 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLeveraging Multimodal Self-Consistency Reasoning in Coding Motivational Interviewing for Alcohol Use Reduction
May 13, 2026BACKGROUND: Coding Motivational Interviewing (MI) sessions is essential for understanding client behaviors and predicting outcomes, but it requires substantial time and labor from trained MI professionals. Recent advances in audio-language models (ALMs) offer new opportunities to automate MI coding by capturing multimodal behavioral signals. OBJECTIVE: This study aims to develop an automatic MI coding approach based on ALMs that analyzes raw audio input and integrates predictions from multiple reasoning trajectories using self-consistency to improve coding robustness. METHODS: We experimented with five recorded sessions from de-identified MI audio tapes. We deployed ALMs with four complementary analytic prompts to support utterance-level reasoning: analytic prompting for verbal cues, prosody-aware prompting for acoustic cues, evidence-scoring prompting for quantitative hypothesis testing, and comparative prompting for contrastive reasoning. Three stochastic samples were drawn for each prompt, generating 12 independent reasoning trajectories per utterance. Final predictions were determined by majority voting across all trajectories. RESULTS: Performance was evaluated using accuracy, precision, recall, and macro-F1 scores. The proposed multimodal self-consistency approach achieved 52.56% accuracy, 54.03% precision, 47.45% recall, and a macro-F1 score of 46.40%, exceeding baseline methods. Systematic ablation experiments that removed individual modules consistently degraded performance on the primary metrics. CONCLUSIONS: Multimodal self-consistency outperforms single-pass baseline prompting approaches for MI coding. These findings suggest that incorporating both what clients say and how they say it can support more reliable automatic MI coding.
What Makes Good Instruction-Tuning Data? An In-Context Learning Perspective
Apr 28, 2026Instruction-tuning datasets often contain substantial redundancy and low-quality samples, necessitating effective data selection methods. We propose an instruction data selection framework based on weighted in-context influence (wICI), which measures how effectively each candidate example reduces instruction-following difficulty for semantically related peers. Through systematic experiments, we address three key questions: what constitutes effective instruction tuning data from an in-context perspective, whether sample difficulty correlates with in-context influence, and how in-context influence translates to instruction tuning effectiveness. Experiments across multiple models and benchmarks demonstrate that our method consistently outperforms existing baselines under constrained data budgets, while empirically showing that sample difficulty negatively correlates with in-context influence.
Model-Agnostic Meta Learning for Class Imbalance Adaptation
Apr 20, 2026Class imbalance is a widespread challenge in NLP tasks, significantly hindering robust performance across diverse domains and applications. We introduce Hardness-Aware Meta-Resample (HAMR), a unified framework that adaptively addresses both class imbalance and data difficulty. HAMR employs bi-level optimizations to dynamically estimate instance-level weights that prioritize genuinely challenging samples and minority classes, while a neighborhood-aware resampling mechanism amplifies training focus on hard examples and their semantically similar neighbors. We validate HAMR on six imbalanced datasets covering multiple tasks and spanning biomedical, disaster response, and sentiment domains. Experimental results show that HAMR achieves substantial improvements for minority classes and consistently outperforms strong baselines. Extensive ablation studies demonstrate that our proposed modules synergistically contribute to performance gains and highlight HAMR as a flexible and generalizable approach for class imbalance adaptation. Code is available at https://github.com/trust-nlp/ImbalanceLearning.
BLUEmed: Retrieval-Augmented Multi-Agent Debate for Clinical Error Detection
Apr 12, 2026Terminology substitution errors in clinical notes, where one medical term is replaced by a linguistically valid but clinically different term, pose a persistent challenge for automated error detection in healthcare. We introduce BLUEmed, a multi-agent debate framework augmented with hybrid Retrieval-Augmented Generation (RAG) that combines evidence-grounded reasoning with multi-perspective verification for clinical error detection. BLUEmed decomposes each clinical note into focused sub-queries, retrieves source-partitioned evidence through dense, sparse, and online retrieval, and assigns two domain expert agents distinct knowledge bases to produce independent analyses; when the experts disagree, a structured counter-argumentation round and cross-source adjudication resolve the conflict, followed by a cascading safety layer that filters common false-positive patterns. We evaluate BLUEmed on a clinical terminology substitution detection benchmark under both zero-shot and few-shot prompting with multiple backbone models spanning proprietary and open-source families. Experimental results show that BLUEmed achieves the best accuracy (69.13%), ROC-AUC (74.45%), and PR-AUC (72.44%) under few-shot prompting, outperforming both single-agent RAG and debate-only baselines. Further analyses across six backbone models and two prompting strategies confirm that retrieval augmentation and structured debate are complementary, and that the framework benefits most from models with sufficient instruction-following and clinical language understanding.
