 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExamining and Adapting Time for Multilingual Classification via Mixture of Temporal Experts
Feb 12, 2025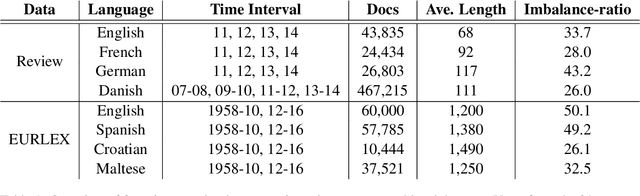
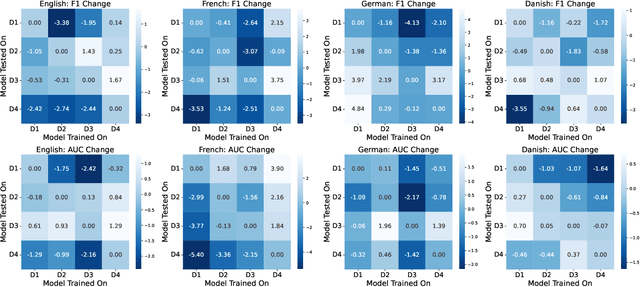
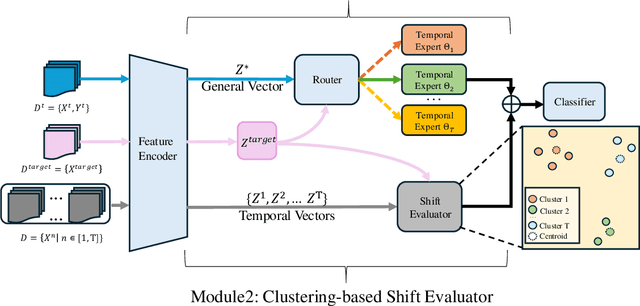
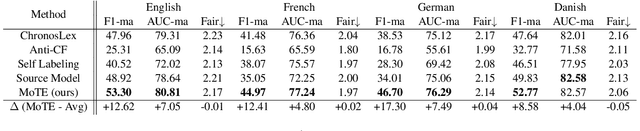
Time is implicitly embedded in classification process: classifiers are usually built on existing data while to be applied on future data whose distributions (e.g., label and token) may change. However, existing state-of-the-art classification models merely consider the temporal variations and primarily focus on English corpora, which leaves temporal studies less explored, let alone under multilingual settings. In this study, we fill the gap by treating time as domains (e.g., 2024 vs. 2025), examining temporal effects, and developing a domain adaptation framework to generalize classifiers over time on multiple languages. Our framework proposes Mixture of Temporal Experts (MoTE) to leverage both semantic and data distributional shifts to learn and adapt temporal trends into classification models. Our analysis shows classification performance varies over time across different languages, and we experimentally demonstrate that MoTE can enhance classifier generalizability over temporal data shifts. Our study provides analytic insights and addresses the need for time-aware models that perform robustly in multilingual scenarios.
Examining Imbalance Effects on Performance and Demographic Fairness of Clinical Language Models
Dec 23, 2024
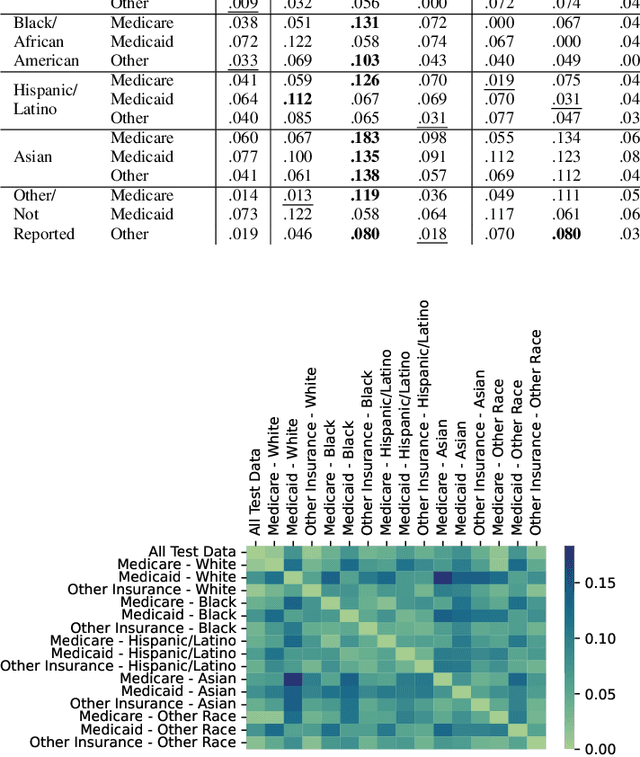
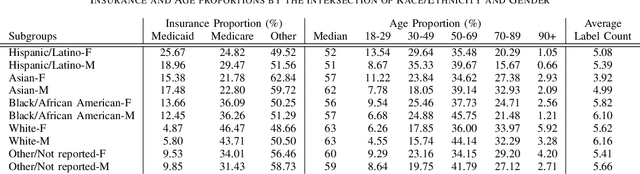
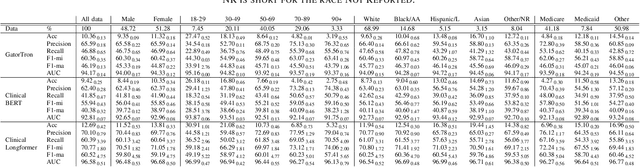
Data imbalance is a fundamental challenge in applying language models to biomedical applications, particularly in ICD code prediction tasks where label and demographic distributions are uneven. While state-of-the-art language models have been increasingly adopted in biomedical tasks, few studies have systematically examined how data imbalance affects model performance and fairness across demographic groups. This study fills the gap by statistically probing the relationship between data imbalance and model performance in ICD code prediction. We analyze imbalances in a standard benchmark data across gender, age, ethnicity, and social determinants of health by state-of-the-art biomedical language models. By deploying diverse performance metrics and statistical analyses, we explore the influence of data imbalance on performance variations and demographic fairness. Our study shows that data imbalance significantly impacts model performance and fairness, but feature similarity to the majority class may be a more critical factor. We believe this study provides valuable insights for developing more equitable and robust language models in healthcare applications.
