 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRevisiting Invariant Learning for Out-of-Domain Generalization on Multi-Site Mammogram Datasets
Mar 09, 2025



Despite significant progress in robust deep learning techniques for mammogram breast cancer classification, their reliability in real-world clinical development settings remains uncertain. The translation of these models to clinical practice faces challenges due to variations in medical centers, imaging protocols, and patient populations. To enhance their robustness, invariant learning methods have been proposed, prioritizing causal factors over misleading features. However, their effectiveness in clinical development and impact on mammogram classification require investigation. This paper reassesses the application of invariant learning for breast cancer risk estimation based on mammograms. Utilizing diverse multi-site public datasets, it represents the first study in this area. The objective is to evaluate invariant learning's benefits in developing robust models. Invariant learning methods, including Invariant Risk Minimization and Variance Risk Extrapolation, are compared quantitatively against Empirical Risk Minimization. Evaluation metrics include accuracy, average precision, and area under the curve. Additionally, interpretability is examined through class activation maps and visualization of learned representations. This research examines the advantages, limitations, and challenges of invariant learning for mammogram classification, guiding future studies to develop generalized methods for breast cancer prediction on whole mammograms in out-of-domain scenarios.
Reliable Text-to-SQL with Adaptive Abstention
Jan 18, 2025



Large language models (LLMs) have revolutionized natural language interfaces for databases, particularly in text-to-SQL conversion. However, current approaches often generate unreliable outputs when faced with ambiguity or insufficient context. We present Reliable Text-to-SQL (RTS), a novel framework that enhances query generation reliability by incorporating abstention and human-in-the-loop mechanisms. RTS focuses on the critical schema linking phase, which aims to identify the key database elements needed for generating SQL queries. It autonomously detects potential errors during the answer generation process and responds by either abstaining or engaging in user interaction. A vital component of RTS is the Branching Point Prediction (BPP) which utilizes statistical conformal techniques on the hidden layers of the LLM model for schema linking, providing probabilistic guarantees on schema linking accuracy. We validate our approach through comprehensive experiments on the BIRD benchmark, demonstrating significant improvements in robustness and reliability. Our findings highlight the potential of combining transparent-box LLMs with human-in-the-loop processes to create more robust natural language interfaces for databases. For the BIRD benchmark, our approach achieves near-perfect schema linking accuracy, autonomously involving a human when needed. Combined with query generation, we demonstrate that near-perfect schema linking and a small query generation model can almost match SOTA accuracy achieved with a model orders of magnitude larger than the one we use.
A Survey on Data Markets
Nov 09, 2024



Data is the new oil of the 21st century. The growing trend of trading data for greater welfare has led to the emergence of data markets. A data market is any mechanism whereby the exchange of data products including datasets and data derivatives takes place as a result of data buyers and data sellers being in contact with one another, either directly or through mediating agents. It serves as a coordinating mechanism by which several functions, including the pricing and the distribution of data as the most important ones, interact to make the value of data fully exploited and enhanced. In this article, we present a comprehensive survey of this important and emerging direction from the aspects of data search, data productization, data transaction, data pricing, revenue allocation as well as privacy, security, and trust issues. We also investigate the government policies and industry status of data markets across different countries and different domains. Finally, we identify the unresolved challenges and discuss possible future directions for the development of data markets.
