 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFoundation Models and Adaptive Feature Selection: A Synergistic Approach to Video Question Answering
Dec 12, 2024
This paper tackles the intricate challenge of video question-answering (VideoQA). Despite notable progress, current methods fall short of effectively integrating questions with video frames and semantic object-level abstractions to create question-aware video representations. We introduce Local-Global Question Aware Video Embedding (LGQAVE), which incorporates three major innovations to integrate multi-modal knowledge better and emphasize semantic visual concepts relevant to specific questions. LGQAVE moves beyond traditional ad-hoc frame sampling by utilizing a cross-attention mechanism that precisely identifies the most relevant frames concerning the questions. It captures the dynamics of objects within these frames using distinct graphs, grounding them in question semantics with the miniGPT model. These graphs are processed by a question-aware dynamic graph transformer (Q-DGT), which refines the outputs to develop nuanced global and local video representations. An additional cross-attention module integrates these local and global embeddings to generate the final video embeddings, which a language model uses to generate answers. Extensive evaluations across multiple benchmarks demonstrate that LGQAVE significantly outperforms existing models in delivering accurate multi-choice and open-ended answers.
Challenges and Opportunities for Computer Vision in Real-life Soccer Analytics
Apr 13, 2020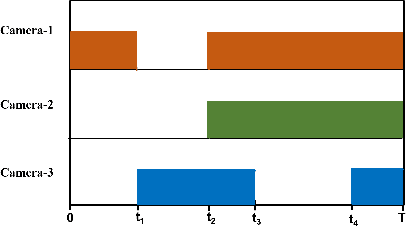

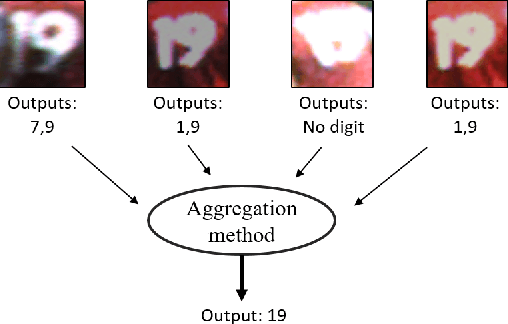
In this paper, we explore some of the applications of computer vision to sports analytics. Sport analytics deals with understanding and discovering patterns from a corpus of sports data. Analysing such data provides important performance metrics for the players, for instance in soccer matches, that could be useful for estimating their fitness and strengths. Team level statistics can also be estimated from such analysis. This paper mainly focuses on some the challenges and opportunities presented by sport video analysis in computer vision. Specifically, we use our multi-camera setup as a framework to discuss some of the real-life challenges for machine learning algorithms.
Multi-timescale Trajectory Prediction for Abnormal Human Activity Detection
Aug 12, 2019

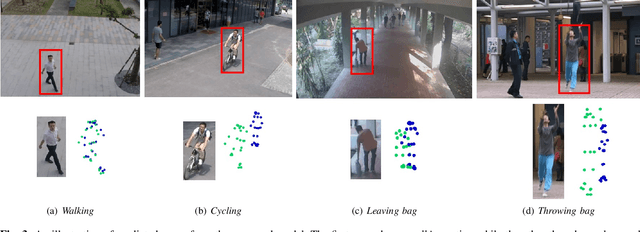

A classical approach to abnormal activity detection is to learn a representation for normal activities from the training data and then use this learned representation to detect abnormal activities while testing. Typically, the methods based on this approach operate at a fixed timescale - either a single time-instant (eg. frame-based) or a constant time duration (eg. video-clip based). But human abnormal activities can take place at different timescales. For example, jumping is a short term anomaly and loitering is a long term anomaly in a surveillance scenario. A single and pre-defined timescale is not enough to capture the wide range of anomalies occurring with different time duration. In this paper, we propose a multi-timescale model to capture the temporal dynamics at different timescales. In particular, the proposed model makes future and past predictions at different timescales for a given input pose trajectory. The model is multi-layered where intermediate layers are responsible to generate predictions corresponding to different timescales. These predictions are combined to detect abnormal activities. In addition, we also introduce an abnormal activity data-set for research use that contains 4,83,566 annotated frames. Data-set will be made available at https://rodrigues-royston.github.io/Multi-timescale_Trajectory_Prediction/ Our experiments show that the proposed model can capture the anomalies of different time duration and outperforms existing methods.
Spatio-temporal interaction model for crowd video analysis
Oct 31, 2017

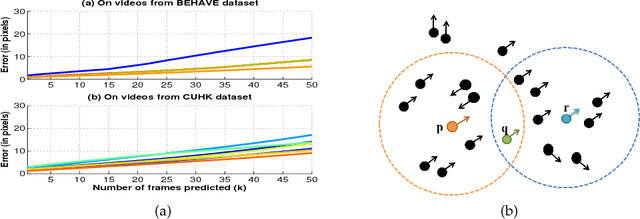

We present an unsupervised approach to analyze crowd at various levels of granularity $-$ individual, group and collective. We also propose a motion model to represent the collective motion of the crowd. The model captures the spatio-temporal interaction pattern of the crowd from the trajectory data captured over a time period. Furthermore, we also propose an effective group detection algorithm that utilizes the eigenvectors of the interaction matrix of the model. We also show that the eigenvalues of the interaction matrix characterize various group activities such as being stationary, walking, splitting and approaching. The algorithm is also extended trivially to recognize individual activity. Finally, we discover the overall crowd behavior by classifying a crowd video in one of the eight categories. Since the crowd behavior is determined by its constituent groups, we demonstrate the usefulness of group level features during classification. Extensive experimentation on various datasets demonstrates a superlative performance of our algorithms over the state-of-the-art methods.
An Integrated Approach to Crowd Video Analysis: From Tracking to Multi-level Activity Recognition
Oct 30, 2017

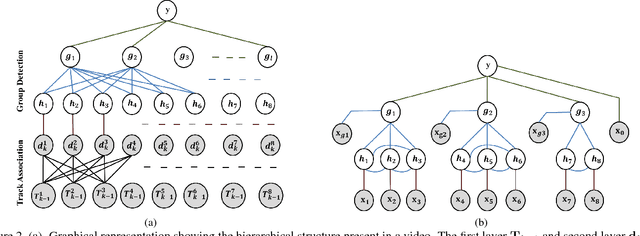

We present an integrated framework for simultaneous tracking, group detection and multi-level activity recognition in crowd videos. Instead of solving these problems independently and sequentially, we solve them together in a unified framework to utilize the strong correlation that exists among individual motion, groups, and activities. We explore the hierarchical structure hidden in the video that connects individuals over time to produce tracks, connects individuals to form groups and also connects groups together to form a crowd. We show that estimation of this hidden structure corresponds to track association and group detection. We estimate this hidden structure under a linear programming formulation. The obtained graphical representation is further explored to recognize the node values that corresponds to multi-level activity recognition. This problem is solved under a structured SVM framework. The results on publicly available dataset show very competitive performance at all levels of granularity with the state-of-the-art batch processing methods despite the proposed technique being an online (causal) one.