 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIs the Last Layer Sufficient for Uncertainty Quantification?
May 29, 2026Epistemic uncertainty quantification (UQ) for deep neural networks (DNNs) is a requirement for safe adoption of AI in mission-critical settings. Several leading methods for UQ linearize DNNs to form Bayesian Generalized Linear Models (GLMs), where epistemic uncertainty is modeled via the predictive posterior distribution. Linearizing around the parameters of the final connected layer of a DNN is a commonly used approximation for reducing the computational burden of such GLMs, though it is often believed to come at the cost of degraded performance. In this work, we compare GLMs arising from full-network and last-layer linearization using both theoretical and empirical approaches. We first employ tools from random matrix theory to conduct a theoretical comparison; this analysis reveals no meaningful improvement in the UQ capabilities of full linearization. Coupled with a large-scale empirical evaluation across a range of modern machine learning tasks, we arrive at the following conclusion: a last-layer approximation yields comparable UQ performance while offering substantially improved computational efficiency.
From Theory to Practice: Code Generation Using LLMs for CAPEC and CWE Frameworks
Apr 02, 2026The increasing complexity and volume of software systems have heightened the importance of identifying and mitigating security vulnerabilities. The existing software vulnerability datasets frequently fall short in providing comprehensive, detailed code snippets explicitly linked to specific vulnerability descriptions, reducing their utility for advanced research and hindering efforts to develop a deeper understanding of security vulnerabilities. To address this challenge, we present a novel dataset that provides examples of vulnerable code snippets corresponding to Common Attack Pattern Enumerations and Classifications (CAPEC) and Common Weakness Enumeration (CWE) descriptions. By employing the capabilities of Generative Pre-trained Transformer (GPT) models, we have developed a robust methodology for generating these examples. Our approach utilizes GPT-4o, Llama and Claude models to generate code snippets that exhibit specific vulnerabilities as described in CAPEC and CWE documentation. This dataset not only enhances the understanding of security vulnerabilities in code but also serves as a valuable resource for training machine learning models focused on automatic vulnerability detection and remediation. Preliminary evaluations suggest that the dataset generated by Large Language Models demonstrates high accuracy and can serve as a reliable reference for vulnerability identification systems. We found consistent results across the three models, with 0.98 cosine similarity among codes. The final dataset comprises 615 CAPEC code snippets in three programming languages: Java, Python, and JavaScript, making it one of the most extensive and diverse resources in this domain.
