 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVisual Question Answering in Remote Sensing with Cross-Attention and Multimodal Information Bottleneck
Jun 25, 2023



In this research, we deal with the problem of visual question answering (VQA) in remote sensing. While remotely sensed images contain information significant for the task of identification and object detection, they pose a great challenge in their processing because of high dimensionality, volume and redundancy. Furthermore, processing image information jointly with language features adds additional constraints, such as mapping the corresponding image and language features. To handle this problem, we propose a cross attention based approach combined with information maximization. The CNN-LSTM based cross-attention highlights the information in the image and language modalities and establishes a connection between the two, while information maximization learns a low dimensional bottleneck layer, that has all the relevant information required to carry out the VQA task. We evaluate our method on two VQA remote sensing datasets of different resolutions. For the high resolution dataset, we achieve an overall accuracy of 79.11% and 73.87% for the two test sets while for the low resolution dataset, we achieve an overall accuracy of 85.98%.
Robust Direction-of-Arrival Estimation using Array Feedback Beamforming in Low SNR Scenarios
Mar 16, 2023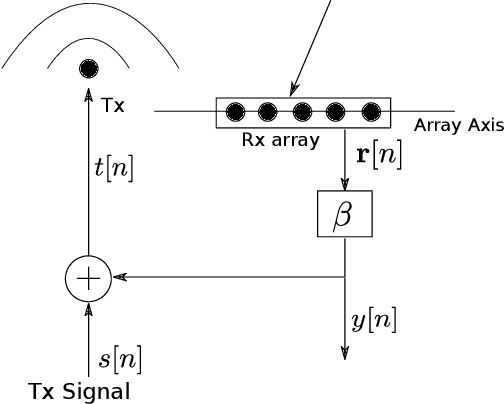
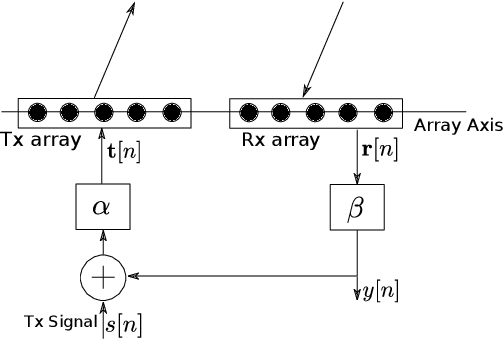
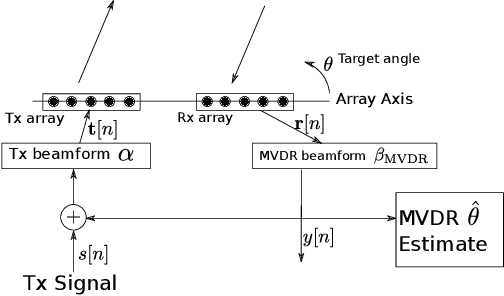
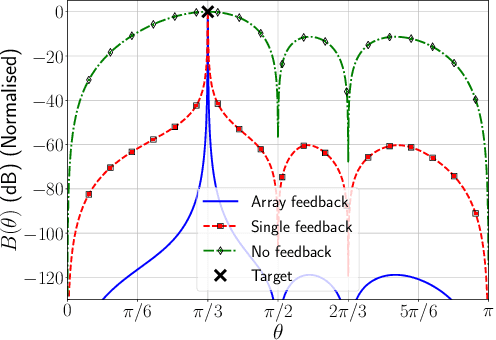
A new spatial IIR beamformer based direction-of-arrival (DoA) estimation method is proposed in this paper. We propose a retransmission based spatial feedback method for an array of transmit and receive antennas that improves the performance parameters of a beamformer viz. half-power beamwidth (HPBW), side-lobe suppression, and directivity. Through quantitative comparison we show that our approach outperforms the previous feedback beamforming approach with single transmit antenna, and the conventional beamformer. We then incorporate a retransmission based minimum variance distortionless response (MVDR) beamformer with the feedback beamforming setup. We