 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExamining Imbalance Effects on Performance and Demographic Fairness of Clinical Language Models
Dec 23, 2024
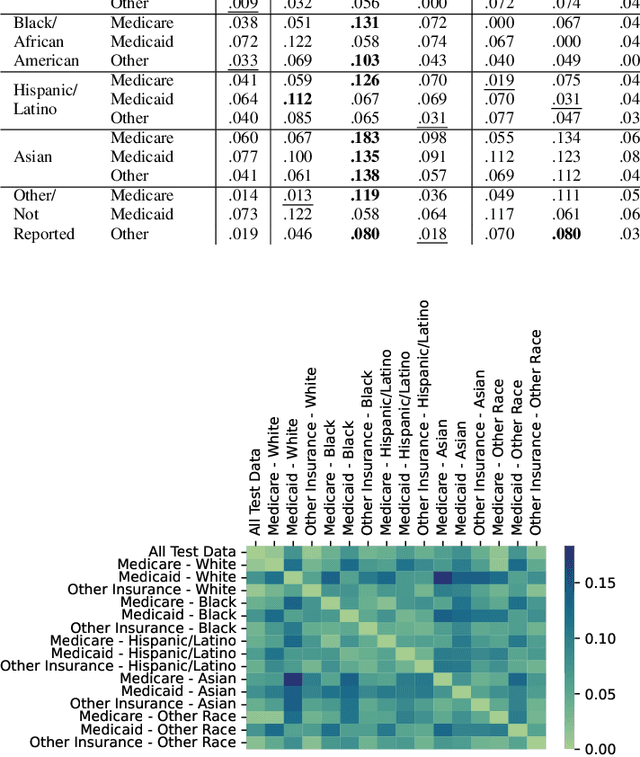
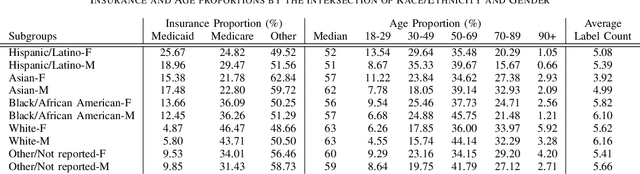
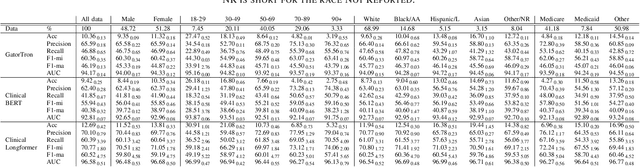
Data imbalance is a fundamental challenge in applying language models to biomedical applications, particularly in ICD code prediction tasks where label and demographic distributions are uneven. While state-of-the-art language models have been increasingly adopted in biomedical tasks, few studies have systematically examined how data imbalance affects model performance and fairness across demographic groups. This study fills the gap by statistically probing the relationship between data imbalance and model performance in ICD code prediction. We analyze imbalances in a standard benchmark data across gender, age, ethnicity, and social determinants of health by state-of-the-art biomedical language models. By deploying diverse performance metrics and statistical analyses, we explore the influence of data imbalance on performance variations and demographic fairness. Our study shows that data imbalance significantly impacts model performance and fairness, but feature similarity to the majority class may be a more critical factor. We believe this study provides valuable insights for developing more equitable and robust language models in healthcare applications.
Token Imbalance Adaptation for Radiology Report Generation
Apr 18, 2023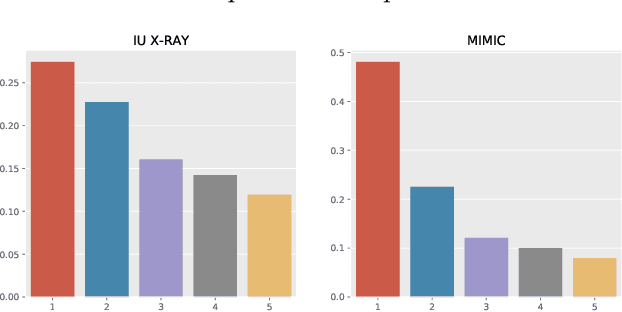
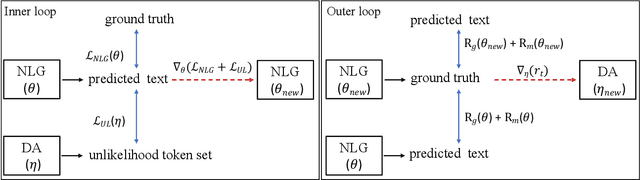
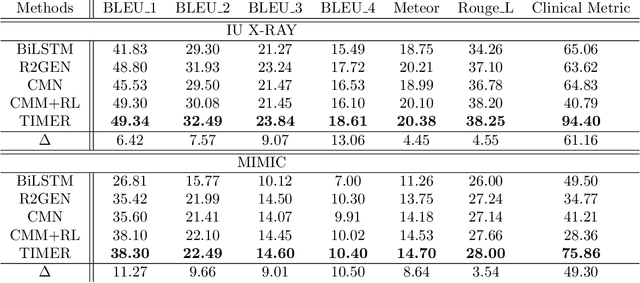
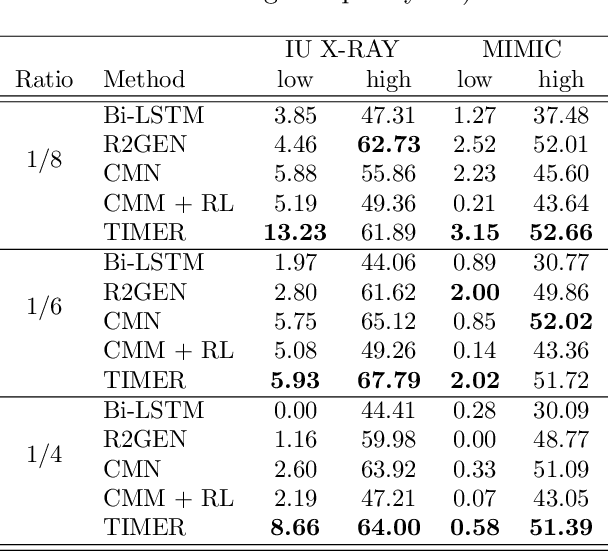
Imbalanced token distributions naturally exist in text documents, leading neural language models to overfit on frequent tokens. The token imbalance may dampen the robustness of radiology report generators, as complex medical terms appear less frequently but reflect more medical information. In this study, we demonstrate how current state-of-the-art models fail to generate infrequent tokens on two standard benchmark datasets (IU X-RAY and MIMIC-CXR) of radiology report generation. % However, no prior study has proposed methods to adapt infrequent tokens for text generators feeding with medical images. To solve the challenge, we propose the \textbf{T}oken \textbf{Im}balance Adapt\textbf{er} (\textit{TIMER}), aiming to improve generation robustness on infrequent tokens. The model automatically leverages token imbalance by an unlikelihood loss and dynamically optimizes generation processes to augment infrequent tokens. We compare our approach with multiple state-of-the-art methods on the two benchmarks. Experiments demonstrate the effectiveness of our approach in enhancing model robustness overall and infrequent tokens. Our ablation analysis shows that our reinforcement learning method has a major effect in adapting token imbalance for radiology report generation.