Uncertainty Quantification with the Empirical Neural Tangent Kernel
Feb 05, 2025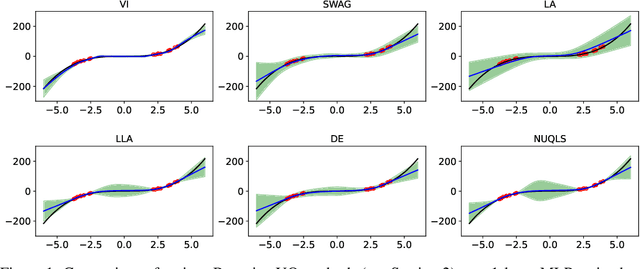
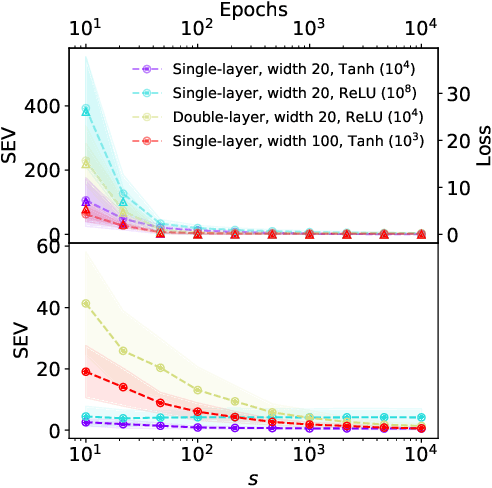
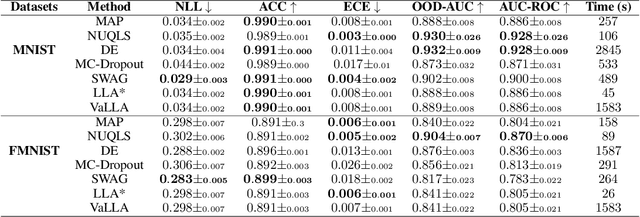
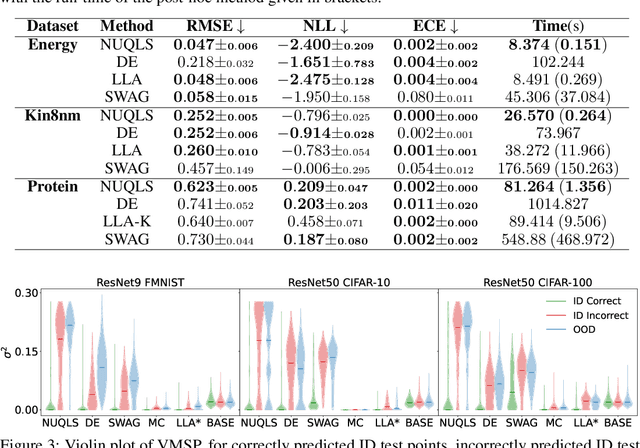
While neural networks have demonstrated impressive performance across various tasks, accurately quantifying uncertainty in their predictions is essential to ensure their trustworthiness and enable widespread adoption in critical systems. Several Bayesian uncertainty quantification (UQ) methods exist that are either cheap or reliable, but not both. We propose a post-hoc, sampling-based UQ method for over-parameterized networks at the end of training. Our approach constructs efficient and meaningful deep ensembles by employing a (stochastic) gradient-descent sampling process on appropriately linearized networks. We demonstrate that our method effectively approximates the posterior of a Gaussian process using the empirical Neural Tangent Kernel. Through a series of numerical experiments, we show that our method not only outperforms competing approaches in computational efficiency (often reducing costs by multiple factors) but also maintains state-of-the-art performance across a variety of UQ metrics for both regression and classification tasks.
Aya Dataset: An Open-Access Collection for Multilingual Instruction Tuning
Feb 09, 2024
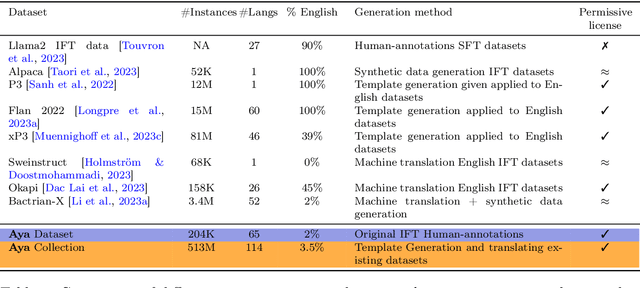
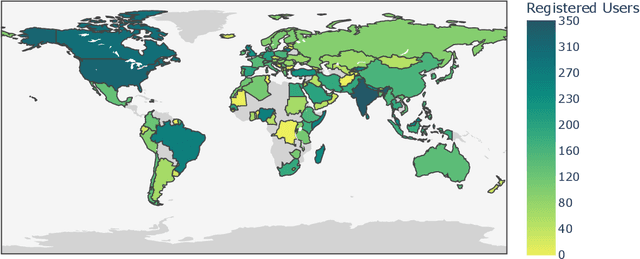
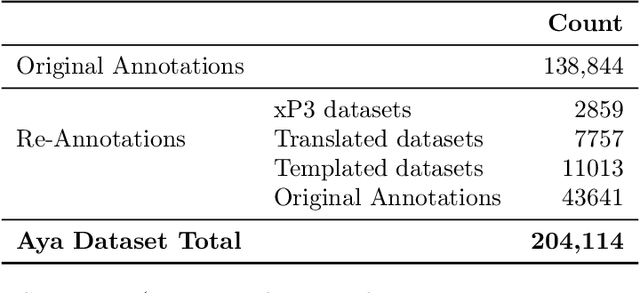
Datasets are foundational to many breakthroughs in modern artificial intelligence. Many recent achievements in the space of natural language processing (NLP) can be attributed to the finetuning of pre-trained models on a diverse set of tasks that enables a large language model (LLM) to respond to instructions. Instruction fine-tuning (IFT) requires specifically constructed and annotated datasets. However, existing datasets are almost all in the English language. In this work, our primary goal is to bridge the language gap by building a human-curated instruction-following dataset spanning 65 languages. We worked with fluent speakers of languages from around the world to collect natural instances of instructions and completions. Furthermore, we create the most extensive multilingual collection to date, comprising 513 million instances through templating and translating existing datasets across 114 languages. In total, we contribute four key resources: we develop and open-source the Aya Annotation Platform, the Aya Dataset, the Aya Collection, and the Aya Evaluation Suite. The Aya initiative also serves as a valuable case study in participatory research, involving collaborators from 119 countries. We see this as a valuable framework for future research collaborations that aim to bridge gaps in resources.