Efficient Construction of Nonlinear Models overNormalized Data
Nov 23, 2020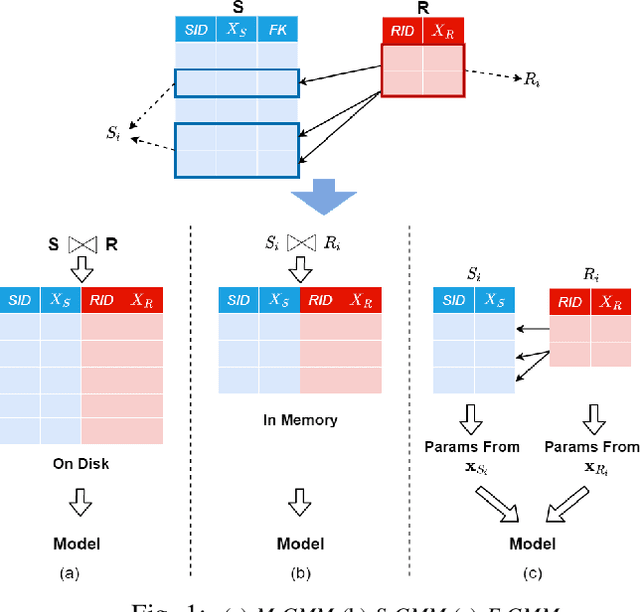

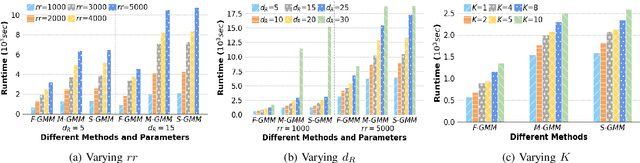
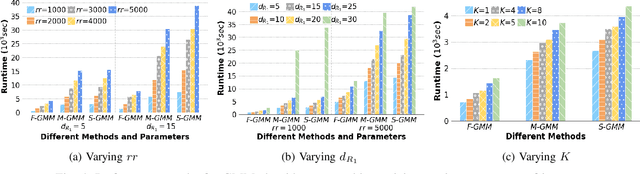
Machine Learning (ML) applications are proliferating in the enterprise. Relational data which are prevalent in enterprise applications are typically normalized; as a result, data has to be denormalized via primary/foreign-key joins to be provided as input to ML algorithms. In this paper, we study the implementation of popular nonlinear ML models, Gaussian Mixture Models (GMM) and Neural Networks (NN), over normalized data addressing both cases of binary and multi-way joins over normalized relations. For the case of GMM, we show how it is possible to decompose computation in a systematic way both for binary joins and for multi-way joins to construct mixture models. We demonstrate that by factoring the computation, one can conduct the training of the models much faster compared to other applicable approaches, without any loss in accuracy. For the case of NN, we propose algorithms to train the network taking normalized data as the input. Similarly, we present algorithms that can conduct the training of the network in a factorized way and offer performance advantages. The redundancy introduced by denormalization can be exploited for certain types of activation functions. However, we demonstrate that attempting to explore this redundancy is helpful up to a certain point; exploring redundancy at higher layers of the network will always result in increased costs and is not recommended. We present the results of a thorough experimental evaluation, varying several parameters of the input relations involved and demonstrate that our proposals for the training of GMM and NN yield drastic performance improvements typically starting at 100%, which become increasingly higher as parameters of the underlying data vary, without any loss in accuracy.
NLPMM: a Next Location Predictor with Markov Modeling
Mar 16, 2020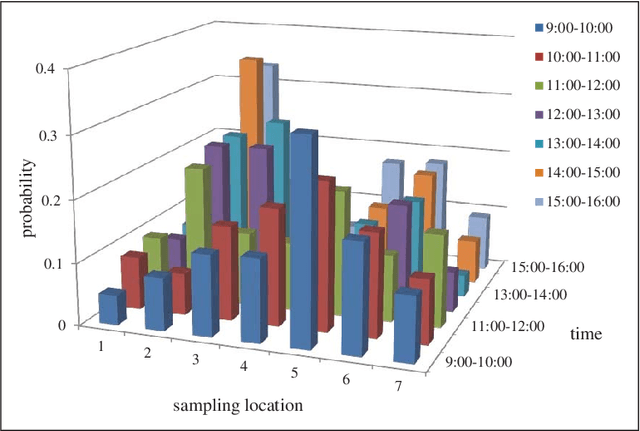

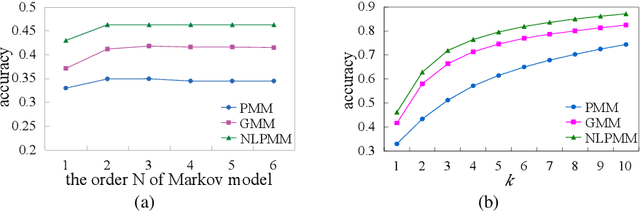
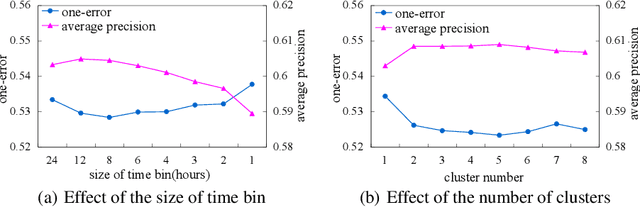
In this paper, we solve the problem of predicting the next locations of the moving objects with a historical dataset of trajectories. We present a Next Location Predictor with Markov Modeling (NLPMM) which has the following advantages: (1) it considers both individual and collective movement patterns in making prediction, (2) it is effective even when the trajectory data is sparse, (3) it considers the time factor and builds models that are suited to different time periods. We have conducted extensive experiments in a real dataset, and the results demonstrate the superiority of NLPMM over existing methods.
