 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePatcher: Patch Transformers with Mixture of Experts for Precise Medical Image Segmentation
Jun 03, 2022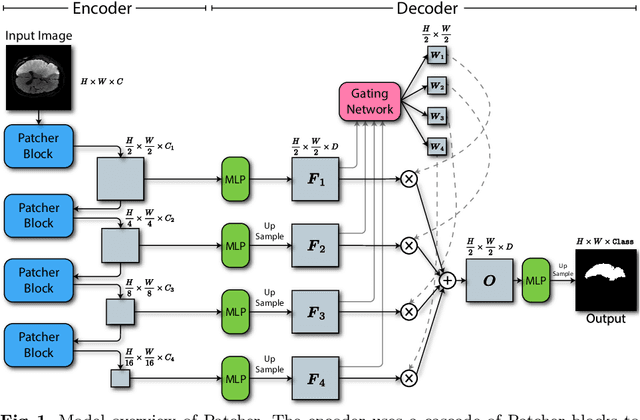
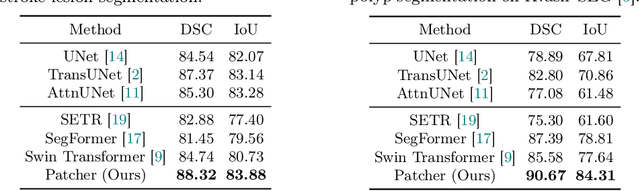


We present a new encoder-decoder Vision Transformer architecture, Patcher, for medical image segmentation. Unlike standard Vision Transformers, it employs Patcher blocks that segment an image into large patches, each of which is further divided into small patches. Transformers are applied to the small patches within a large patch, which constrains the receptive field of each pixel. We intentionally make the large patches overlap to enhance intra-patch communication. The encoder employs a cascade of Patcher blocks with increasing receptive fields to extract features from local to global levels. This design allows Patcher to benefit from both the coarse-to-fine feature extraction common in CNNs and the superior spatial relationship modeling of Transformers. We also propose a new mixture-of-experts (MoE) based decoder, which treats the feature maps from the encoder as experts and selects a suitable set of expert features to predict the label for each pixel. The use of MoE enables better specializations of the expert features and reduces interference between them during inference. Extensive experiments demonstrate that Patcher outperforms state-of-the-art Transformer- and CNN-based approaches significantly on stroke lesion segmentation and polyp segmentation. Code for Patcher will be released with publication to facilitate future research.
LambdaUNet: 2.5D Stroke Lesion Segmentation of Diffusion-weighted MR Images
Apr 28, 2021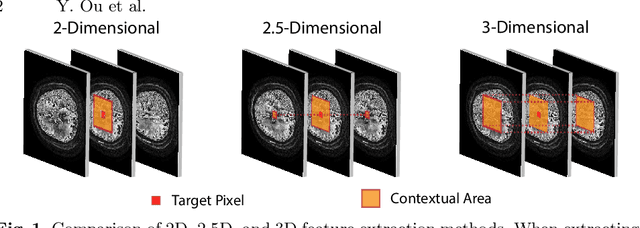
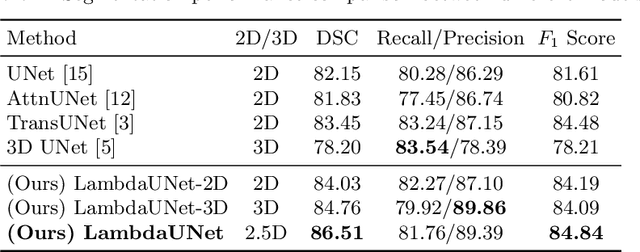


Diffusion-weighted (DW) magnetic resonance imaging is essential for the diagnosis and treatment of ischemic stroke. DW images (DWIs) are usually acquired in multi-slice settings where lesion areas in two consecutive 2D slices are highly discontinuous due to large slice thickness and sometimes even slice gaps. Therefore, although DWIs contain rich 3D information, they cannot be treated as regular 3D or 2D images. Instead, DWIs are somewhere in-between (or 2.5D) due to the volumetric nature but inter-slice discontinuities. Thus, it is not ideal to apply most existing segmentation methods as they are designed for either 2D or 3D images. To tackle this problem, we propose a new neural network architecture tailored for segmenting highly-discontinuous 2.5D data such as DWIs. Our network, termed LambdaUNet, extends UNet by replacing convolutional layers with our proposed Lambda+ layers. In particular, Lambda+ layers transform both intra-slice and inter-slice context around a pixel into linear functions, called lambdas, which are then applied to the pixel to produce informative 2.5D features. LambdaUNet is simple yet effective in combining sparse inter-slice information from adjacent slices while also capturing dense contextual features within a single slice. Experiments on a unique clinical dataset demonstrate that LambdaUNet outperforms existing 3D/2D image segmentation methods including recent variants of UNet. Code for LambdaUNet will be released with the publication to facilitate future research.