From UAV Imagery to Agronomic Reasoning: A Multimodal LLM Benchmark for Plant Phenotyping
Apr 10, 2026To improve crop genetics, high-throughput, effective and comprehensive phenotyping is a critical prerequisite. While such tasks were traditionally performed manually, recent advances in multimodal foundation models, especially in vision-language models (VLMs), have enabled more automated and robust phenotypic analysis. However, plant science remains a particularly challenging domain for foundation models because it requires domain-specific knowledge, fine-grained visual interpretation, and complex biological and agronomic reasoning. To address this gap, we develop PlantXpert, an evidence-grounded multimodal reasoning benchmark for soybean and cotton phenotyping. Our benchmark provides a structured and reproducible framework for agronomic adaptation of VLMs, and enables controlled comparison between base models and their domain-adapted counterparts. We constructed a dataset comprising 385 digital images and more than 3,000 benchmark samples spanning key plant science domains including disease, pest control, weed management, and yield. The benchmark can assess diverse capabilities including visual expertise, quantitative reasoning, and multi-step agronomic reasoning. A total of 11 state-of-the-art VLMs were evaluated. The results indicate that task-specific fine-tuning leads to substantial improvement in accuracy, with models such as Qwen3-VL-4B and Qwen3-VL-30B achieving up to 78%. At the same time, gains from model scaling diminish beyond a certain capacity, generalization across soybean and cotton remains uneven, and quantitative as well as biologically grounded reasoning continue to pose substantial challenges. These findings suggest that PlantXpert can serve as a foundation for assessing evidence-grounded agronomic reasoning and for advancing multimodal model development in plant science.
InfinityStory: Unlimited Video Generation with World Consistency and Character-Aware Shot Transitions
Mar 04, 2026Generating long-form storytelling videos with consistent visual narratives remains a significant challenge in video synthesis. We present a novel framework, dataset, and a model that address three critical limitations: background consistency across shots, seamless multi-subject shot-to-shot transitions, and scalability to hour-long narratives. Our approach introduces a background-consistent generation pipeline that maintains visual coherence across scenes while preserving character identity and spatial relationships. We further propose a transition-aware video synthesis module that generates smooth shot transitions for complex scenarios involving multiple subjects entering or exiting frames, going beyond the single-subject limitations of prior work. To support this, we contribute with a synthetic dataset of 10,000 multi-subject transition sequences covering underrepresented dynamic scene compositions. On VBench, InfinityStory achieves the highest Background Consistency (88.94), highest Subject Consistency (82.11), and the best overall average rank (2.80), showing improved stability, smoother transitions, and better temporal coherence.
A Survey on Long-Video Storytelling Generation: Architectures, Consistency, and Cinematic Quality
Jul 09, 2025

Despite the significant progress that has been made in video generative models, existing state-of-the-art methods can only produce videos lasting 5-16 seconds, often labeled "long-form videos". Furthermore, videos exceeding 16 seconds struggle to maintain consistent character appearances and scene layouts throughout the narrative. In particular, multi-subject long videos still fail to preserve character consistency and motion coherence. While some methods can generate videos up to 150 seconds long, they often suffer from frame redundancy and low temporal diversity. Recent work has attempted to produce long-form videos featuring multiple characters, narrative coherence, and high-fidelity detail. We comprehensively studied 32 papers on video generation to identify key architectural components and training strategies that consistently yield these qualities. We also construct a comprehensive novel taxonomy of existing methods and present comparative tables that categorize papers by their architectural designs and performance characteristics.
Examining and Adapting Time for Multilingual Classification via Mixture of Temporal Experts
Feb 12, 2025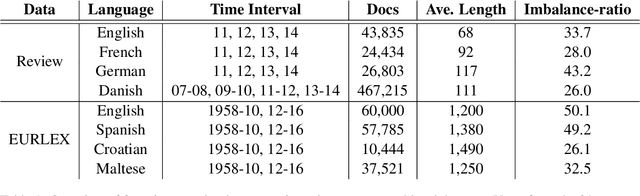
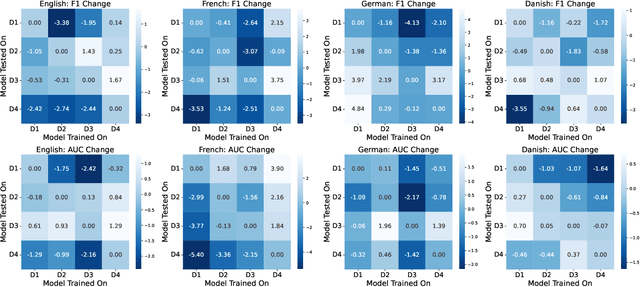
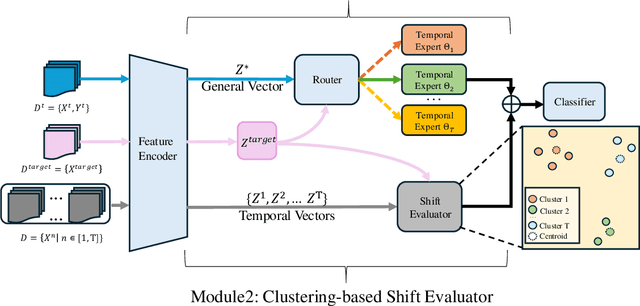
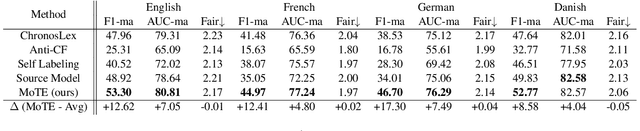
Time is implicitly embedded in classification process: classifiers are usually built on existing data while to be applied on future data whose distributions (e.g., label and token) may change. However, existing state-of-the-art classification models merely consider the temporal variations and primarily focus on English corpora, which leaves temporal studies less explored, let alone under multilingual settings. In this study, we fill the gap by treating time as domains (e.g., 2024 vs. 2025), examining temporal effects, and developing a domain adaptation framework to generalize classifiers over time on multiple languages. Our framework proposes Mixture of Temporal Experts (MoTE) to leverage both semantic and data distributional shifts to learn and adapt temporal trends into classification models. Our analysis shows classification performance varies over time across different languages, and we experimentally demonstrate that MoTE can enhance classifier generalizability over temporal data shifts. Our study provides analytic insights and addresses the need for time-aware models that perform robustly in multilingual scenarios.
