 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMIRAM: Masked Image Reconstruction Across Multiple Scales for Breast Lesion Risk Prediction
Mar 10, 2025Self-supervised learning (SSL) has garnered substantial interest within the machine learning and computer vision communities. Two prominent approaches in SSL include contrastive-based learning and self-distillation utilizing cropping augmentation. Lately, masked image modeling (MIM) has emerged as a more potent SSL technique, employing image inpainting as a pretext task. MIM creates a strong inductive bias toward meaningful spatial and semantic understanding. This has opened up new opportunities for SSL to contribute not only to classification tasks but also to more complex applications like object detection and image segmentation. Building upon this progress, our research paper introduces a scalable and practical SSL approach centered around more challenging pretext tasks that facilitate the acquisition of robust features. Specifically, we leverage multi-scale image reconstruction from randomly masked input images as the foundation for feature learning. Our hypothesis posits that reconstructing high-resolution images enables the model to attend to finer spatial details, particularly beneficial for discerning subtle intricacies within medical images. The proposed SSL features help improve classification performance on the Curated Breast Imaging Subset of Digital Database for Screening Mammography (CBIS-DDSM) dataset. In pathology classification, our method demonstrates a 3\% increase in average precision (AP) and a 1\% increase in the area under the receiver operating characteristic curve (AUC) when compared to state-of-the-art (SOTA) algorithms. Moreover, in mass margins classification, our approach achieves a 4\% increase in AP and a 2\% increase in AUC.
Revisiting Invariant Learning for Out-of-Domain Generalization on Multi-Site Mammogram Datasets
Mar 09, 2025Despite significant progress in robust deep learning techniques for mammogram breast cancer classification, their reliability in real-world clinical development settings remains uncertain. The translation of these models to clinical practice faces challenges due to variations in medical centers, imaging protocols, and patient populations. To enhance their robustness, invariant learning methods have been proposed, prioritizing causal factors over misleading features. However, their effectiveness in clinical development and impact on mammogram classification require investigation. This paper reassesses the application of invariant learning for breast cancer risk estimation based on mammograms. Utilizing diverse multi-site public datasets, it represents the first study in this area. The objective is to evaluate invariant learning's benefits in developing robust models. Invariant learning methods, including Invariant Risk Minimization and Variance Risk Extrapolation, are compared quantitatively against Empirical Risk Minimization. Evaluation metrics include accuracy, average precision, and area under the curve. Additionally, interpretability is examined through class activation maps and visualization of learned representations. This research examines the advantages, limitations, and challenges of invariant learning for mammogram classification, guiding future studies to develop generalized methods for breast cancer prediction on whole mammograms in out-of-domain scenarios.
Enhancing Parameter-Efficient Fine-Tuning of Vision Transformers through Frequency-Based Adaptation
Nov 28, 2024



Adapting vision transformer foundation models through parameter-efficient fine-tuning (PEFT) methods has become increasingly popular. These methods optimize a limited subset of parameters, enabling efficient adaptation without the need to fine-tune the entire model while still achieving competitive performance. However, traditional PEFT methods may limit the model's capacity to capture complex patterns, especially those associated with high-frequency spectra. This limitation becomes particularly problematic as existing research indicates that high-frequency features are crucial for distinguishing subtle image structures. To address this issue, we introduce FreqFit, a novel Frequency Fine-tuning module between ViT blocks to enhance model adaptability. FreqFit is simple yet surprisingly effective, and can be integrated with all existing PEFT methods to boost their performance. By manipulating features in the frequency domain, our approach allows models to capture subtle patterns more effectively. Extensive experiments on 24 datasets, using both supervised and self-supervised foundational models with various state-of-the-art PEFT methods, reveal that FreqFit consistently improves performance over the original PEFT methods with performance gains ranging from 1% to 16%. For instance, FreqFit-LoRA surpasses the performances of state-of-the-art baselines on CIFAR100 by more than 10% even without applying regularization or strong augmentation. For reproducibility purposes, the source code is available at https://github.com/tsly123/FreqFiT.