PCNN: Deep Convolutional Networks for Short-term Traffic Congestion Prediction
Mar 16, 2020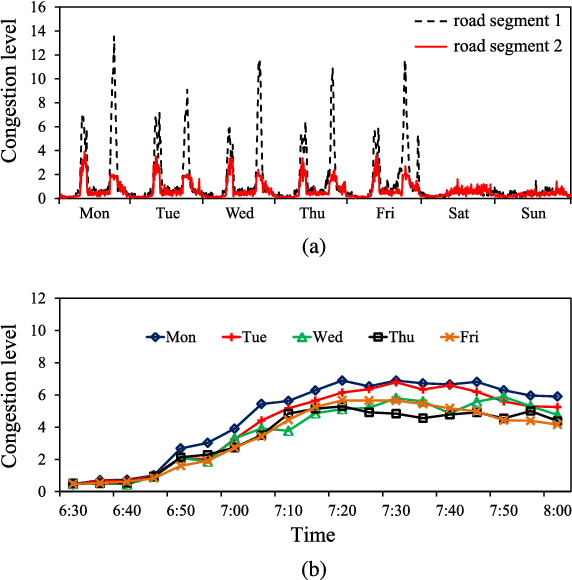
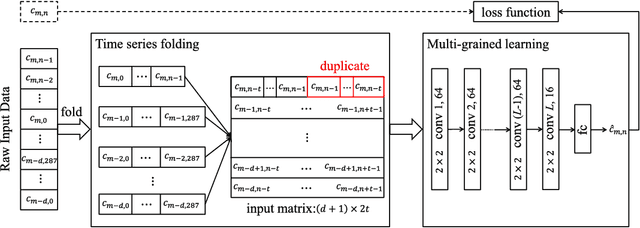
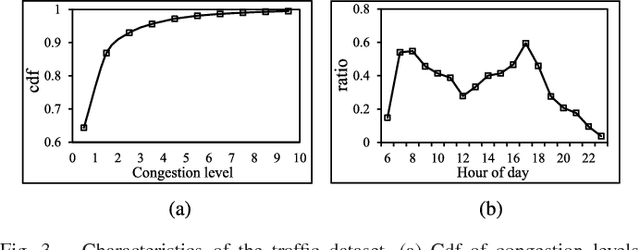
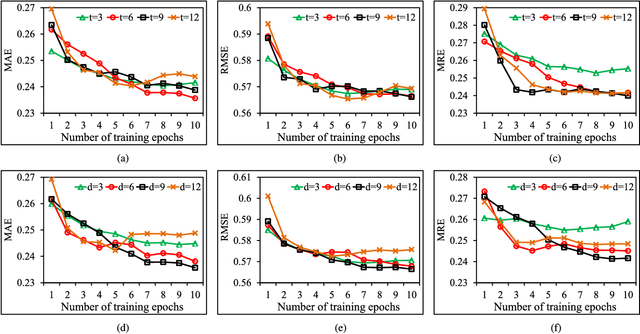
Traffic problems have seriously affected people's life quality and urban development, and forecasting the short-term traffic congestion is of great importance to both individuals and governments. However, understanding and modeling the traffic conditions can be extremely difficult, and our observations from real traffic data reveal that (1) similar traffic congestion patterns exist in the neighboring time slots and on consecutive workdays; (2) the levels of traffic congestion have clear multiscale properties. To capture these characteristics, we propose a novel method named PCNN based on deep Convolutional Neural Network, modeling Periodic traffic data for short-term traffic congestion prediction. PCNN has two pivotal procedures: time series folding and multi-grained learning. It first temporally folds the time series and constructs a two-dimensional matrix as the network input, such that both the real-time traffic conditions and past traffic patterns are well considered; then with a series of convolutions over the input matrix, it is able to model the local temporal dependency and multiscale traffic patterns. In particular, the global trend of congestion can be addressed at the macroscale; whereas more details and variations of the congestion can be captured at the microscale. Experimental results on a real-world urban traffic dataset confirm that folding time series data into a two-dimensional matrix is effective and PCNN outperforms the baselines significantly for the task of short-term congestion prediction.