Epsilon Consistent Mixup: An Adaptive Consistency-Interpolation Tradeoff
Apr 19, 2021
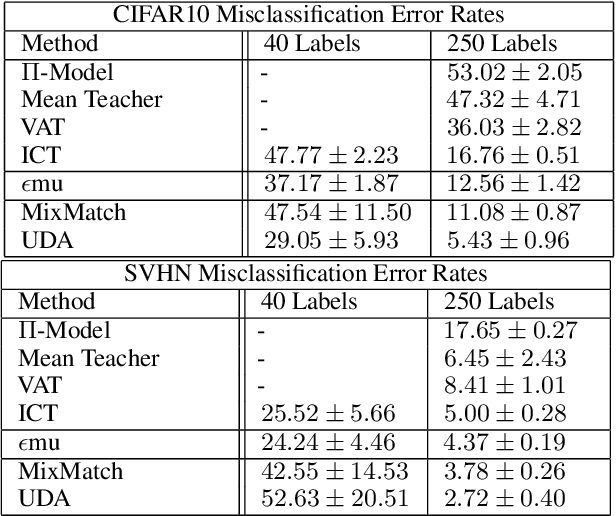

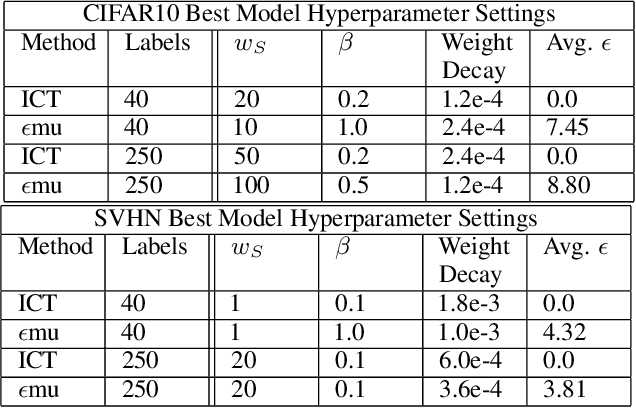
In this paper we propose $\epsilon$-Consistent Mixup ($\epsilon$mu). $\epsilon$mu is a data-based structural regularization technique that combines Mixup's linear interpolation with consistency regularization in the Mixup direction, by compelling a simple adaptive tradeoff between the two. This learnable combination of consistency and interpolation induces a more flexible structure on the evolution of the response across the feature space and is shown to improve semi-supervised classification accuracy on the SVHN and CIFAR10 benchmark datasets, yielding the largest gains in the most challenging low label-availability scenarios. Empirical studies comparing $\epsilon$mu and Mixup are presented and provide insight into the mechanisms behind $\epsilon$mu's effectiveness. In particular, $\epsilon$mu is found to produce more accurate synthetic labels and more confident predictions than Mixup.