Time Matters: Examine Temporal Effects on Biomedical Language Models
Jul 24, 2024



Time roots in applying language models for biomedical applications: models are trained on historical data and will be deployed for new or future data, which may vary from training data. While increasing biomedical tasks have employed state-of-the-art language models, there are very few studies have examined temporal effects on biomedical models when data usually shifts across development and deployment. This study fills the gap by statistically probing relations between language model performance and data shifts across three biomedical tasks. We deploy diverse metrics to evaluate model performance, distance methods to measure data drifts, and statistical methods to quantify temporal effects on biomedical language models. Our study shows that time matters for deploying biomedical language models, while the degree of performance degradation varies by biomedical tasks and statistical quantification approaches. We believe this study can establish a solid benchmark to evaluate and assess temporal effects on deploying biomedical language models.
Chain-of-Interaction: Enhancing Large Language Models for Psychiatric Behavior Understanding by Dyadic Contexts
Mar 23, 2024
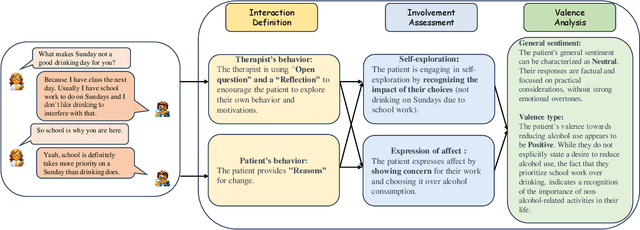


Automatic coding patient behaviors is essential to support decision making for psychotherapists during the motivational interviewing (MI), a collaborative communication intervention approach to address psychiatric issues, such as alcohol and drug addiction. While the behavior coding task has rapidly adapted machine learning to predict patient states during the MI sessions, lacking of domain-specific knowledge and overlooking patient-therapist interactions are major challenges in developing and deploying those models in real practice. To encounter those challenges, we introduce the Chain-of-Interaction (CoI) prompting method aiming to contextualize large language models (LLMs) for psychiatric decision support by the dyadic interactions. The CoI prompting approach systematically breaks down the coding task into three key reasoning steps, extract patient engagement, learn therapist question strategies, and integrates dyadic interactions between patients and therapists. This approach enables large language models to leverage the coding scheme, patient state, and domain knowledge for patient behavioral coding. Experiments on real-world datasets can prove the effectiveness and flexibility of our prompting method with multiple state-of-the-art LLMs over existing prompting baselines. We have conducted extensive ablation analysis and demonstrate the critical role of dyadic interactions in applying LLMs for psychotherapy behavior understanding.