MPE: A Mobility Pattern Embedding Model for Predicting Next Locations
Mar 16, 2020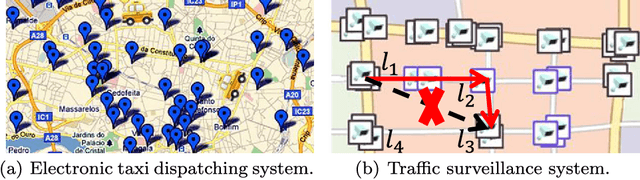
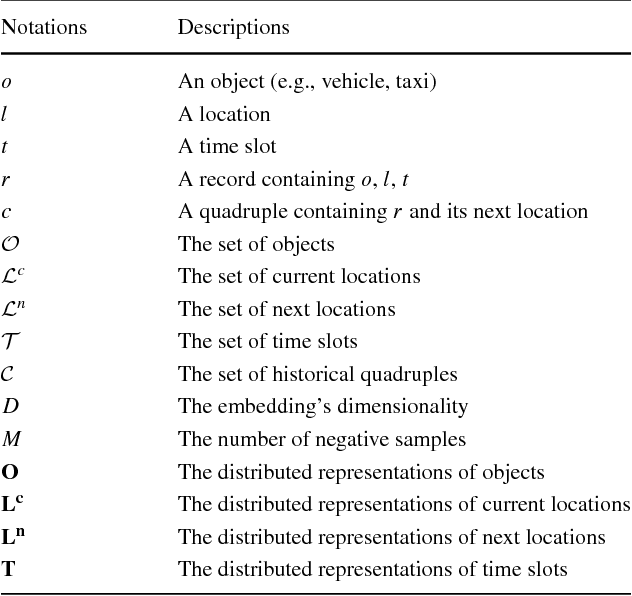
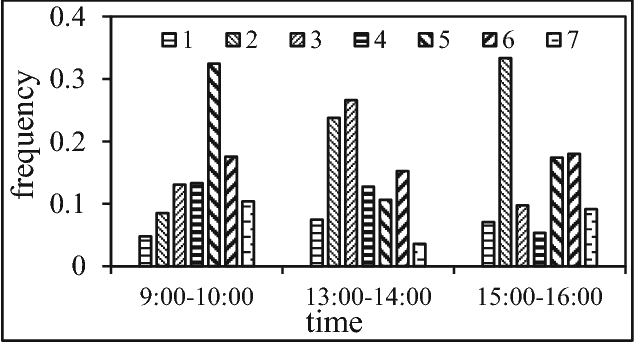
The wide spread use of positioning and photographing devices gives rise to a deluge of traffic trajectory data (e.g., vehicle passage records and taxi trajectory data), with each record having at least three attributes: object ID, location ID, and time-stamp. In this paper, we propose a novel mobility pattern embedding model called MPE to shed the light on people's mobility patterns in traffic trajectory data from multiple aspects, including sequential, personal, and temporal factors. MPE has two salient features: (1) it is capable of casting various types of information (object, location and time) to an integrated low-dimensional latent space; (2) it considers the effect of ``phantom transitions'' arising from road networks in traffic trajectory data. This embedding model opens the door to a wide range of applications such as next location prediction and visualization. Experimental results on two real-world datasets show that MPE is effective and outperforms the state-of-the-art methods significantly in a variety of tasks.