AgentFormer: Agent-Aware Transformers for Socio-Temporal Multi-Agent Forecasting
Mar 25, 2021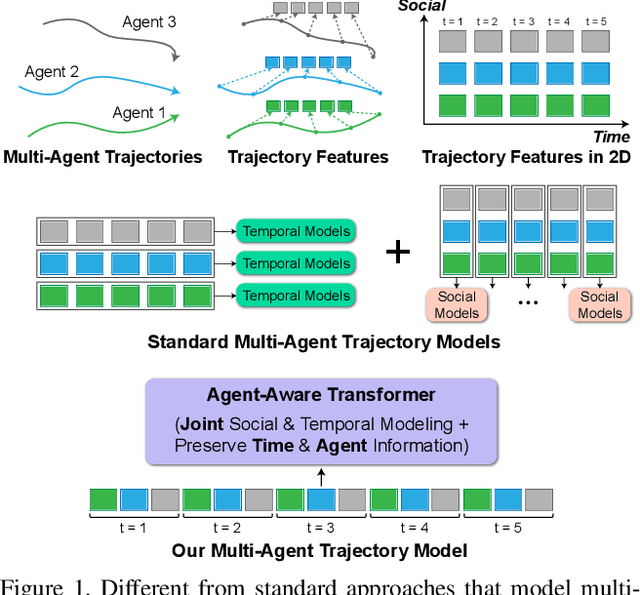
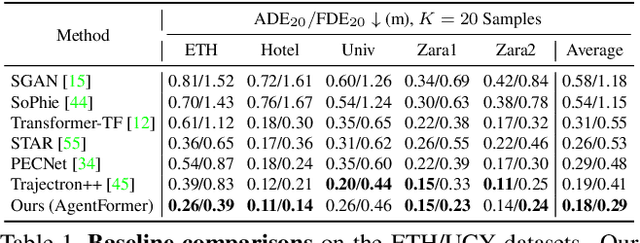
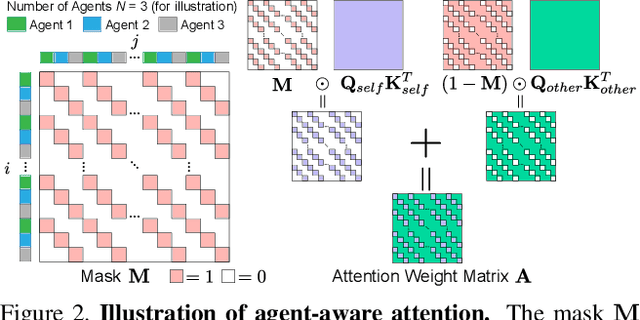
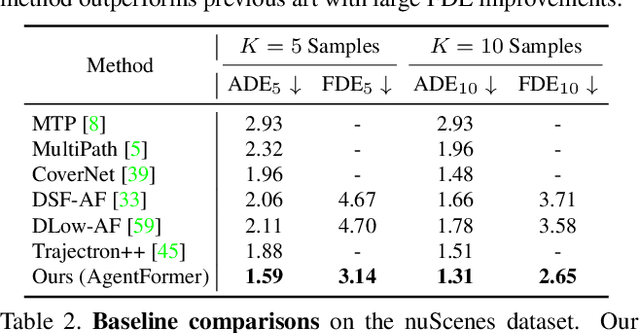
Predicting accurate future trajectories of multiple agents is essential for autonomous systems, but is challenging due to the complex agent interaction and the uncertainty in each agent's future behavior. Forecasting multi-agent trajectories requires modeling two key dimensions: (1) time dimension, where we model the influence of past agent states over future states; (2) social dimension, where we model how the state of each agent affects others. Most prior methods model these two dimensions separately; e.g., first using a temporal model to summarize features over time for each agent independently and then modeling the interaction of the summarized features with a social model. This approach is suboptimal since independent feature encoding over either the time or social dimension can result in a loss of information. Instead, we would prefer a method that allows an agent's state at one time to directly affect another agent's state at a future time. To this end, we propose a new Transformer, AgentFormer, that jointly models the time and social dimensions. The model leverages a sequence representation of multi-agent trajectories by flattening trajectory features across time and agents. Since standard attention operations disregard the agent identity of each element in the sequence, AgentFormer uses a novel agent-aware attention mechanism that preserves agent identities by attending to elements of the same agent differently than elements of other agents. Based on AgentFormer, we propose a stochastic multi-agent trajectory prediction model that can attend to features of any agent at any previous timestep when inferring an agent's future position. The latent intent of all agents is also jointly modeled, allowing the stochasticity in one agent's behavior to affect other agents. Our method significantly improves the state of the art on well-established pedestrian and autonomous driving datasets.
