 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePitch Imperfect: Detecting Audio Deepfakes Through Acoustic Prosodic Analysis
Feb 20, 2025



Audio deepfakes are increasingly in-differentiable from organic speech, often fooling both authentication systems and human listeners. While many techniques use low-level audio features or optimization black-box model training, focusing on the features that humans use to recognize speech will likely be a more long-term robust approach to detection. We explore the use of prosody, or the high-level linguistic features of human speech (e.g., pitch, intonation, jitter) as a more foundational means of detecting audio deepfakes. We develop a detector based on six classical prosodic features and demonstrate that our model performs as well as other baseline models used by the community to detect audio deepfakes with an accuracy of 93% and an EER of 24.7%. More importantly, we demonstrate the benefits of using a linguistic features-based approach over existing models by applying an adaptive adversary using an $L_{\infty}$ norm attack against the detectors and using attention mechanisms in our training for explainability. We show that we can explain the prosodic features that have highest impact on the model's decision (Jitter, Shimmer and Mean Fundamental Frequency) and that other models are extremely susceptible to simple $L_{\infty}$ norm attacks (99.3% relative degradation in accuracy). While overall performance may be similar, we illustrate the robustness and explainability benefits to a prosody feature approach to audio deepfake detection.
Every Breath You Don't Take: Deepfake Speech Detection Using Breath
Apr 26, 2024



Deepfake speech represents a real and growing threat to systems and society. Many detectors have been created to aid in defense against speech deepfakes. While these detectors implement myriad methodologies, many rely on low-level fragments of the speech generation process. We hypothesize that breath, a higher-level part of speech, is a key component of natural speech and thus improper generation in deepfake speech is a performant discriminator. To evaluate this, we create a breath detector and leverage this against a custom dataset of online news article audio to discriminate between real/deepfake speech. Additionally, we make this custom dataset publicly available to facilitate comparison for future work. Applying our simple breath detector as a deepfake speech discriminator on in-the-wild samples allows for accurate classification (perfect 1.0 AUPRC and 0.0 EER on test data) across 33.6 hours of audio. We compare our model with the state-of-the-art SSL-wav2vec model and show that this complex deep learning model completely fails to classify the same in-the-wild samples (0.72 AUPRC and 0.99 EER).
SoK: The Faults in our ASRs: An Overview of Attacks against Automatic Speech Recognition and Speaker Identification Systems
Jul 21, 2020
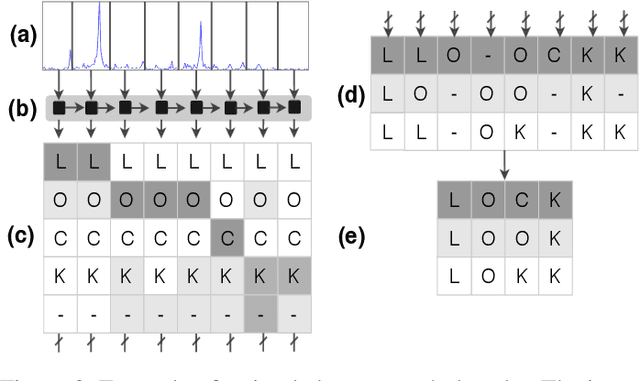
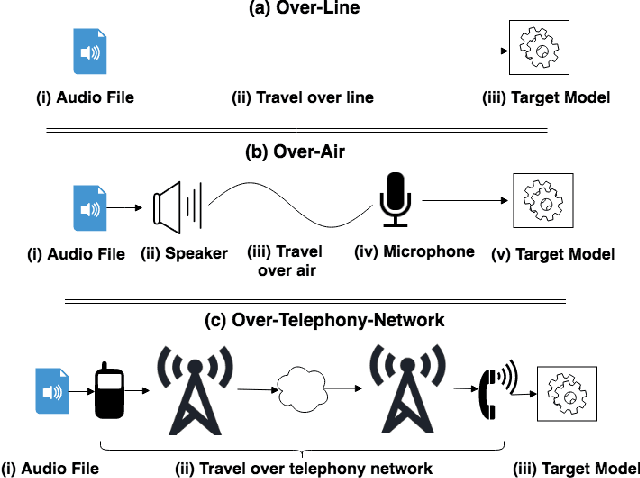
Speech and speaker recognition systems are employed in a variety of applications, from personal assistants to telephony surveillance and biometric authentication. The wide deployment of these systems has been made possible by the improved accuracy in neural networks. Like other systems based on neural networks, recent research has demonstrated that speech and speaker recognition systems are vulnerable to attacks using manipulated inputs. However, as we demonstrate in this paper, the end-to-end architecture of speech and speaker systems and the nature of their inputs make attacks and defenses against them substantially different than those in the image space. We demonstrate this first by systematizing existing research in this space and providing a taxonomy through which the community can evaluate future work. We then demonstrate experimentally that attacks against these models almost universally fail to transfer. In so doing, we argue that substantial additional work is required to provide adequate mitigations in this space.