Dynamic Semantic Occupancy Mapping using 3D Scene Flow and Closed-Form Bayesian Inference
Aug 06, 2021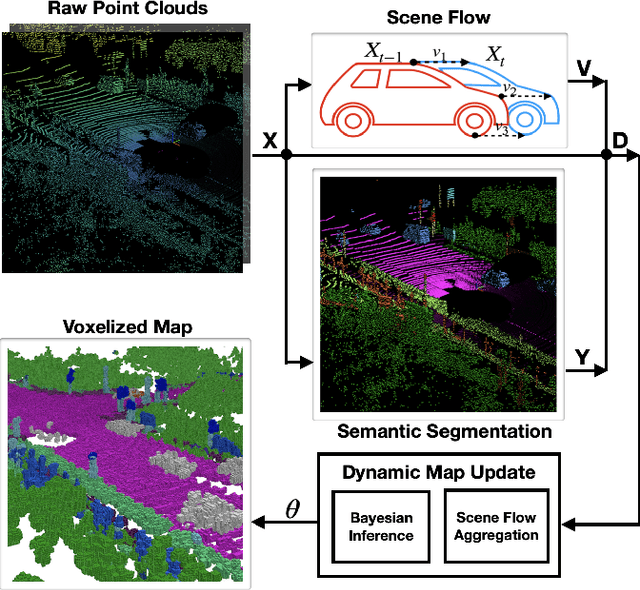
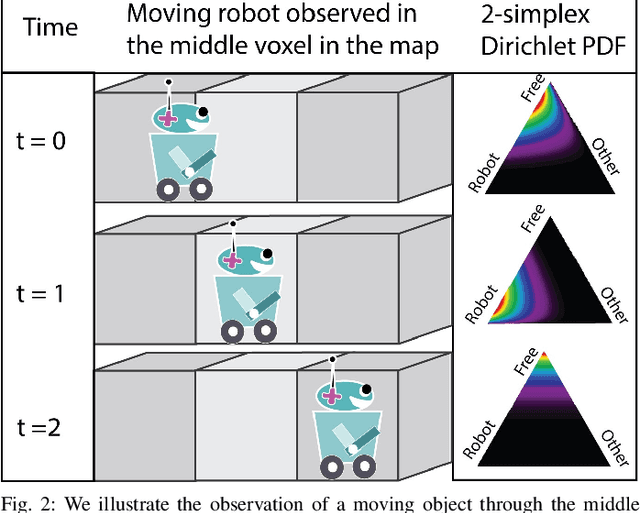
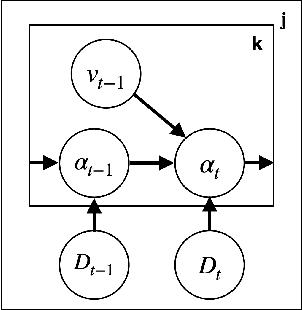

This paper reports on a dynamic semantic mapping framework that incorporates 3D scene flow measurements into a closed-form Bayesian inference model. Existence of dynamic objects in the environment cause artifacts and traces in current mapping algorithms, leading to an inconsistent map posterior. We leverage state-of-the-art semantic segmentation and 3D flow estimation using deep learning to provide measurements for map inference. We develop a continuous (i.e., can be queried at arbitrary resolution) Bayesian model that propagates the scene with flow and infers a 3D semantic occupancy map with better performance than its static counterpart. Experimental results using publicly available data sets show that the proposed framework generalizes its predecessors and improves over direct measurements from deep neural networks consistently.
