 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLecture Video Visual Objects (LVVO) Dataset: A Benchmark for Visual Object Detection in Educational Videos
Jun 16, 2025We introduce the Lecture Video Visual Objects (LVVO) dataset, a new benchmark for visual object detection in educational video content. The dataset consists of 4,000 frames extracted from 245 lecture videos spanning biology, computer science, and geosciences. A subset of 1,000 frames, referred to as LVVO_1k, has been manually annotated with bounding boxes for four visual categories: Table, Chart-Graph, Photographic-image, and Visual-illustration. Each frame was labeled independently by two annotators, resulting in an inter-annotator F1 score of 83.41%, indicating strong agreement. To ensure high-quality consensus annotations, a third expert reviewed and resolved all cases of disagreement through a conflict resolution process. To expand the dataset, a semi-supervised approach was employed to automatically annotate the remaining 3,000 frames, forming LVVO_3k. The complete dataset offers a valuable resource for developing and evaluating both supervised and semi-supervised methods for visual content detection in educational videos. The LVVO dataset is publicly available to support further research in this domain.
Visual Summarization of Lecture Video Segments for Enhanced Navigation
Jun 03, 2020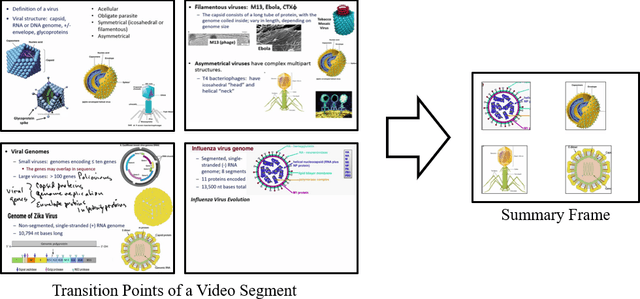
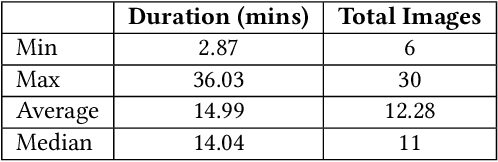
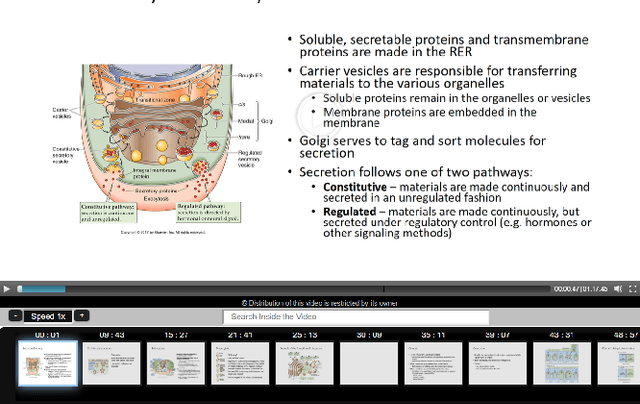
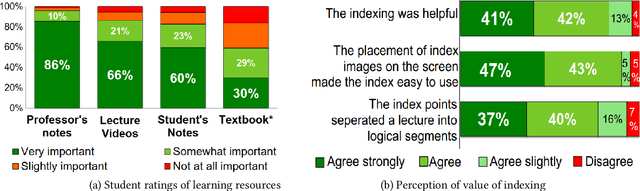
Lecture videos are an increasingly important learning resource for higher education. However, the challenge of quickly finding the content of interest in a lecture video is an important limitation of this format. This paper introduces visual summarization of lecture video segments to enhance navigation. A lecture video is divided into segments based on the frame-to-frame similarity of content. The user navigates the lecture video content by viewing a single frame visual and textual summary of each segment. The paper presents a novel methodology to generate the visual summary of a lecture video segment by computing similarities between images extracted from the segment and employing a graph-based algorithm to identify the subset of most representative images. The results from this research are integrated into a real-world lecture video management portal called Videopoints. To collect ground truth for evaluation, a survey was conducted where multiple users manually provided visual summaries for 40 lecture video segments. The users also stated whether any images were not selected for the summary because they were similar to other selected images. The graph based algorithm for identifying summary images achieves 78% precision and 72% F1-measure with frequently selected images as the ground truth, and 94% precision and 72% F1-measure with the union of all user selected images as the ground truth. For 98% of algorithm selected visual summary images, at least one user also selected that image for their summary or considered it similar to another image they selected. Over 65% of automatically generated summaries were rated as good or very good by the users on a 4-point scale from poor to very good. Overall, the results establish that the methodology introduced in this paper produces good quality visual summaries that are practically useful for lecture video navigation.
