 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond $L_p$ clipping: Equalization-based Psychoacoustic Attacks against ASRs
Oct 25, 2021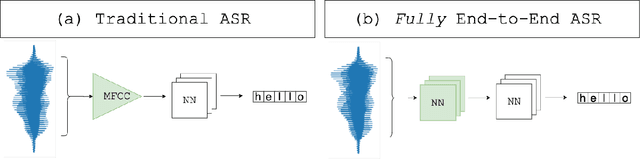

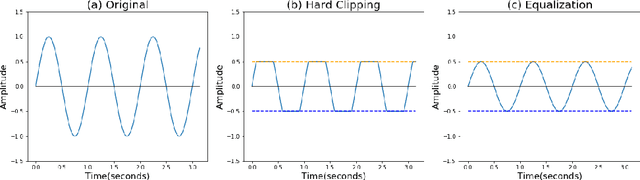
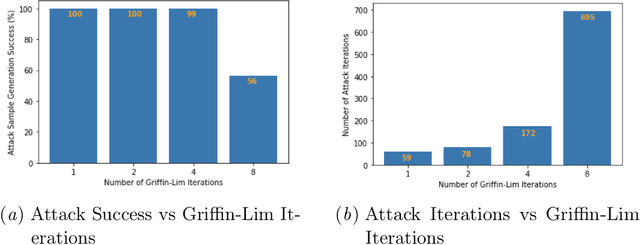
Automatic Speech Recognition (ASR) systems convert speech into text and can be placed into two broad categories: traditional and fully end-to-end. Both types have been shown to be vulnerable to adversarial audio examples that sound benign to the human ear but force the ASR to produce malicious transcriptions. Of these attacks, only the "psychoacoustic" attacks can create examples with relatively imperceptible perturbations, as they leverage the knowledge of the human auditory system. Unfortunately, existing psychoacoustic attacks can only be applied against traditional models, and are obsolete against the newer, fully end-to-end ASRs. In this paper, we propose an equalization-based psychoacoustic attack that can exploit both traditional and fully end-to-end ASRs. We successfully demonstrate our attack against real-world ASRs that include DeepSpeech and Wav2Letter. Moreover, we employ a user study to verify that our method creates low audible distortion. Specifically, 80 of the 100 participants voted in favor of all our attack audio samples as less noisier than the existing state-of-the-art attack. Through this, we demonstrate both types of existing ASR pipelines can be exploited with minimum degradation to attack audio quality.
Practical Hidden Voice Attacks against Speech and Speaker Recognition Systems
Mar 18, 2019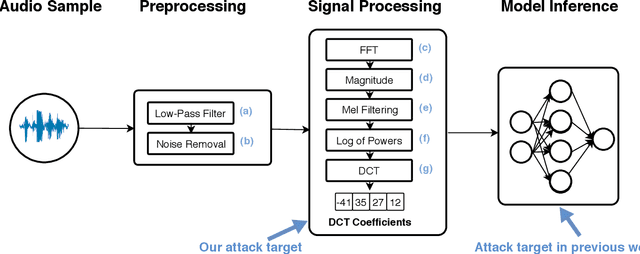
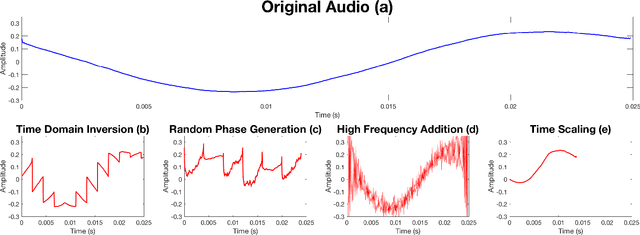
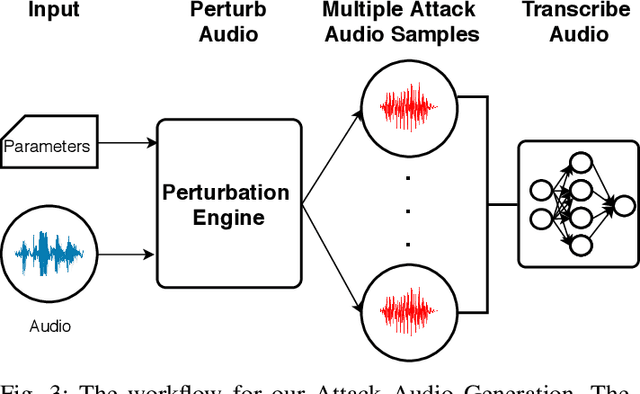
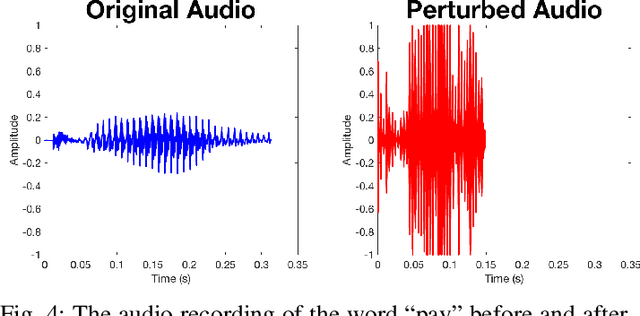
Voice Processing Systems (VPSes), now widely deployed, have been made significantly more accurate through the application of recent advances in machine learning. However, adversarial machine learning has similarly advanced and has been used to demonstrate that VPSes are vulnerable to the injection of hidden commands - audio obscured by noise that is correctly recognized by a VPS but not by human beings. Such attacks, though, are often highly dependent on white-box knowledge of a specific machine learning model and limited to specific microphones and speakers, making their use across different acoustic hardware platforms (and thus their practicality) limited. In this paper, we break these dependencies and make hidden command attacks more practical through model-agnostic (blackbox) attacks, which exploit knowledge of the signal processing algorithms commonly used by VPSes to generate the data fed into machine learning systems. Specifically, we exploit the fact that multiple source audio samples have similar feature vectors when transformed by acoustic feature extraction algorithms (e.g., FFTs). We develop four classes of perturbations that create unintelligible audio and test them against 12 machine learning models, including 7 proprietary models (e.g., Google Speech API, Bing Speech API, IBM Speech API, Azure Speaker API, etc), and demonstrate successful attacks against all targets. Moreover, we successfully use our maliciously generated audio samples in multiple hardware configurations, demonstrating effectiveness across both models and real systems. In so doing, we demonstrate that domain-specific knowledge of audio signal processing represents a practical means of generating successful hidden voice command attacks.