Practical Hidden Voice Attacks against Speech and Speaker Recognition Systems
Mar 18, 2019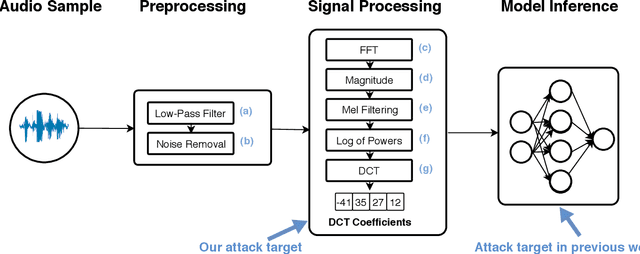
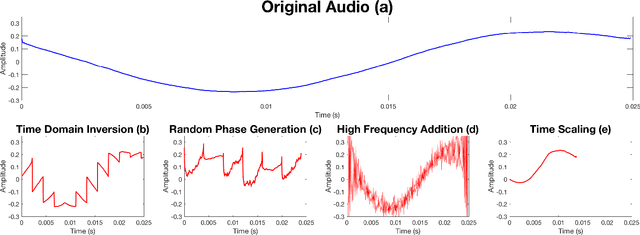
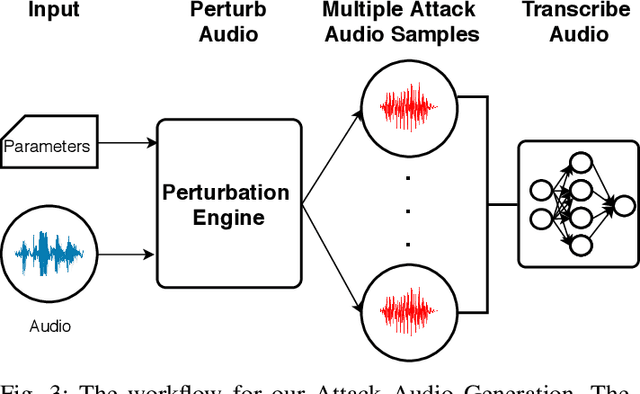
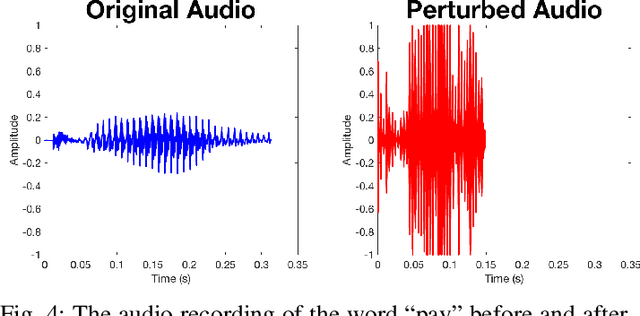
Voice Processing Systems (VPSes), now widely deployed, have been made significantly more accurate through the application of recent advances in machine learning. However, adversarial machine learning has similarly advanced and has been used to demonstrate that VPSes are vulnerable to the injection of hidden commands - audio obscured by noise that is correctly recognized by a VPS but not by human beings. Such attacks, though, are often highly dependent on white-box knowledge of a specific machine learning model and limited to specific microphones and speakers, making their use across different acoustic hardware platforms (and thus their practicality) limited. In this paper, we break these dependencies and make hidden command attacks more practical through model-agnostic (blackbox) attacks, which exploit knowledge of the signal processing algorithms commonly used by VPSes to generate the data fed into machine learning systems. Specifically, we exploit the fact that multiple source audio samples have similar feature vectors when transformed by acoustic feature extraction algorithms (e.g., FFTs). We develop four classes of perturbations that create unintelligible audio and test them against 12 machine learning models, including 7 proprietary models (e.g., Google Speech API, Bing Speech API, IBM Speech API, Azure Speaker API, etc), and demonstrate successful attacks against all targets. Moreover, we successfully use our maliciously generated audio samples in multiple hardware configurations, demonstrating effectiveness across both models and real systems. In so doing, we demonstrate that domain-specific knowledge of audio signal processing represents a practical means of generating successful hidden voice command attacks.