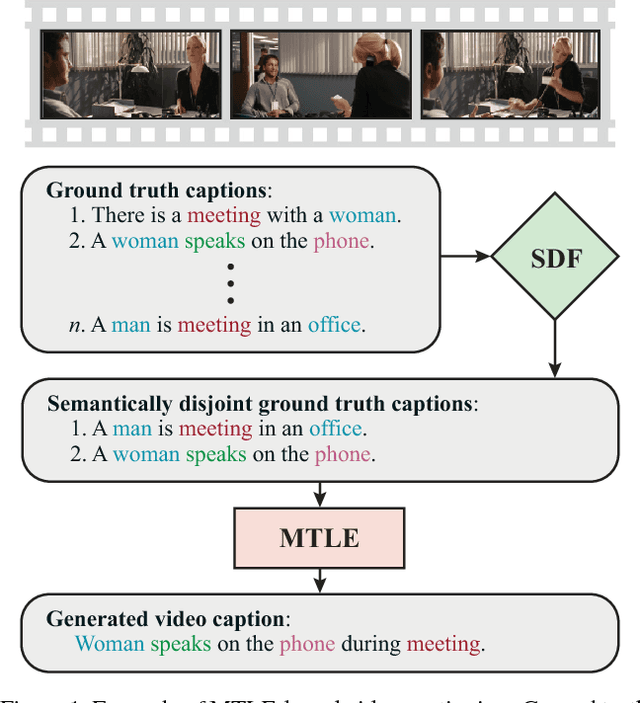

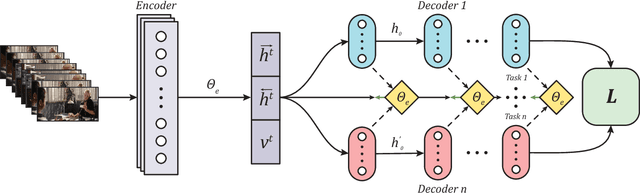
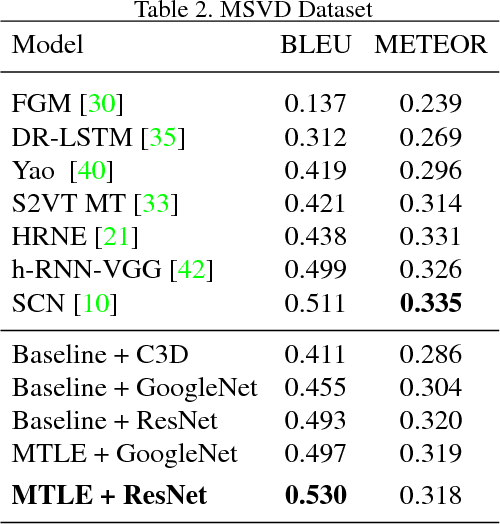
Learning visual feature representations for video analysis is a daunting task that requires a large amount of training samples and a proper generalization framework. Many of the current state of the art methods for video captioning and movie description rely on simple encoding mechanisms through recurrent neural networks to encode temporal visual information extracted from video data. In this paper, we introduce a novel multitask encoder-decoder framework for automatic semantic description and captioning of video sequences. In contrast to current approaches, our method relies on distinct decoders that train a visual encoder in a multitask fashion. Our system does not depend solely on multiple labels and allows for a lack of training data working even with datasets where only one single annotation is viable per video. Our method shows improved performance over current state of the art methods in several metrics on multi-caption and single-caption datasets. To the best of our knowledge, our method is the first method to use a multitask approach for encoding video features. Our method demonstrates its robustness on the Large Scale Movie Description Challenge (LSMDC) 2017 where our method won the movie description task and its results were ranked among other competitors as the most helpful for the visually impaired.