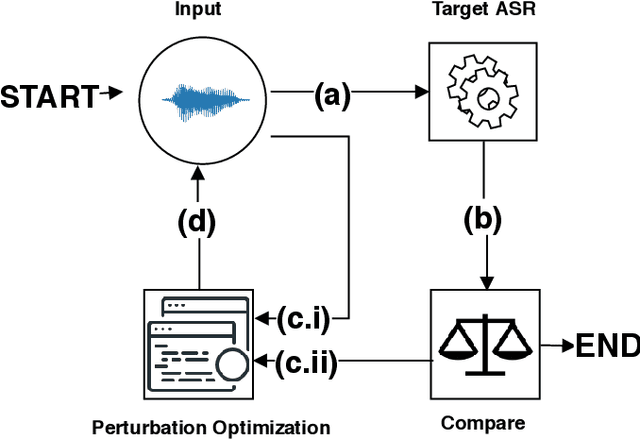
Hear "No Evil", See "Kenansville": Efficient and Transferable Black-Box Attacks on Speech Recognition and Voice Identification Systems
Oct 11, 2019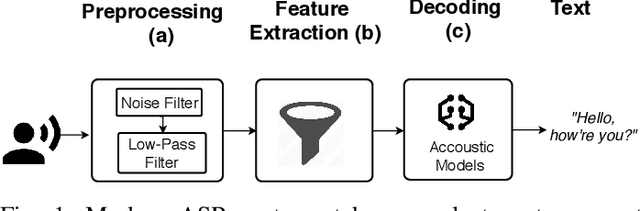
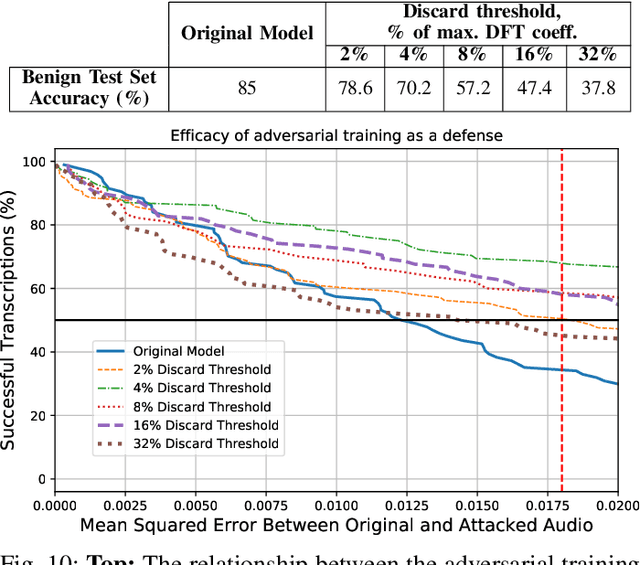
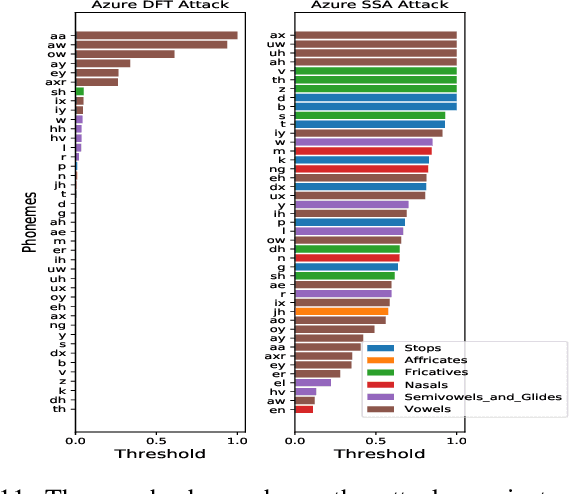
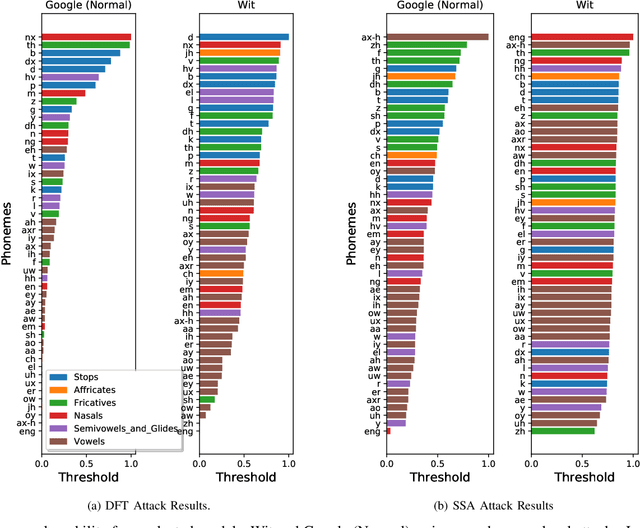
Automatic speech recognition and voice identification systems are being deployed in a wide array of applications, from providing control mechanisms to devices lacking traditional interfaces, to the automatic transcription of conversations and authentication of users. Many of these applications have significant security and privacy considerations. We develop attacks that force mistranscription and misidentification in state of the art systems, with minimal impact on human comprehension. Processing pipelines for modern systems are comprised of signal preprocessing and feature extraction steps, whose output is fed to a machine-learned model. Prior work has focused on the models, using white-box knowledge to tailor model-specific attacks. We focus on the pipeline stages before the models, which (unlike the models) are quite similar across systems. As such, our attacks are black-box and transferable, and demonstrably achieve mistranscription and misidentification rates as high as 100% by modifying only a few frames of audio. We perform a study via Amazon Mechanical Turk demonstrating that there is no statistically significant difference between human perception of regular and perturbed audio. Our findings suggest that models may learn aspects of speech that are generally not perceived by human subjects, but that are crucial for model accuracy. We also find that certain English language phonemes (in particular, vowels) are significantly more susceptible to our attack. We show that the attacks are effective when mounted over cellular networks, where signals are subject to degradation due to transcoding, jitter, and packet loss.