Person Re-identification with Hyperspectral Multi-Camera Systems --- A Pilot Study
Jul 15, 2016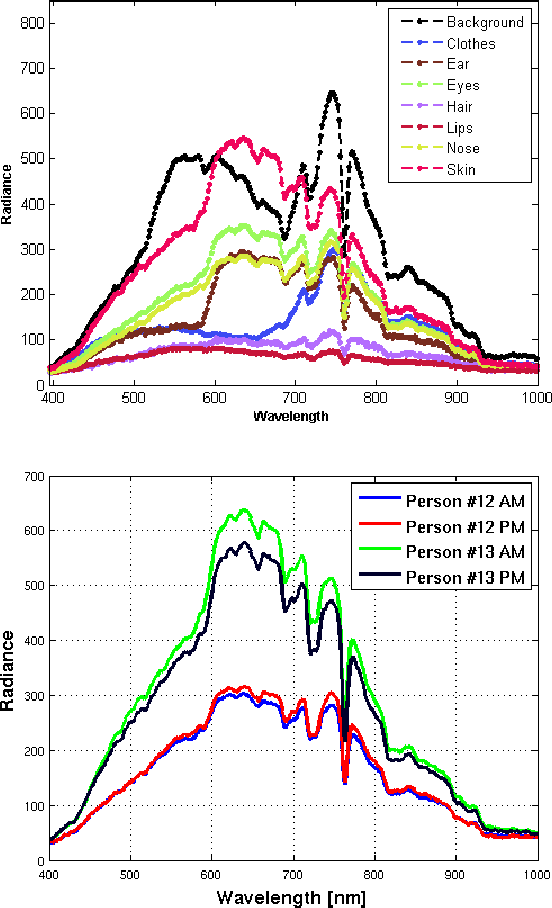
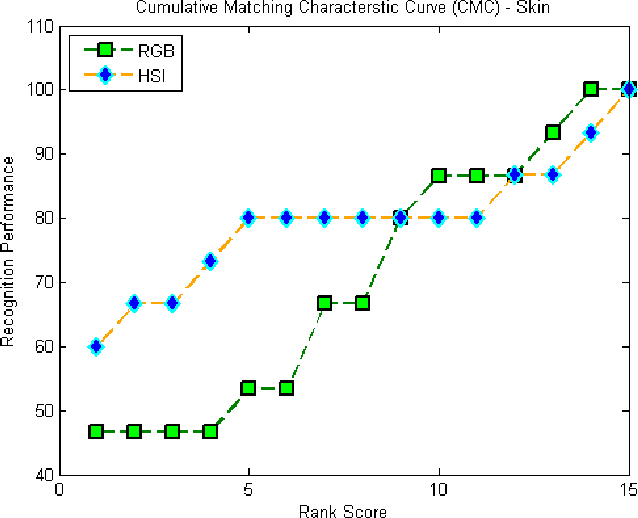
Person re-identification in a multi-camera environment is an important part of modern surveillance systems. Person re-identification from color images has been the focus of much active research, due to the numerous challenges posed with such analysis tasks, such as variations in illumination, pose and viewpoints. In this paper, we suggest that hyperspectral imagery has the potential to provide unique information that is expected to be beneficial for the re-identification task. Specifically, we assert that by accurately characterizing the unique spectral signature for each person's skin, hyperspectral imagery can provide very useful descriptors (e.g. spectral signatures from skin pixels) for re-identification. Towards this end, we acquired proof-of-concept hyperspectral re-identification data under challenging (practical) conditions from 15 people. Our results indicate that hyperspectral data result in a substantially enhanced re-identification performance compared to color (RGB) images, when using spectral signatures over skin as the feature descriptor.
A Semi-Automated Method for Object Segmentation in Infant's Egocentric Videos to Study Object Perception
Feb 08, 2016
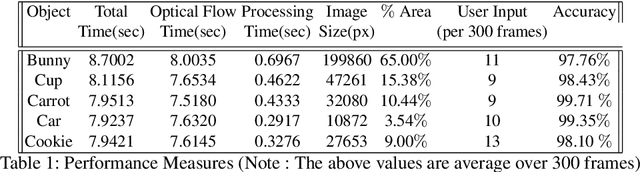
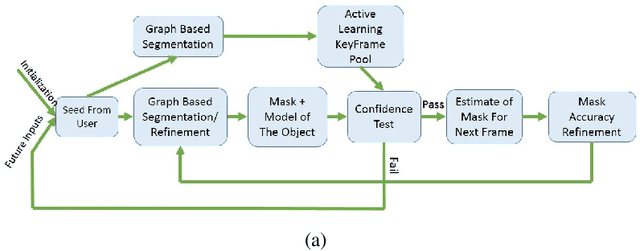
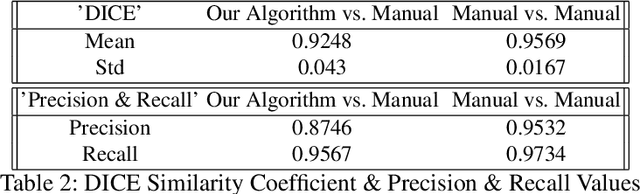
Object segmentation in infant's egocentric videos is a fundamental step in studying how children perceive objects in early stages of development. From the computer vision perspective, object segmentation in such videos pose quite a few challenges because the child's view is unfocused, often with large head movements, effecting in sudden changes in the child's point of view which leads to frequent change in object properties such as size, shape and illumination. In this paper, we develop a semi-automated, domain specific, method to address these concerns and facilitate the object annotation process for cognitive scientists allowing them to select and monitor the object under segmentation. The method starts with an annotation from the user of the desired object and employs graph cut segmentation and optical flow computation to predict the object mask for subsequent video frames automatically. To maintain accuracy, we use domain specific heuristic rules to re-initialize the program with new user input whenever object properties change dramatically. The evaluations demonstrate the high speed and accuracy of the presented method for object segmentation in voluminous egocentric videos. We apply the proposed method to investigate potential patterns in object distribution in child's view at progressive ages.