Segmentation of diagnostic tissue compartments on whole slide images with renal thrombotic microangiopathies (TMAs)
Nov 28, 2023



The thrombotic microangiopathies (TMAs) manifest in renal biopsy histology with a broad spectrum of acute and chronic findings. Precise diagnostic criteria for a renal biopsy diagnosis of TMA are missing. As a first step towards a machine learning- and computer vision-based analysis of wholes slide images from renal biopsies, we trained a segmentation model for the decisive diagnostic kidney tissue compartments artery, arteriole, glomerulus on a set of whole slide images from renal biopsies with TMAs and Mimickers (distinct diseases with a similar nephropathological appearance as TMA like severe benign nephrosclerosis, various vasculitides, Bevacizumab-plug glomerulopathy, arteriolar light chain deposition disease). Our segmentation model combines a U-Net-based tissue detection with a Shifted windows-transformer architecture to reach excellent segmentation results for even the most severely altered glomeruli, arterioles and arteries, even on unseen staining domains from a different nephropathology lab. With accurate automatic segmentation of the decisive renal biopsy compartments in human renal vasculopathies, we have laid the foundation for large-scale compartment-specific machine learning and computer vision analysis of renal biopsy repositories with TMAs.
Student Collaboration Improves Self-Supervised Learning: Dual-Loss Adaptive Masked Autoencoder for Brain Cell Image Analysis
May 10, 2022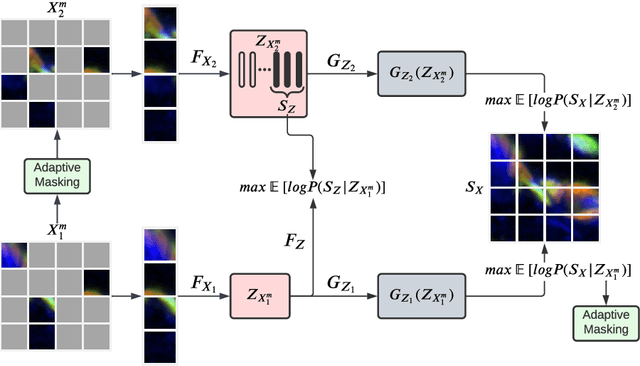
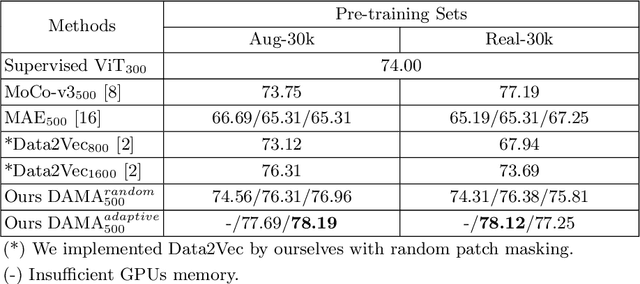
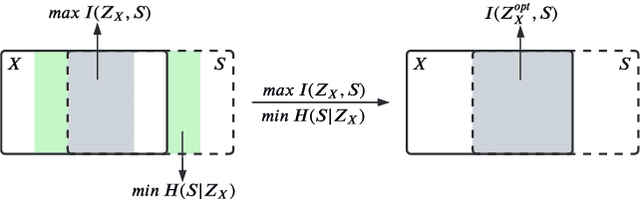
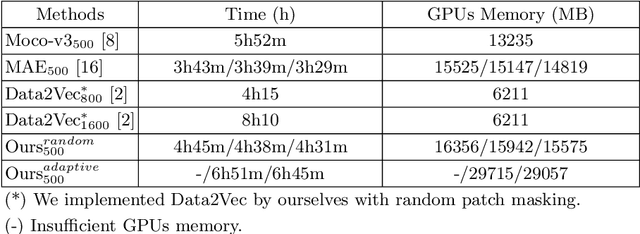
Self-supervised learning leverages the underlying data structure as the source of the supervisory signal without the need for human annotation effort. This approach offers a practical solution to learning with a large amount of biomedical data and limited annotation. Unlike other studies exploiting data via multi-view (e.g., augmented