 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultiple Kernel Fisher Discriminant Metric Learning for Person Re-identification
Oct 09, 2019
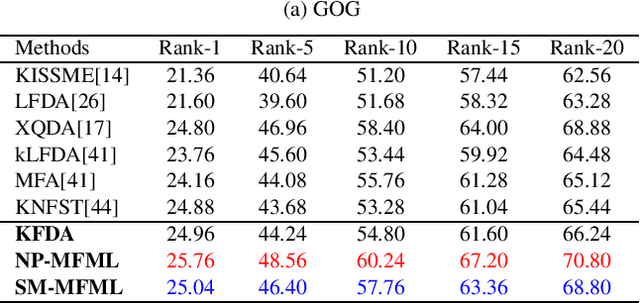
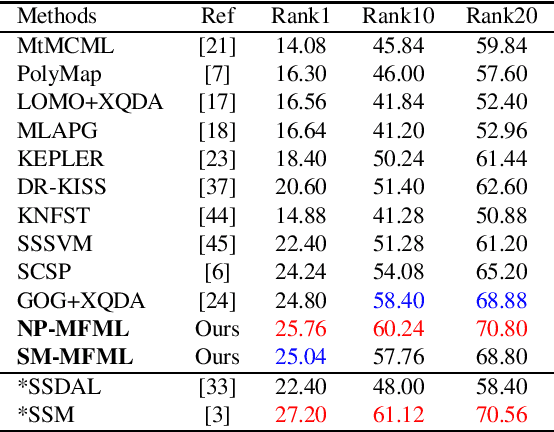

Person re-identification addresses the problem of matching pedestrian images across disjoint camera views. Design of feature descriptor and distance metric learning are the two fundamental tasks in person re-identification. In this paper, we propose a metric learning framework for person re-identification, where the discriminative metric space is learned using Kernel Fisher Discriminant Analysis (KFDA), to simultaneously maximize the inter-class variance as well as minimize the intra-class variance. We derive a Mahalanobis metric induced by KFDA and argue that KFDA is efficient to be applied for metric learning in person re-identification. We also show how the efficiency of KFDA in metric learning can be further enhanced for person re-identification by using two simple yet efficient multiple kernel learning methods. We conduct extensive experiments on three benchmark datasets for person re-identification and demonstrate that the proposed approaches have competitive performance with state-of-the-art methods.
A Semi-Supervised Maximum Margin Metric Learning Approach for Small Scale Person Re-identification
Oct 09, 2019
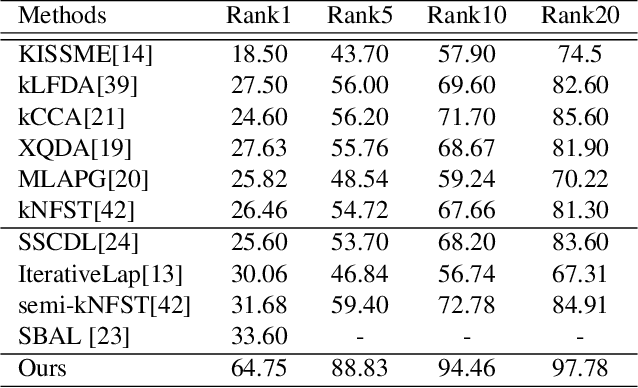
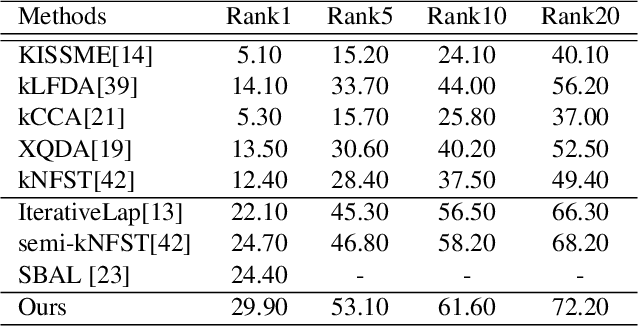
In video surveillance, person re-identification is the task of searching person images in non-overlapping cameras. Though supervised methods for person re-identification have attained impressive performance, obtaining large scale cross-view labeled training data is very expensive. However, unlabelled data is available in abundance. In this paper, we propose a semi-supervised metric learning approach that can utilize information in unlabelled data with the help of a few labelled training samples. We also address the small sample size problem that inherently occurs due to the few labeled training data. Our method learns a discriminative space where within class samples collapse to singular points, achieving the least within class variance, and then use a maximum margin criterion over a high dimensional kernel space to maximally separate the distinct class samples. A maximum margin criterion with two levels of high dimensional mappings to kernel space is used to obtain better cross-view discrimination of the identities. Cross-view affinity learning with reciprocal nearest neighbor constraints is used to mine new pseudo-classes from the unlabelled data and update the distance metric iteratively. We attain state-of-the-art performance on four challenging datasets with a large margin.
