 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSensemaking in Novel Environments: How Human Cognition Can Inform Artificial Agents
Mar 10, 2025One of the most vital cognitive skills to possess is the ability to make sense of objects, events, and situations in the world. In the current paper, we offer an approach for creating artificially intelligent agents with the capacity for sensemaking in novel environments. Objectives: to present several key ideas: (1) a novel unified conceptual framework for sensemaking (which includes the existence of sign relations embedded within and across frames); (2) interaction among various content-addressable, distributed-knowledge structures via shared attributes (whose net response would represent a synthesized object, event, or situation serving as a sign for sensemaking in a novel environment). Findings: we suggest that attributes across memories can be shared and recombined in novel ways to create synthesized signs, which can denote certain outcomes in novel environments (i.e., sensemaking).
Hard-label Manifolds: Unexpected Advantages of Query Efficiency for Finding On-manifold Adversarial Examples
Mar 04, 2021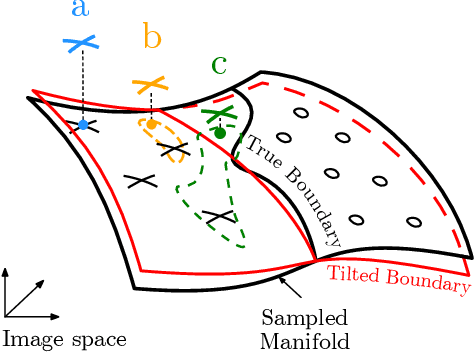
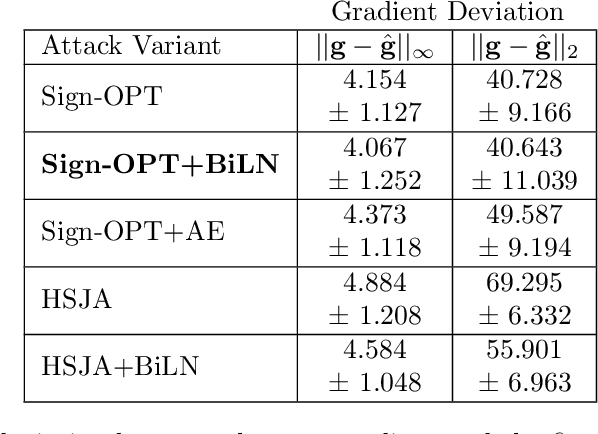
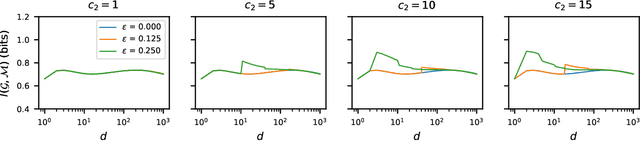
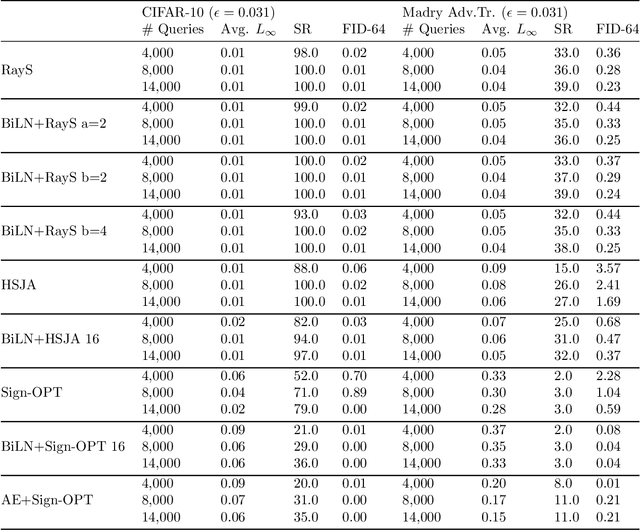
Designing deep networks robust to adversarial examples remains an open problem. Likewise, recent zeroth order hard-label attacks on image classification models have shown comparable performance to their first-order, gradient-level alternatives. It was recently shown in the gradient-level setting that regular adversarial examples leave the data manifold, while their on-manifold counterparts are in fact generalization errors. In this paper, we argue that query efficiency in the zeroth-order setting is connected to an adversary's traversal through the data manifold. To explain this behavior, we propose an information-theoretic argument based on a noisy manifold distance oracle, which leaks manifold information through the adversary's gradient estimate. Through numerical experiments of manifold-gradient mutual information, we show this behavior acts as a function of the effective problem dimensionality and number of training points. On real-world datasets and multiple zeroth-order attacks using dimension-reduction, we observe the same universal behavior to produce samples closer to the data manifold. This results in up to two-fold decrease in the manifold distance measure, regardless of the model robustness. Our results suggest that taking the manifold-gradient mutual information into account can thus inform better robust model design in the future, and avoid leakage of the sensitive data manifold.