propose two approaches and show that one approach is superior in terms of lower estimation error, and use that as DoA estimation method. We then compare this approach with Multiple Signal Classification (MUSIC) and Estimation of Parameters using Rotation Invariant Technique (ESPRIT) methods. While these previous methods perform poorly in low signal-to-noise-ratio (SNR) regime, we show that our method outperforms both at very low SNR levels. The results show that at SNR levels of -80 db to -10 db, the error is 80% less compared to that of MUSIC and ESPRIT.
Lattice All-Pass Filter based Precoder Adaptation for MIMO Wireless Channels
Feb 22, 2023Modern 5G communication systems employ multiple-input multiple-output (MIMO) in conjunction with orthogonal frequency division multiplexing (OFDM) to enhance data rates, particularly for wideband millimetre wave (mmW) applications. Since these systems use a large number of subcarriers, feeding back the estimated precoder for even a subset of subcarriers from the receiver to the transmitter is prohibitive. Moreover, such frequency domain approaches also do not exploit the predominant line-of-sight component that is present in such channels to reduce feedback. In this work, we view the precoder in the time domain as a matrix all-pass filter, and model the discrete-time precoder filter using a matrix-lattice structure that aids in reducing the overall feedback while still maintaining the desired frequency-phase delay profile. This provides an efficient precoder representation across the subcarriers using fewer coefficients, and is amenable to tracking over time with much lower feedback than past approaches. Compared to frequency domain geodesic interpolation, Givens rotation based parameterisation, and the angle-delay domain approach that depends on approximate discrete-time representation, the proposed approach yields higher achievable rates with a much lower feedback burden. Via extensive simulations over mmW channel models, we confirm the effectiveness of our claims, and show that the proposed approach can reduce the feedback burden by up to 70%.
An Investigation of End-to-End Models for Robust Speech Recognition
Feb 11, 2021
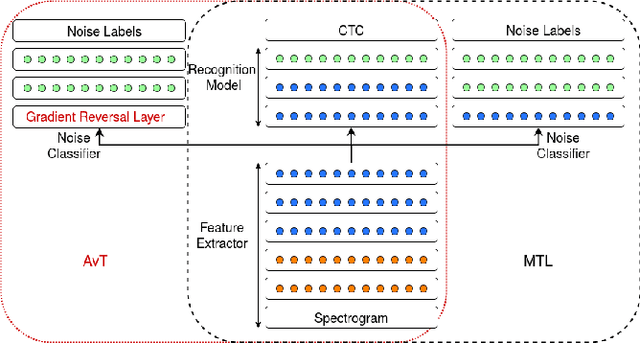