images), this study presents a self-supervised Dual-Loss Adaptive Masked Autoencoder (DAMA) algorithm established from the viewpoint of the information theory. Specifically, our objective function maximizes the mutual information by minimizing the conditional entropy in pixel-level reconstruction and feature-level regression. We further introduce an adaptive mask sampling strategy to maximize mutual information. We conduct extensive experiments on brain cell images to validate the proposed method. DAMA significantly outperforms both state-of-the-art self-supervised and supervised methods on brain cells data and demonstrates competitive result on ImageNet-1k. Code: https://github.com/hula-ai/DAMA
Multimodal Breast Lesion Classification Using Cross-Attention Deep Networks
Aug 21, 2021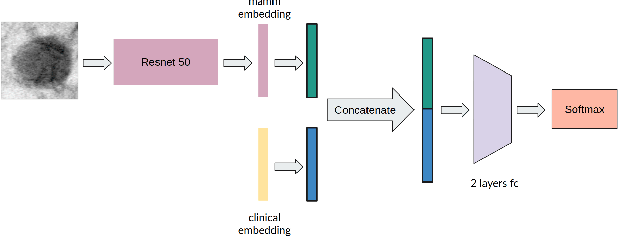
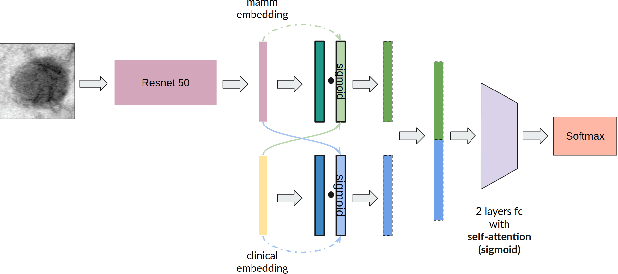
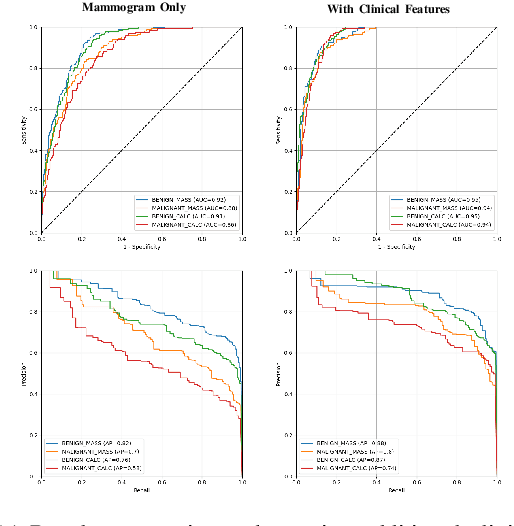

Accurate breast lesion risk estimation can significantly reduce unnecessary biopsies and help doctors decide optimal treatment plans. Most existing computer-aided systems rely solely on mammogram features to classify breast lesions. While this approach is convenient, it does not fully exploit useful information in clinical reports to achieve the optimal performance. Would clinical features significantly improve breast lesion classification compared to using mammograms alone? How to handle missing clinical information caused by variation in medical practice? What is the best way to combine mammograms and clinical features? There is a compelling need for a systematic study to address these fundamental questions. This paper investigates several multimodal deep networks based on feature concatenation, cross-attention, and co-attention to combine mammograms and categorical clinical variables. We show that the proposed architectures significantly increase the lesion classification performance (average area under ROC curves from 0.89 to 0.94). We also evaluate the model when clinical variables are missing.