MTLE: A Multitask Learning Encoder of Visual Feature Representations for Video and Movie Description
Sep 19, 2018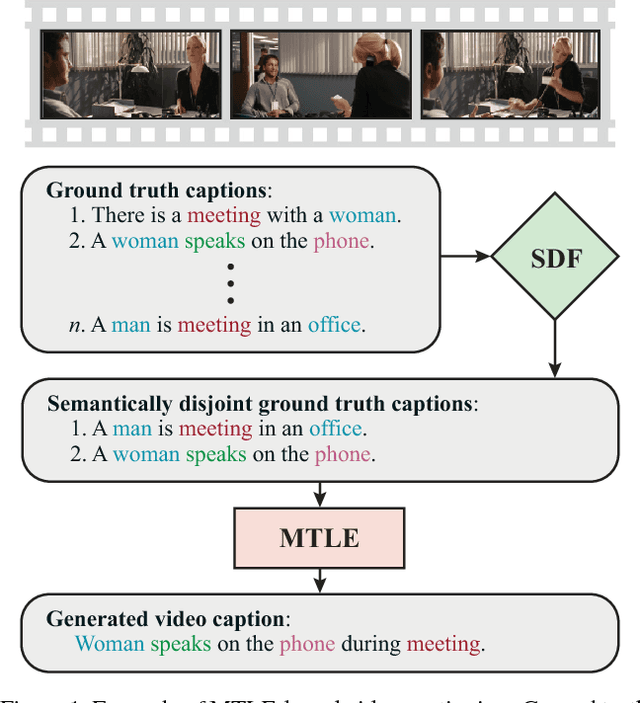

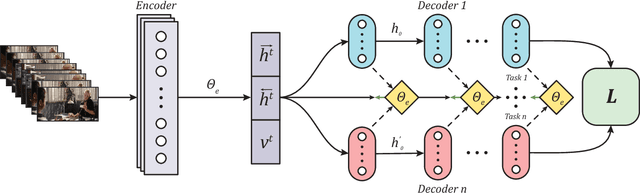
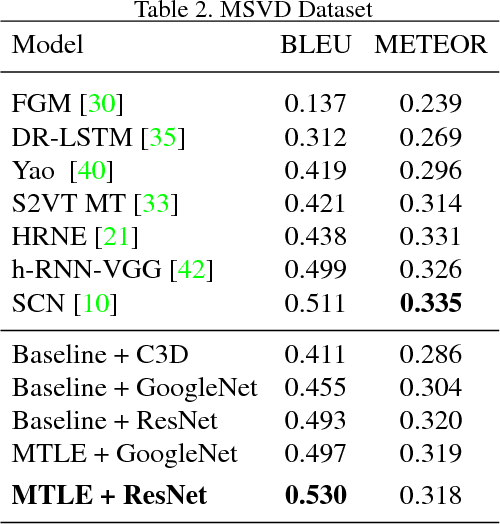
Learning visual feature representations for video analysis is a daunting task that requires a large amount of training samples and a proper generalization framework. Many of the current state of the art methods for video captioning and movie description rely on simple encoding mechanisms through recurrent neural networks to encode temporal visual information extracted from video data. In this paper, we introduce a novel multitask encoder-decoder framework for automatic semantic description and captioning of video sequences. In contrast to current approaches, our method relies on distinct decoders that train a visual encoder in a multitask fashion. Our system does not depend solely on multiple labels and allows for a lack of training data working even with datasets where only one single annotation is viable per video. Our method shows improved performance over current state of the art methods in several metrics on multi-caption and single-caption datasets. To the best of our knowledge, our method is the first method to use a multitask approach for encoding video features. Our method demonstrates its robustness on the Large Scale Movie Description Challenge (LSMDC) 2017 where our method won the movie description task and its results were ranked among other competitors as the most helpful for the visually impaired.