End-to-end models for robust automatic speech recognition (ASR) have not been sufficiently well-explored in prior work. With end-to-end models, one could choose to preprocess the input speech using speech enhancement techniques and train the model using enhanced speech. Another alternative is to pass the noisy speech as input and modify the model architecture to adapt to noisy speech. A systematic comparison of these two approaches for end-to-end robust ASR has not been attempted before. We address this gap and present a detailed comparison of speech enhancement-based techniques and three different model-based adaptation techniques covering data augmentation, multi-task learning, and adversarial learning for robust ASR. While adversarial learning is the best-performing technique on certain noise types, it comes at the cost of degrading clean speech WER. On other relatively stationary noise types, a new speech enhancement technique outperformed all the model-based adaptation techniques. This suggests that knowledge of the underlying noise type can meaningfully inform the choice of adaptation technique.
Directed Variational Cross-encoder Network for Few-shot Multi-image Co-segmentation
Oct 17, 2020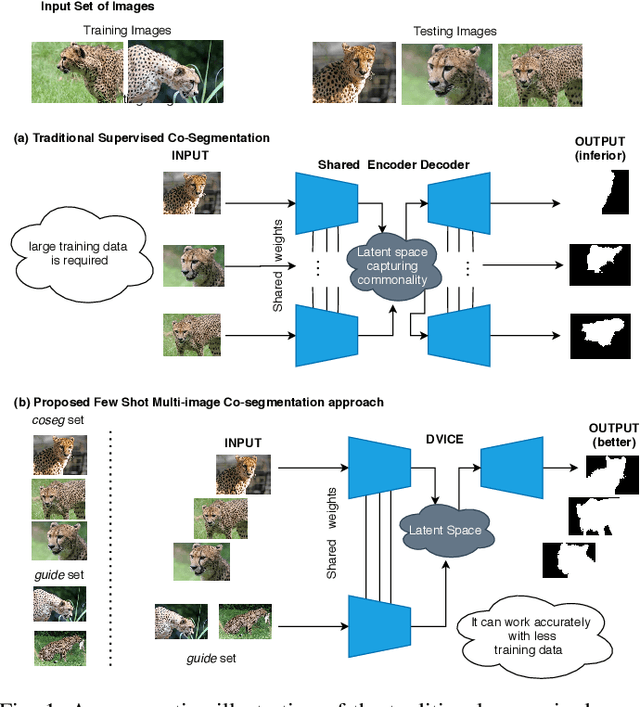
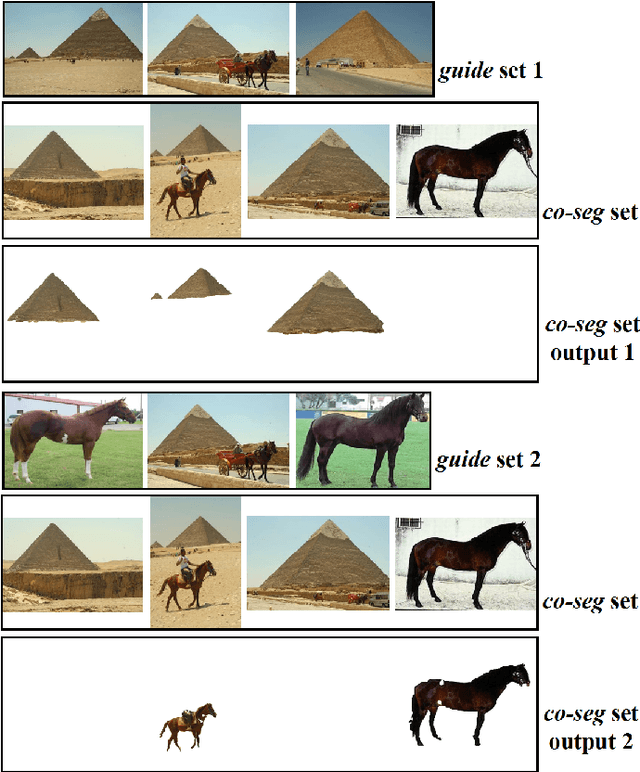
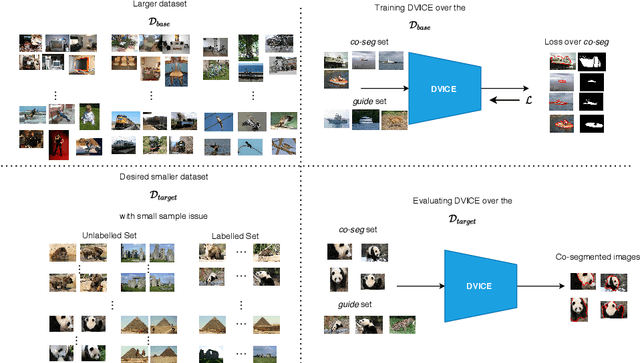
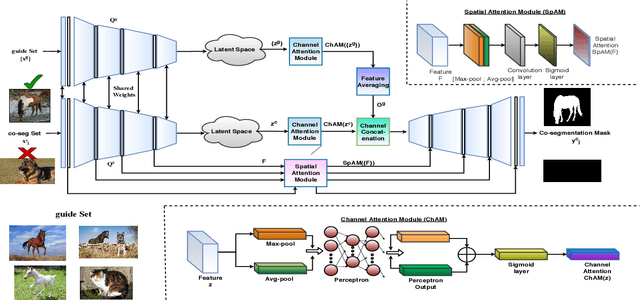
In this paper, we propose a novel framework for multi-image co-segmentation using class agnostic meta-learning strategy by generalizing to new classes given only a small number of training samples for each new class. We have developed a novel encoder-decoder network termed as DVICE (Directed Variational Inference Cross Encoder), which learns a continuous embedding space to ensure better similarity learning. We employ a combination of the proposed DVICE network and a novel few-shot learning approach to tackle the small sample size problem encountered in co-segmentation with small datasets like iCoseg and MSRC. Furthermore, the proposed framework does not use any semantic class labels and is entirely class agnostic. Through exhaustive experimentation over multiple datasets using only a small volume of training data, we have demonstrated that our approach outperforms all existing state-of-the-art techniques.
Distilling Spikes: Knowledge Distillation in Spiking Neural Networks
May 01, 2020