Deep reinforcement learning in medical imaging: A literature review
Mar 05, 2021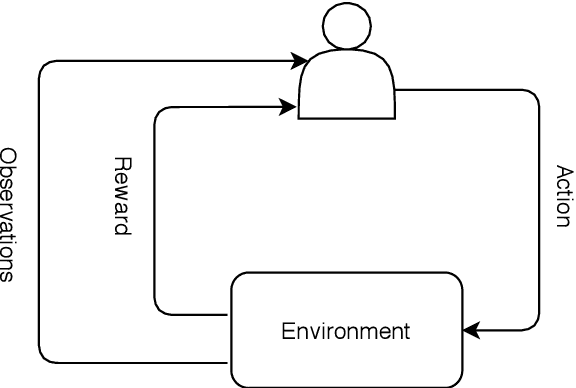
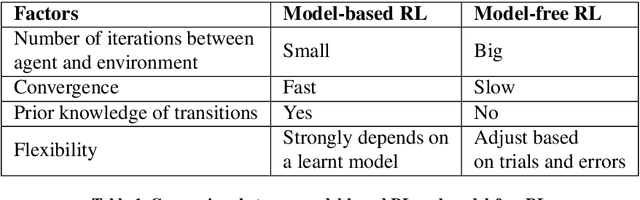

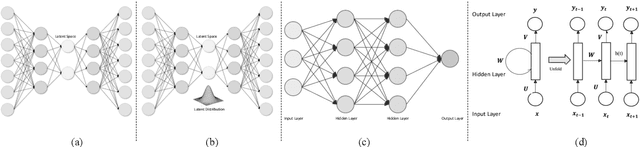
Deep reinforcement learning (DRL) augments the reinforcement learning framework, which learns a sequence of actions that maximizes the expected reward, with the representative power of deep neural networks. Recent works have demonstrated the great potential of DRL in medicine and healthcare. This paper presents a literature review of DRL in medical imaging. We start with a comprehensive tutorial of DRL, including the latest model-free and model-based algorithms. We then cover existing DRL applications for medical imaging, which are roughly divided into three main categories: (I) parametric medical image analysis tasks including landmark detection, object/lesion detection, registration, and view plane localization; (ii) solving optimization tasks including hyperparameter tuning, selecting augmentation strategies, and neural architecture search; and (iii) miscellaneous applications including surgical gesture segmentation, personalized mobile health intervention, and computational model personalization. The paper concludes with discussions of future perspectives.
DropConnect Is Effective in Modeling Uncertainty of Bayesian Deep Networks
Jun 07, 2019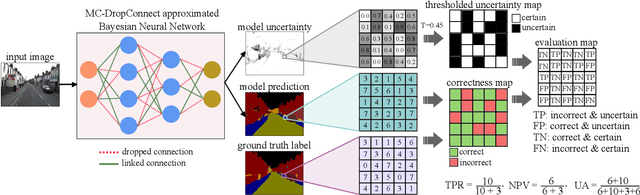
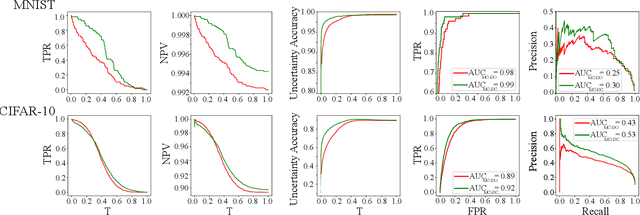

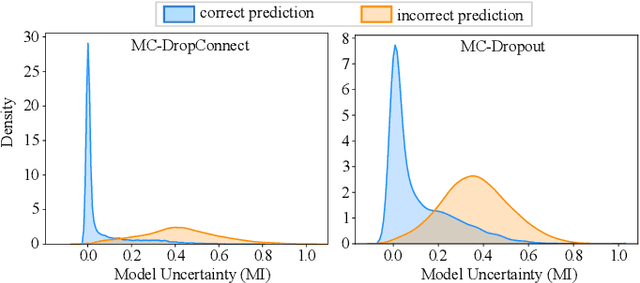
Deep neural networks (DNNs) have achieved state-of-the-art performances in many important domains, including medical diagnosis, security, and autonomous driving. In these domains where safety is highly critical, an erroneous decision can result in serious consequences. While a perfect prediction accuracy is not always achievable, recent work on Bayesian deep networks shows that it is possible to know when DNNs are more likely to make mistakes. Knowing what DNNs do not know is desirable to increase the safety of deep learning technology in sensitive applications. Bayesian neural networks attempt to address this challenge. However, traditional approaches are computationally intractable and do not scale well to large, complex neural network architectures. In this paper, we develop a theoretical framework to approximate Bayesian inference for DNNs by imposing a Bernoulli distribution on the model weights. This method, called MC-DropConnect, gives us a tool to represent the model uncertainty with little change in the overall model structure or computational cost. We extensively validate the proposed algorithm on multiple network architectures and datasets for classification and semantic segmentation tasks. We also propose new metrics to quantify the uncertainty estimates. This enables an objective comparison between MC-DropConnect and prior approaches. Our empirical results demonstrate that the proposed framework yields significant improvement in both prediction accuracy and uncertainty estimation quality compared to the state of the art.