Cross-View Kernel Similarity Metric Learning Using Pairwise Constraints for Person Re-identification
Sep 25, 2019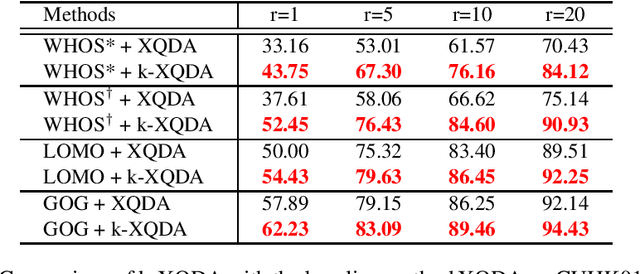
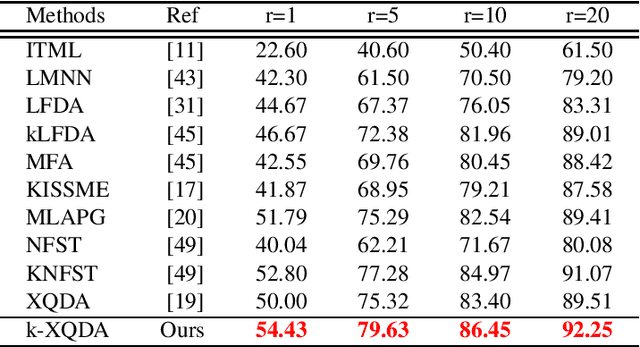

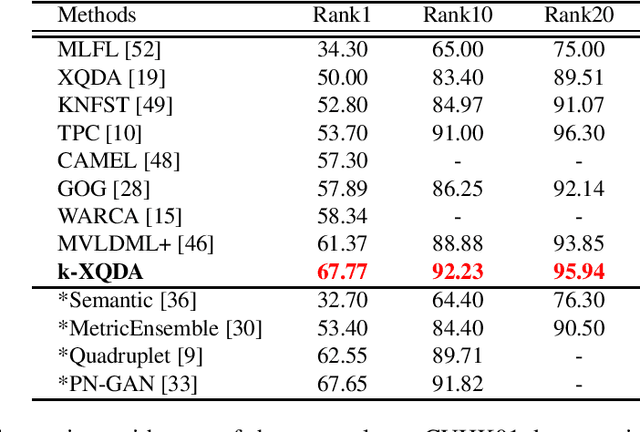
Person re-identification is the task of matching pedestrian images across non-overlapping cameras. In this paper, we propose a non-linear cross-view similarity metric learning for handling small size training data in practical re-ID systems. The method employs non-linear mappings combined with cross-view discriminative subspace learning and cross-view distance metric learning based on pairwise similarity constraints. It is a natural extension of XQDA from linear to non-linear mappings using kernels, and learns non-linear transformations for efficiently handling complex non-linearity of person appearance across camera views. Importantly, the proposed method is very computationally efficient. Extensive experiments on four challenging datasets shows that our method attains competitive performance against state-of-the-art methods.
