 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHierarchical Multi-Stage Transformer Architecture for Context-Aware Temporal Action Localization
Jul 08, 2025Inspired by the recent success of transformers and multi-stage architectures in video recognition and object detection domains. We thoroughly explore the rich spatio-temporal properties of transformers within a multi-stage architecture paradigm for the temporal action localization (TAL) task. This exploration led to the development of a hierarchical multi-stage transformer architecture called PCL-Former, where each subtask is handled by a dedicated transformer module with a specialized loss function. Specifically, the Proposal-Former identifies candidate segments in an untrimmed video that may contain actions, the Classification-Former classifies the action categories within those segments, and the Localization-Former precisely predicts the temporal boundaries (i.e., start and end) of the action instances. To evaluate the performance of our method, we have conducted extensive experiments on three challenging benchmark datasets: THUMOS-14, ActivityNet-1.3, and HACS Segments. We also conducted detailed ablation experiments to assess the impact of each individual module of our PCL-Former. The obtained quantitative results validate the effectiveness of the proposed PCL-Former, outperforming state-of-the-art TAL approaches by 2.8%, 1.2%, and 4.8% on THUMOS14, ActivityNet-1.3, and HACS datasets, respectively.
NTIRE 2021 Multi-modal Aerial View Object Classification Challenge
Jul 02, 2021
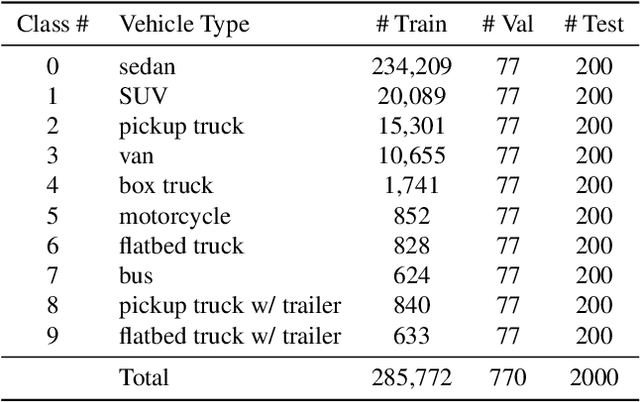
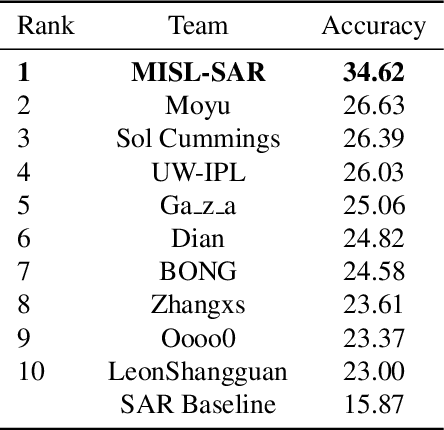
In this paper, we introduce the first Challenge on Multi-modal Aerial View Object Classification (MAVOC) in conjunction with the NTIRE 2021 workshop at CVPR. This challenge is composed of two different tracks using EO andSAR imagery. Both EO and SAR sensors possess different advantages and drawbacks. The purpose of this competition is to analyze how to use both sets of sensory information in complementary ways. We discuss the top methods submitted for this competition and evaluate their results on our blind test set. Our challenge results show significant improvement of more than 15% accuracy from our current baselines for each track of the competition
* 10 pages, 1 figure. Conference on Computer Vision and Pattern Recognition
MTLE: A Multitask Learning Encoder of Visual Feature Representations for Video and Movie Description
Sep 19, 2018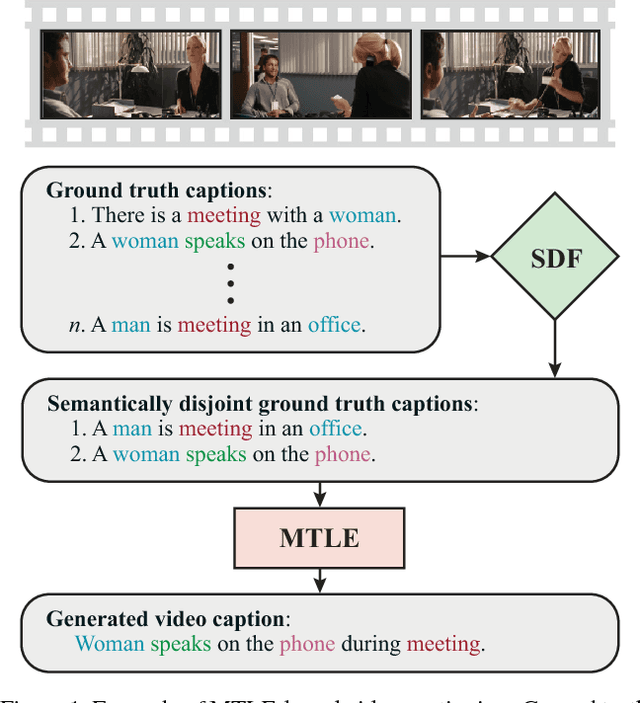

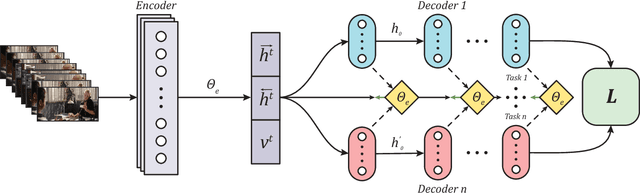
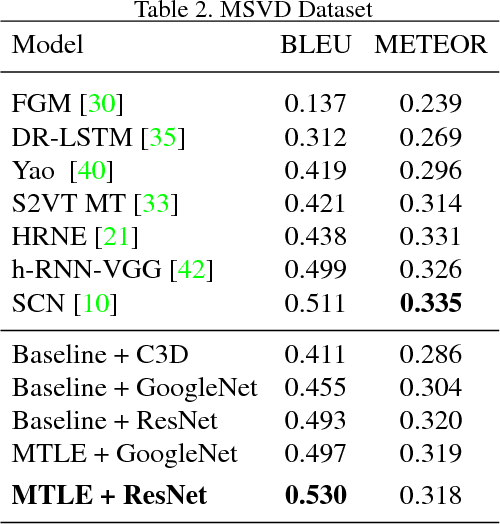
Learning visual feature representations for video analysis is a daunting task that requires a large amount of training samples and a proper generalization framework. Many of the current state of the art methods for video captioning and movie description rely on simple encoding mechanisms through recurrent neural networks to encode temporal visual information extracted from video data. In this paper, we introduce a novel multitask encoder-decoder framework for automatic semantic description and captioning of video sequences. In contrast to current approaches, our method relies on distinct decoders that train a visual encoder in a multitask fashion. Our system does not depend solely on multiple labels and allows for a lack of training data working even with datasets where only one single annotation is viable per video. Our method shows improved performance over current state of the art methods in several metrics on multi-caption and single-caption datasets. To the best of our knowledge, our method is the first method to use a multitask approach for encoding video features. Our method demonstrates its robustness on the Large Scale Movie Description Challenge (LSMDC) 2017 where our method won the movie description task and its results were ranked among other competitors as the most helpful for the visually impaired.