TTDM: A Travel Time Difference Model for Next Location Prediction
Mar 16, 2020
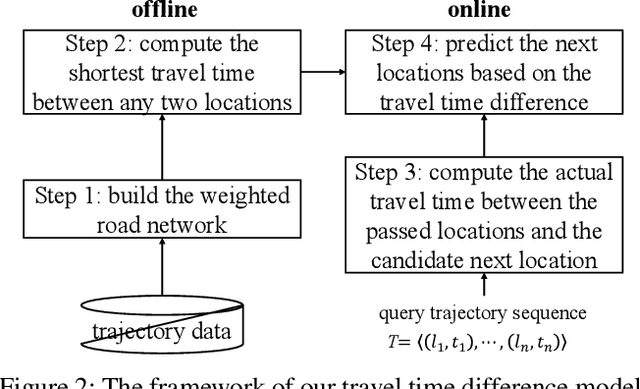

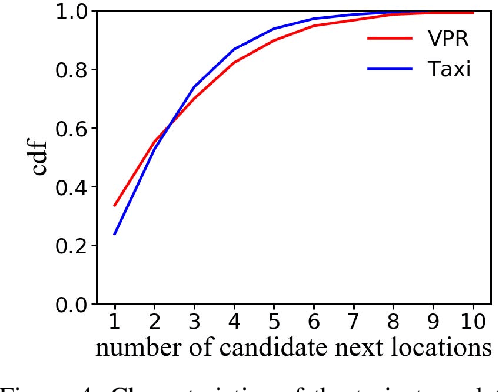
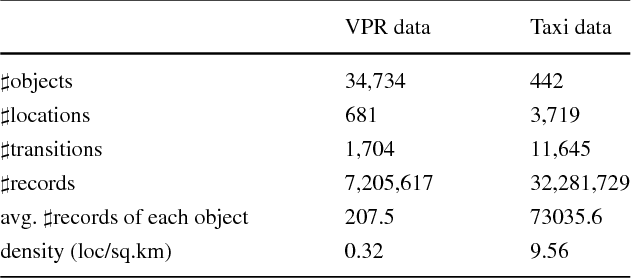
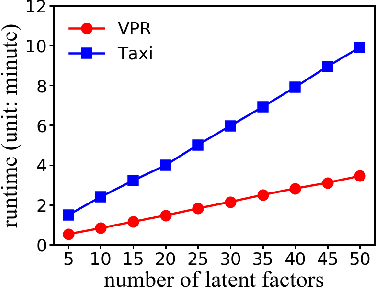
Next location prediction is of great importance for many location-based applications and provides essential intelligence to business and governments. In existing studies, a common approach to next location prediction is to learn the sequential transitions with massive historical trajectories based on conditional probability. Unfortunately, due to the time and space complexity, these methods (e.g., Markov models) only use the just passed locations to predict next locations, without considering all the passed locations in the trajectory. In this paper, we seek to enhance the prediction performance by considering the travel time from all the passed locations in the query trajectory to a candidate next location. In particular, we propose a novel method, called Travel Time Difference Model (TTDM), which exploits the difference between the shortest travel time and the actual travel time to predict next locations. Further, we integrate the TTDM with a Markov model via a linear interpolation to yield a joint model, which computes the probability of reaching each possible next location and returns the top-rankings as results. We have conducted extensive experiments on two real datasets: the vehicle passage record (VPR) data and the taxi trajectory data. The experimental results demonstrate significant improvements in prediction accuracy over existing solutions. For example, compared with the Markov model, the top-1 accuracy improves by 40% on the VPR data and by 15.6% on the Taxi data.
TraLFM: Latent Factor Modeling of Traffic Trajectory Data
Mar 16, 2020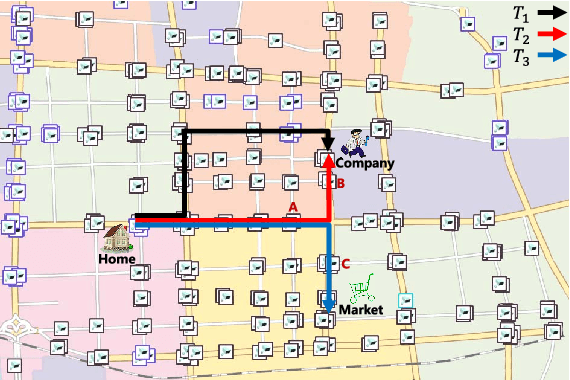
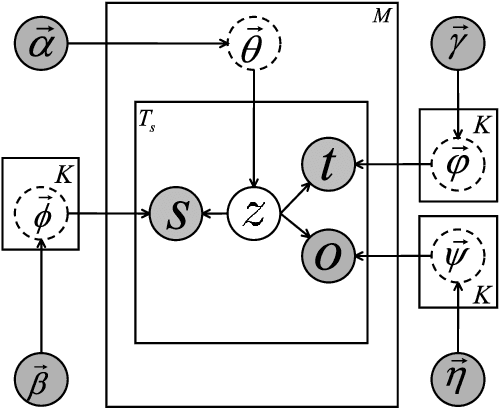

The widespread use of positioning devices (e.g., GPS) has given rise to a vast body of human movement data, often in the form of trajectories. Understanding human mobility patterns could benefit many location-based applications. In this paper, we propose a novel generative model called TraLFM via latent factor modeling to mine human mobility patterns underlying traffic trajectories. TraLFM is based on three key observations: (1) human mobility patterns are reflected by the sequences of locations in the trajectories; (2) human mobility patterns vary with people; and (3) human mobility patterns tend to be cyclical and change over time. Thus, TraLFM models the joint action of sequential, personal and temporal factors in a unified way, and brings a new perspective to many applications such as latent factor analysis and next location prediction. We perform thorough empirical studies on two real datasets, and the experimental results confirm that TraLFM outperforms the state-of-the-art methods significantly in these applications.