Maximum Margin Metric Learning Over Discriminative Nullspace for Person Re-identification
Jul 28, 2018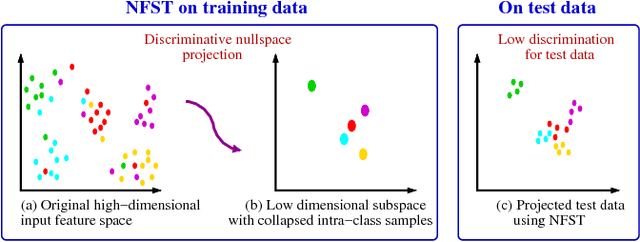
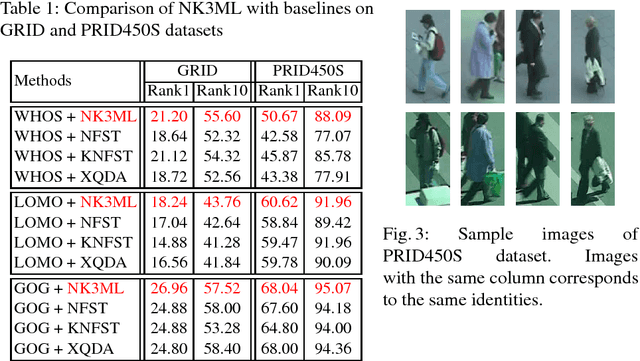
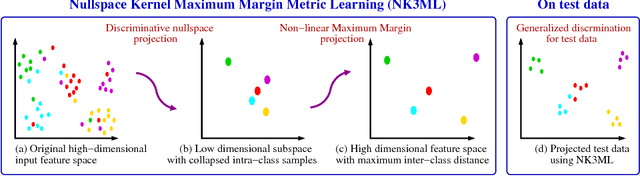
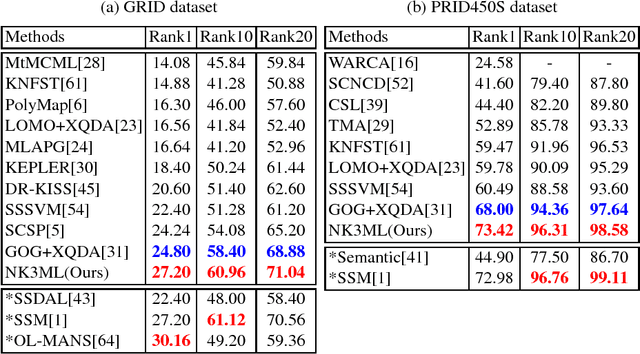
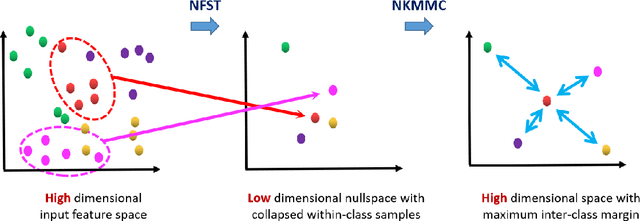
In this paper we propose a novel metric learning framework called Nullspace Kernel Maximum Margin Metric Learning (NK3ML) which efficiently addresses the small sample size (SSS) problem inherent in person re-identification and offers a significant performance gain over existing state-of-the-art methods. Taking advantage of the very high dimensionality of the feature space, the metric is learned using a maximum margin criterion (MMC) over a discriminative nullspace where all training sample points of a given class map onto a single point, minimizing the within class scatter. A kernel version of MMC is used to obtain a better between class separation. Extensive experiments on four challenging benchmark datasets for person re-identification demonstrate that the proposed algorithm outperforms all existing methods. We obtain 99.8% rank-1 accuracy on the most widely accepted and challenging dataset VIPeR, compared to the previous state of the art being only 63.92%.