 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Semi-Supervised Maximum Margin Metric Learning Approach for Small Scale Person Re-identification
Paper and Code
Oct 09, 2019
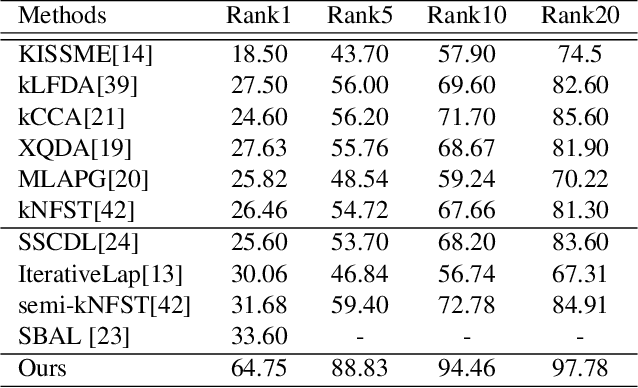
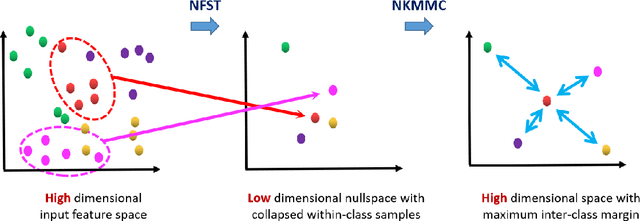
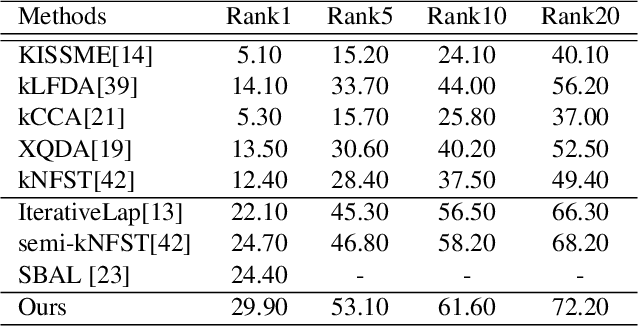
In video surveillance, person re-identification is the task of searching person images in non-overlapping cameras. Though supervised methods for person re-identification have attained impressive performance, obtaining large scale cross-view labeled training data is very expensive. However, unlabelled data is available in abundance. In this paper, we propose a semi-supervised metric learning approach that can utilize information in unlabelled data with the help of a few labelled training samples. We also address the small sample size problem that inherently occurs due to the few labeled training data. Our method learns a discriminative space where within class samples collapse to singular points, achieving the least within class variance, and then use a maximum margin criterion over a high dimensional kernel space to maximally separate the distinct class samples. A maximum margin criterion with two levels of high dimensional mappings to kernel space is used to obtain better cross-view discrimination of the identities. Cross-view affinity learning with reciprocal nearest neighbor constraints is used to mine new pseudo-classes from the unlabelled data and update the distance metric iteratively. We attain state-of-the-art performance on four challenging datasets with a large margin.