Examining Imbalance Effects on Performance and Demographic Fairness of Clinical Language Models
Dec 23, 2024
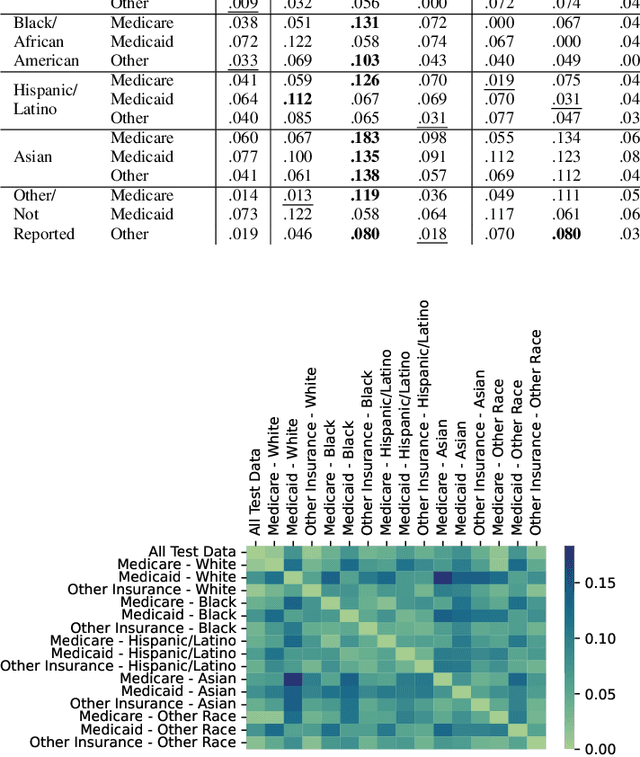
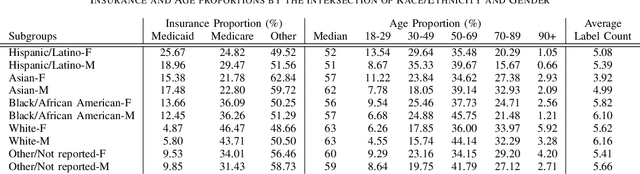
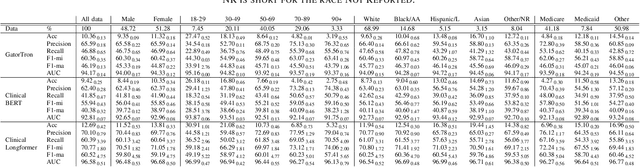
Data imbalance is a fundamental challenge in applying language models to biomedical applications, particularly in ICD code prediction tasks where label and demographic distributions are uneven. While state-of-the-art language models have been increasingly adopted in biomedical tasks, few studies have systematically examined how data imbalance affects model performance and fairness across demographic groups. This study fills the gap by statistically probing the relationship between data imbalance and model performance in ICD code prediction. We analyze imbalances in a standard benchmark data across gender, age, ethnicity, and social determinants of health by state-of-the-art biomedical language models. By deploying diverse performance metrics and statistical analyses, we explore the influence of data imbalance on performance variations and demographic fairness. Our study shows that data imbalance significantly impacts model performance and fairness, but feature similarity to the majority class may be a more critical factor. We believe this study provides valuable insights for developing more equitable and robust language models in healthcare applications.
Time Matters: Examine Temporal Effects on Biomedical Language Models
Jul 24, 2024



Time roots in applying language models for biomedical applications: models are trained on historical data and will be deployed for new or future data, which may vary from training data. While increasing biomedical tasks have employed state-of-the-art language models, there are very few studies have examined temporal effects on biomedical models when data usually shifts across development and deployment. This study fills the gap by statistically probing relations between language model performance and data shifts across three biomedical tasks. We deploy diverse metrics to evaluate model performance, distance methods to measure data drifts, and statistical methods to quantify temporal effects on biomedical language models. Our study shows that time matters for deploying biomedical language models, while the degree of performance degradation varies by biomedical tasks and statistical quantification approaches. We believe this study can establish a solid benchmark to evaluate and assess temporal effects on deploying biomedical language models.