Semi-Supervised Cervical Dysplasia Classification With Learnable Graph Convolutional Network
Apr 01, 2020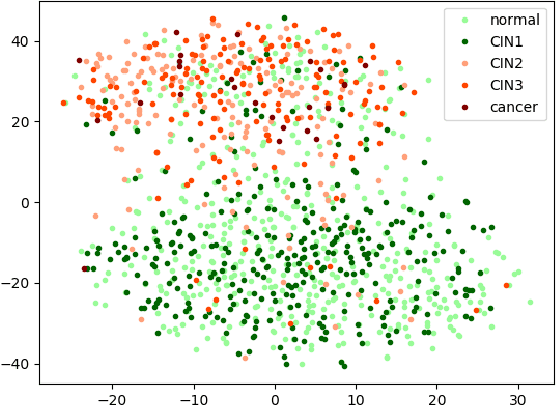

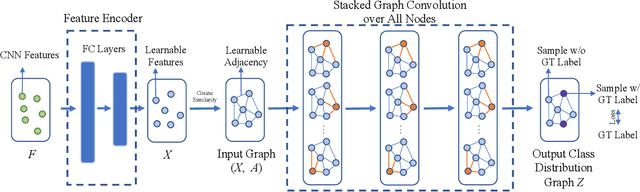
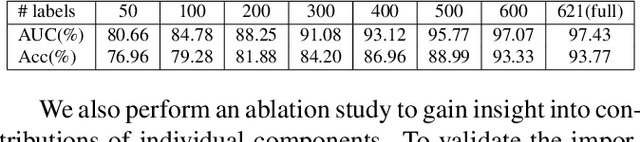
Cervical cancer is the second most prevalent cancer affecting women today. As the early detection of cervical carcinoma relies heavily upon screening and pre-clinical testing, digital cervicography has great potential as a primary or auxiliary screening tool, especially in low-resource regions due to its low cost and easy access. Although an automated cervical dysplasia detection system has been desirable, traditional fully-supervised training of such systems requires large amounts of annotated data which are often labor-intensive to collect. To alleviate the need for much manual annotation, we propose a novel graph convolutional network (GCN) based semi-supervised classification model that can be trained with fewer annotations. In existing GCNs, graphs are constructed with fixed features and can not be updated during the learning process. This limits their ability to exploit new features learned during graph convolution. In this paper, we propose a novel and more flexible GCN model with a feature encoder that adaptively updates the adjacency matrix during learning and demonstrate that this model design leads to improved performance. Our experimental results on a cervical dysplasia classification dataset show that the proposed framework outperforms previous methods under a semi-supervised setting, especially when the labeled samples are scarce.
Aspect Level Sentiment Classification with Attention-over-Attention Neural Networks
Apr 18, 2018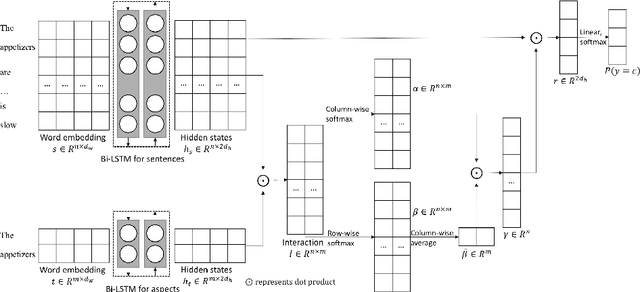
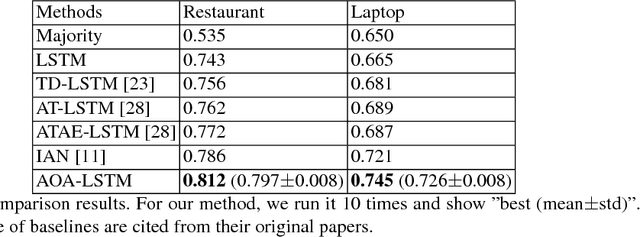
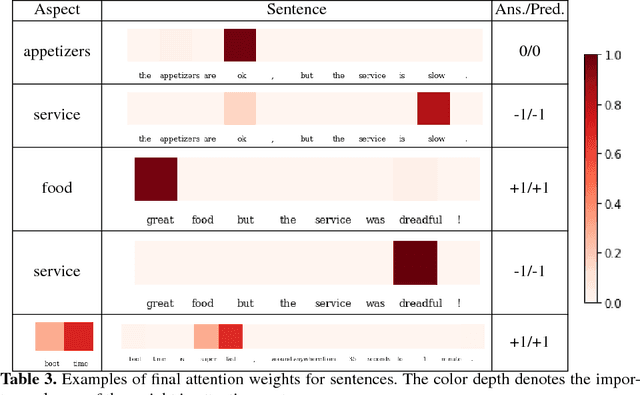
Aspect-level sentiment classification aims to identify the sentiment expressed towards some aspects given context sentences. In this paper, we introduce an attention-over-attention (AOA) neural network for aspect level sentiment classification. Our approach models aspects and sentences in a joint way and explicitly captures the interaction between aspects and context sentences. With the AOA module, our model jointly learns the representations for aspects and sentences, and automatically focuses on the important parts in sentences. Our experiments on laptop and restaurant datasets demonstrate our approach outperforms previous LSTM-based architectures.