Evaluating Temporal Queries Over Video Feeds
Mar 05, 2020
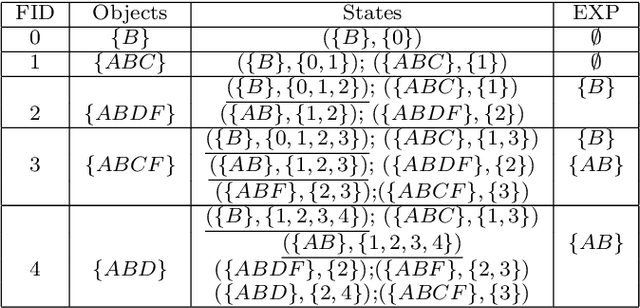
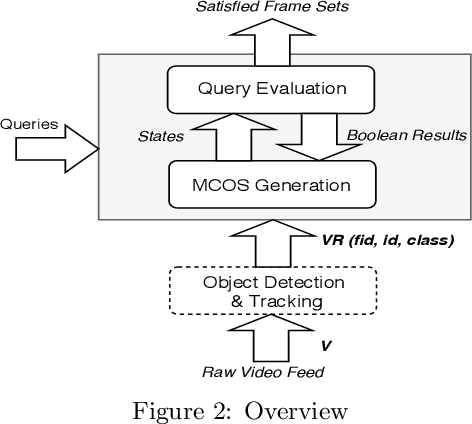
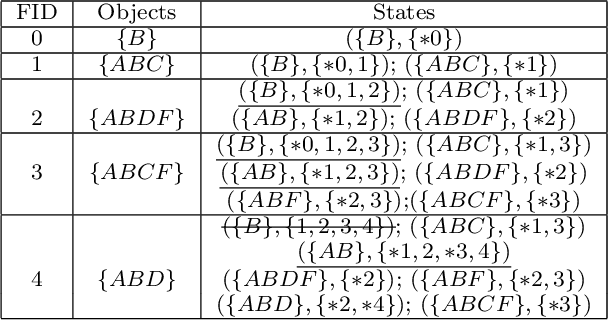
Recent advances in Computer Vision and Deep Learning made possible the efficient extraction of a schema from frames of streaming video. As such, a stream of objects and their associated classes along with unique object identifiers derived via object tracking can be generated, providing unique objects as they are captured across frames. In this paper we initiate a study of temporal queries involving objects and their co-occurrences in video feeds. For example, queries that identify video segments during which the same two red cars and the same two humans appear jointly for five minutes are of interest to many applications ranging from law enforcement to security and safety. We take the first step and define such queries in a way that they incorporate certain physical aspects of video capture such as object occlusion. We present an architecture consisting of three layers, namely object detection/tracking, intermediate data generation and query evaluation. We propose two techniques,MFS and SSG, to organize all detected objects in the intermediate data generation layer, which effectively, given the queries, minimizes the number of objects and frames that have to be considered during query evaluation. We also introduce an algorithm called State Traversal (ST) that processes incoming frames against the SSG and efficiently prunes objects and frames unrelated to query evaluation, while maintaining all states required for succinct query evaluation. We present the results of a thorough experimental evaluation utilizing both real and synthetic data establishing the trade-offs between MFS and SSG. We stress various parameters of interest in our evaluation and demonstrate that the proposed query evaluation methodology coupled with the proposed algorithms is capable to evaluate temporal queries over video feeds efficiently, achieving orders of magnitude performance benefits.