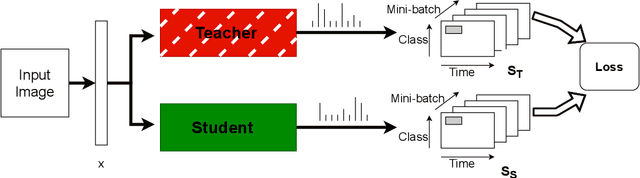

Spiking Neural Networks (SNN) are energy-efficient computing architectures that exchange spikes for processing information, unlike classical Artificial Neural Networks (ANN). Due to this, SNNs are better suited for real-life deployments. However, similar to ANNs, SNNs also benefit from deeper architectures to obtain improved performance. Furthermore, like the deep ANNs, the memory, compute and power requirements of SNNs also increase with model size, and model compression becomes a necessity. Knowledge distillation is a model compression technique that enables transferring the learning of a large machine learning model to a smaller model with minimal loss in performance. In this paper, we propose techniques for knowledge distillation in spiking neural networks for the task of image classification. We present ways to distill spikes from a larger SNN, also called the teacher network, to a smaller one, also called the student network, while minimally impacting the classification accuracy. We demonstrate the effectiveness of the proposed method with detailed experiments on three standard datasets while proposing novel distillation methodologies and loss functions. We also present a multi-stage knowledge distillation technique for SNNs using an intermediate network to obtain higher performance from the student network. Our approach is expected to open up new avenues for deploying high performing large SNN models on resource-constrained hardware platforms.
Multiple Kernel Fisher Discriminant Metric Learning for Person Re-identification
Oct 09, 2019
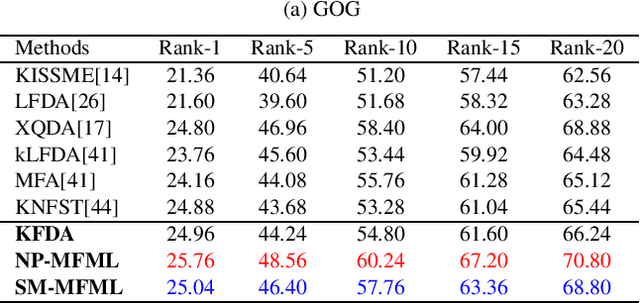
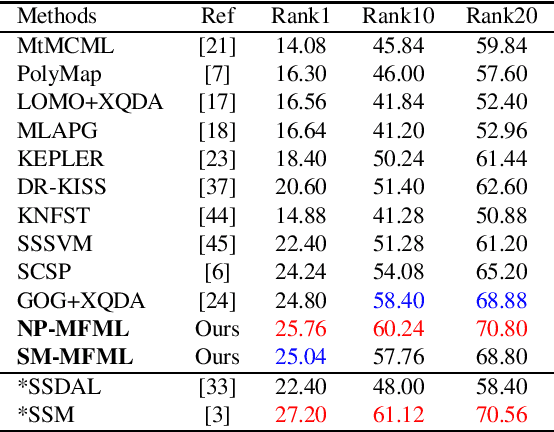

Person re-identification addresses the problem of matching pedestrian images across disjoint camera views. Design of feature descriptor and distance metric learning are the two fundamental tasks in person re-identification. In this paper, we propose a metric learning framework for person re-identification, where the discriminative metric space is learned using Kernel Fisher Discriminant Analysis (KFDA), to simultaneously maximize the inter-class variance as well as minimize the intra-class variance. We derive a Mahalanobis metric induced by KFDA and argue that KFDA is efficient to be applied for metric learning in person re-identification. We also show how the efficiency of KFDA in metric learning can be further enhanced for person re-identification by using two simple yet efficient multiple kernel learning methods. We conduct extensive experiments on three benchmark datasets for person re-identification and demonstrate that the proposed approaches have competitive performance with state-of-the-art methods.
Multi-timescale Trajectory Prediction for Abnormal Human Activity Detection
Aug 12, 2019

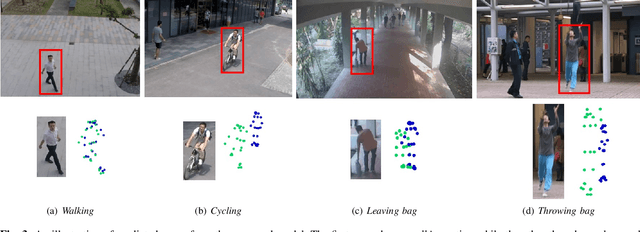

A classical approach to abnormal activity detection is to learn a representation for normal activities from the training data and then use this learned representation to detect abnormal activities while testing. Typically, the methods based on this approach operate at a fixed timescale - either a single time-instant (eg. frame-based) or a constant time duration (eg. video-clip based). But human abnormal activities can take place at different timescales. For example, jumping is a short term anomaly and loitering is a long term anomaly in a surveillance scenario. A single and pre-defined timescale is not enough to capture the wide range of anomalies occurring with different time duration. In this paper, we propose a multi-timescale model to capture the temporal dynamics at different timescales. In particular, the proposed model makes future and past predictions at different timescales for a given input pose trajectory. The model is multi-layered where intermediate layers are responsible to generate predictions corresponding to different timescales. These predictions are combined to detect abnormal activities. In addition, we also introduce an abnormal activity data-set for research use that contains 4,83,566 annotated frames. Data-set will be made available at https://rodrigues-royston.github.io/Multi-timescale_Trajectory_Prediction/ Our experiments show that the proposed model can capture the anomalies of different time duration and outperforms existing methods.